
Índice del contenido
¿Cómo impactan los sistemas distribuidos en la eficiencia operativa de una empresa moderna?
Imagine que dirige una empresa con operaciones en múltiples regiones, con miles de clientes que exigen respuestas inmediatas, sistemas financieros en tiempo real y una cadena de suministro que debe coordinar decenas de actores al mismo tiempo. Ahora piense en su infraestructura tecnológica tradicional, basada en un sistema centralizado que se convierte en un cuello de botella cada vez que aumenta la demanda. Ahí es donde entran en juego los sistemas distribuidos: son el corazón invisible que mantiene funcionando a las grandes corporaciones modernas con agilidad y precisión.
1. La eficiencia operativa como ventaja competitiva
En el mundo corporativo actual, la eficiencia no es solo un objetivo, es una necesidad para sobrevivir. Un sistema distribuido, al dividir las cargas de trabajo en múltiples nodos que operan en paralelo, permite procesar más datos en menos tiempo y con menor riesgo de interrupciones.
Por ejemplo, una empresa de retail global puede actualizar precios, procesar pagos y monitorear inventarios de manera simultánea en diferentes regiones sin sobrecargar un único servidor central. Para los directores de tecnología, esto significa menos tiempos muertos y más capacidad de respuesta a las necesidades del negocio.
2. Escalabilidad operativa: Crecer sin fricciones
Una de las principales barreras en la eficiencia operativa es la incapacidad de crecer sin que los costos se disparen. Con los sistemas distribuidos, la escalabilidad se vuelve casi orgánica: se pueden agregar nuevos nodos o servidores conforme la demanda lo requiera, sin alterar la operación global.
Piense en Amazon durante el Black Friday. Si su infraestructura no fuera distribuida, el aumento de tráfico podría colapsar el sistema entero. En cambio, cada nodo adicional que se suma absorbe parte de la carga de manera automática. Esto no solo mantiene la continuidad del servicio, sino que reduce significativamente los costos de infraestructura a largo plazo.
3. Reducción de tiempos de respuesta y satisfacción del cliente
Un director de RRHH podría preguntarse: “¿Qué tiene que ver esto con la eficiencia de mi equipo?”. La respuesta es simple: tiempo. Los sistemas distribuidos procesan peticiones más rápido porque el trabajo se reparte. En sectores como banca o e-commerce, cada milisegundo cuenta para la experiencia del cliente.
Tomemos el caso de una plataforma financiera: gracias a la distribución de procesos, las transferencias en línea se ejecutan en tiempo real, mejorando la percepción de confiabilidad y evitando que los clientes busquen alternativas en la competencia. Para los líderes gerenciales, esto se traduce en mayor retención y lealtad.
4. Mayor resiliencia y continuidad del negocio
Desde una perspectiva operativa, la resiliencia es eficiencia. Un sistema centralizado puede ser derribado por un simple fallo de hardware. En cambio, en un sistema distribuido, si un nodo falla, otros asumen su carga sin interrumpir las operaciones.
Esto es crítico en industrias como la salud o la aviación, donde la continuidad es literalmente cuestión de vida o muerte. Para un CEO o un CTO, garantizar esta continuidad no solo significa proteger ingresos, sino también cuidar la reputación corporativa ante clientes e inversores.
5. Optimización de recursos humanos y tecnológicos
Un punto que muchos directores de RRHH subestiman es cómo los sistemas distribuidos optimizan el trabajo de los equipos internos. Al automatizar procesos y distribuir cargas, los equipos de TI dedican menos tiempo a “apagar incendios” y más a innovar.
Imagine a su equipo técnico dejando de lidiar con caídas recurrentes del sistema para enfocarse en implementar nuevas funcionalidades que generen ingresos. Este cambio de enfoque no solo mejora la moral interna, sino que también aumenta la retención del talento tecnológico, un recurso cada vez más escaso.
6. Toma de decisiones más rápidas y basadas en datos en tiempo real
Los sistemas distribuidos no solo procesan datos rápidamente, sino que también los hacen accesibles en tiempo real a diferentes áreas del negocio. Para un director gerencial, tener visibilidad inmediata de lo que ocurre en cada unidad de negocio es oro puro.
Por ejemplo, una empresa de logística puede monitorear en tiempo real la ubicación de sus camiones, los niveles de combustible y la eficiencia de sus rutas. Con esa información, un gerente puede tomar decisiones correctivas en minutos, no en horas o días.
7. Impacto directo en los costos operativos
Aunque la inversión inicial en sistemas distribuidos puede parecer alta, su impacto a mediano plazo reduce costos:
Menos fallas = menos pérdidas por interrupciones.
Escalabilidad progresiva = pagar solo por los recursos que se usan.
Automatización de procesos = menos horas hombre en tareas repetitivas.
Para un CFO, este argumento es crucial: un sistema distribuido bien gestionado no es un gasto, es una inversión estratégica que genera retorno.
8. Storytelling Gerencial: El caso de éxito
Déjeme contarle el caso de Laura, directora de tecnología en una empresa de retail con más de 200 tiendas físicas y una creciente presencia online. Antes de implementar sistemas distribuidos, sus reportes de inventario tardaban hasta 24 horas en consolidarse, generando quiebres de stock y clientes insatisfechos.
Después de migrar a una arquitectura distribuida, la información se actualiza cada 10 minutos, lo que permitió ajustar pedidos de manera automática y reducir las pérdidas en un 30%. Laura no solo optimizó la operación; se ganó un lugar en la mesa directiva como impulsora de innovación.
9. Conclusión persuasiva
En un mundo hipercompetitivo, la eficiencia operativa ya no es opcional. Los sistemas distribuidos son mucho más que tecnología: son un habilitador estratégico que permite a las empresas modernas responder más rápido, gastar menos y mantenerse siempre disponibles.
Para los líderes gerenciales, adoptar esta arquitectura no es solo una decisión técnica, sino una apuesta por el futuro del negocio.
¿Qué métricas deben seguir los directores de tecnología para evaluar el rendimiento de un sistema distribuido?
En la alta gerencia, se repite constantemente una frase: “Lo que no se mide, no se puede mejorar”. En el caso de los sistemas distribuidos, esta verdad adquiere una relevancia crítica. Para un director de tecnología (CTO) o un gerente general, conocer las métricas correctas no es un lujo técnico: es la diferencia entre una infraestructura que impulsa la competitividad o una que se convierte en un agujero negro de recursos. Los sistemas distribuidos, por su propia naturaleza, son complejos: múltiples nodos, bases de datos replicadas, servicios que interactúan entre sí y usuarios que exigen respuestas inmediatas. Por lo tanto, evaluar su rendimiento requiere métricas específicas que ofrezcan una visión integral, predictiva y accionable. A continuación, analizaremos las métricas clave que un directivo debe exigir a su equipo técnico para garantizar que su inversión en sistemas distribuidos genere resultados reales en la operación del negocio. 1. Latencia: el pulso de la experiencia del usuario La latencia es el tiempo que tarda un sistema en responder a una solicitud. Para el cliente final, representa la rapidez con la que obtiene un resultado; para el negocio, se traduce en satisfacción, conversión y lealtad. Por qué es crítica: en sectores como e-commerce o banca, una latencia alta puede significar pérdidas millonarias. Amazon ha calculado que cada 100 milisegundos de retraso puede costar un 1% en ventas. Métrica clave: tiempo de respuesta promedio (p95 y p99, que miden el 95% y 99% de las solicitudes más lentas). Interpretación gerencial: si su CTO le muestra una latencia por debajo de 200 ms en operaciones críticas, está en la zona óptima; si supera los 500 ms, la experiencia de usuario está en riesgo. 2. Throughput: capacidad de procesamiento real del sistema El throughput indica cuántas operaciones o transacciones procesa el sistema en un período de tiempo. Por qué es importante: es la métrica que refleja la verdadera capacidad operativa. Un throughput bajo en sistemas distribuidos indica cuellos de botella, incluso si la latencia promedio parece aceptable. Ejemplo práctico: en una fintech, un throughput de 10,000 transacciones por segundo puede ser el umbral mínimo para soportar picos durante fechas de alta demanda. Visión gerencial: el throughput debe alinearse con los objetivos comerciales. Si la empresa proyecta duplicar su base de clientes, el sistema debe anticiparse a ese crecimiento. 3. Disponibilidad (Uptime): la métrica que protege ingresos Un sistema distribuido tiene como promesa básica estar siempre disponible. Para medirlo, se utiliza el uptime, es decir, el porcentaje de tiempo en que el sistema está operativo. Estándar de oro: 99.999% (conocido como “five nines”), lo que representa solo 5 minutos de caída al año. Implicación gerencial: cada minuto de inactividad en una aerolínea o en una bolsa de valores puede costar cientos de miles de dólares. Un CTO debe garantizar acuerdos de nivel de servicio (SLA) que se acerquen a ese estándar. 4. Tasa de errores (Error Rate): la salud invisible del sistema Un sistema puede estar “funcionando” pero devolviendo errores en segundo plano. Por eso, medir la tasa de errores (errores por cada mil solicitudes) es indispensable. Alerta gerencial: un error rate superior al 1% en operaciones críticas debe encender alarmas inmediatas. Ejemplo real: en una empresa logística, una tasa de errores en el cálculo de rutas puede traducirse en miles de entregas fallidas y pérdida de confianza en el servicio. 5. Consistencia de datos: confiabilidad en la toma de decisiones En sistemas distribuidos, los datos se replican en varios nodos. La consistencia mide qué tan sincronizados y precisos están estos datos en todo momento. Por qué es vital para la gerencia: decisiones estratégicas basadas en datos inconsistentes pueden provocar errores millonarios, como ordenar producción extra por inventarios mal sincronizados. Métrica técnica clave: lag de replicación (tiempo que tarda un nodo secundario en reflejar cambios del nodo primario). Valor ideal: lag cercano a cero o, en aplicaciones de alta criticidad, menor a 100 ms. 6. Costo por operación: la métrica financiera que importa al CFO Un sistema distribuido puede ser altamente eficiente técnicamente pero insostenible económicamente. Calcular el costo por operación o transacción procesada permite entender el retorno real de la inversión. Ejemplo: si el costo por transacción en un sistema financiero distribuido supera los 0.05 USD, el modelo puede no ser competitivo frente a otras plataformas. Visión estratégica: esta métrica une tecnología y negocio. Un CTO debe demostrar que cada dólar invertido en infraestructura genera ahorro o ingresos proporcionales. 7. Tiempo medio de detección (MTTD) y tiempo medio de resolución (MTTR) Estos dos indicadores son claves para evaluar la capacidad de respuesta ante incidentes: MTTD (Mean Time to Detect): cuánto tarda el sistema o el equipo en detectar un problema. MTTR (Mean Time to Repair): cuánto tarda en solucionarse. Estándares de referencia: MTTD ideal: minutos. MTTR ideal: menos de una hora en servicios críticos. Para la alta gerencia, esto se traduce en menos interrupciones visibles para el cliente y más confianza en la marca. 8. Observabilidad: la métrica de las métricas Más allá de cada indicador aislado, la observabilidad es la capacidad de entender el estado global del sistema en tiempo real. Un buen CTO debe presentar tableros que integren logs, métricas y trazas distribuidas en una única vista. Visión gerencial: no se trata solo de saber que algo falló, sino de anticiparse a los problemas antes de que impacten al cliente. 9. Storytelling: El CTO que transformó un caos en eficiencia Carlos, CTO de una empresa de telecomunicaciones, heredó un sistema distribuido caótico: los tiempos de respuesta superaban los 2 segundos, el uptime era del 97% y los costos operativos se disparaban. Implementó un panel de métricas centrado en latencia, throughput y MTTR. En seis meses, redujo el tiempo de respuesta a 150 ms, mejoró la disponibilidad al 99.99% y bajó el costo por transacción en un 40%. El cambio no solo fue técnico; le permitió a la empresa recuperar clientes perdidos y abrir nuevos mercados. 10. Conclusión persuasiva Para un director de tecnología o un gerente general, las métricas no son simples números: son el espejo de la salud del negocio. Medir y actuar sobre ellas significa garantizar eficiencia operativa, proteger ingresos y mantener la confianza de clientes e inversionistas. Un sistema distribuido sin métricas claras es como un avión sin instrumentos: puede volar, pero el riesgo de estrellarse es demasiado alto.
¿Qué retos culturales enfrentan los equipos gerenciales al migrar a un modelo de sistemas distribuidos?
Cuando se habla de migrar hacia sistemas distribuidos, la atención suele centrarse en servidores, microservicios, bases de datos y protocolos. Sin embargo, los mayores desafíos no siempre son técnicos. Para un director de RRHH o un gerente de tecnología, el verdadero reto está en las personas y en la cultura organizacional. La transición a una arquitectura distribuida no es solo un cambio de infraestructura; es un cambio profundo en la forma en que los equipos piensan, colaboran y asumen responsabilidades. A continuación, exploraremos los principales retos culturales que los equipos gerenciales deben anticipar y gestionar con inteligencia. 1. Resistencia al cambio: el enemigo silencioso En toda transformación tecnológica, la resistencia al cambio es inevitable. Los empleados que han trabajado durante años con sistemas centralizados suelen sentirse cómodos con procesos conocidos, incluso si son ineficientes. Por qué ocurre: miedo a perder el control, incertidumbre sobre la estabilidad laboral y desconocimiento del nuevo modelo. Impacto gerencial: esta resistencia puede ralentizar proyectos, generar errores intencionales o involuntarios y afectar la moral del equipo. ✅ Estrategia recomendada: comunicar claramente los beneficios de la migración, no solo a nivel técnico, sino cómo impactará positivamente en su trabajo diario (menos carga manual, menos incidencias, más innovación). 2. Cambio de mentalidad: de lo centralizado a lo colaborativo En un sistema centralizado, los equipos suelen trabajar de forma jerárquica y lineal: un área controla la base de datos, otra gestiona la aplicación, y la comunicación es limitada. En sistemas distribuidos, esta dinámica cambia radicalmente. Los equipos deben adoptar una mentalidad colaborativa y multidisciplinaria, donde los desarrolladores, ingenieros de infraestructura y analistas de datos interactúan constantemente. Reto cultural: pasar de un modelo de silos a uno de colaboración horizontal. Ejemplo: en una empresa de retail, el equipo de inventarios debe coordinarse en tiempo real con el de ventas online para evitar sobreventa. ✅ Estrategia gerencial: fomentar equipos de trabajo ágiles (Scrum, DevOps) donde la colaboración sea parte del ADN organizacional. 3. Nuevos roles y redefinición de responsabilidades La adopción de sistemas distribuidos exige nuevos perfiles profesionales: expertos en arquitectura distribuida, ingenieros de confiabilidad (SRE), especialistas en observabilidad, etc. Reto cultural: empleados con años de antigüedad pueden sentir que pierden relevancia ante los nuevos talentos. Impacto en RRHH: posible rotación de personal clave si no se gestiona adecuadamente la transición. ✅ Estrategia recomendada: invertir en programas de reskilling y upskilling. Formar al talento interno demuestra compromiso con el equipo y reduce la resistencia. 4. Tolerancia al error y cultura de aprendizaje continuo En entornos distribuidos, los fallos son inevitables: caídas de nodos, inconsistencias temporales o latencias inesperadas. La cultura tradicional tiende a buscar culpables; sin embargo, en un sistema distribuido, la clave es aprender rápido. Reto cultural: pasar de una cultura punitiva a una cultura de aprendizaje continuo. Impacto en la innovación: si los equipos temen equivocarse, evitarán experimentar y no aprovecharán todo el potencial de la nueva arquitectura. ✅ Estrategia gerencial: implementar sesiones de post-mortem sin culpables, donde cada incidente sea analizado con enfoque constructivo. 5. Comunicación constante y alineación con la visión estratégica La migración a sistemas distribuidos implica meses o incluso años de transición. Durante este periodo, los rumores, la desinformación y la incertidumbre pueden propagarse rápidamente. Reto cultural: mantener a todos los niveles alineados con la visión del proyecto. Impacto directo: sin una comunicación clara, los empleados pueden percibir la migración como un gasto innecesario o como un riesgo para sus puestos. ✅ Estrategia recomendada: los líderes deben comunicar de forma constante y transparente: metas, avances, beneficios alcanzados y próximos hitos. 6. Trabajo remoto y descentralizado: confianza en los equipos Los sistemas distribuidos suelen ir de la mano con equipos distribuidos. Es común que la operación tecnológica se reparta en diferentes regiones o que se trabaje de forma remota. Reto cultural: pasar de una supervisión presencial a una basada en objetivos. Impacto en la gerencia: los líderes deben aprender a confiar en la autonomía de sus equipos y medirlos por resultados, no por horas conectados. ✅ Estrategia recomendada: establecer KPIs claros y medibles para cada equipo, reforzando la confianza mutua. 7. Gestión del estrés y salud organizacional La presión de una migración tecnológica puede generar altos niveles de estrés, especialmente en los equipos técnicos. Jornadas extensas, miedo a fallar y sobrecarga cognitiva son problemas frecuentes. Reto cultural: mantener la motivación y bienestar del equipo durante el cambio. Impacto en RRHH: si no se cuida la salud mental, se incrementa la rotación y disminuye la productividad. ✅ Estrategia gerencial: equilibrar las exigencias con iniciativas de bienestar, pausas activas y reconocimiento público de logros. 8. Storytelling: La transformación de una cultura corporativa El caso de Mariana, directora de RRHH en una empresa financiera, ilustra perfectamente este reto. Cuando su compañía decidió migrar a sistemas distribuidos, el equipo técnico reaccionó con miedo: “Esto nos va a dejar sin trabajo”, decían. Mariana organizó talleres explicativos donde los líderes de TI mostraron cómo la nueva arquitectura reduciría tareas repetitivas y abriría oportunidades de desarrollo profesional. Además, lanzó un programa de certificaciones internas en tecnologías distribuidas. Seis meses después, el 80% del equipo había completado al menos un curso, la moral interna subió y la empresa logró la transición sin perder talento clave. 9. Conclusión persuasiva Los sistemas distribuidos no solo transforman la tecnología, sino la cultura organizacional. Para un gerente o director, gestionar estos retos culturales es tan importante como elegir la mejor arquitectura técnica. La clave está en liderar con empatía, comunicar con claridad y fomentar una cultura de aprendizaje continuo. Porque al final, no son los servidores los que hacen exitosa una migración: son las personas.

¿Qué papel juega la observabilidad en la toma de decisiones gerenciales sobre sistemas distribuidos?
En el mundo empresarial actual, donde cada segundo de inactividad puede costar miles o millones de dólares, los gerentes y directores necesitan tomar decisiones rápidas y basadas en datos confiables. Sin embargo, los sistemas distribuidos son, por naturaleza, complejos y a menudo opacos: miles de nodos, microservicios dispersos, bases de datos replicadas en distintas regiones y usuarios que interactúan en tiempo real. La observabilidad surge entonces como el “sexto sentido” de la alta gerencia tecnológica. No se trata únicamente de monitorear si un sistema está “arriba” o “abajo”; es la capacidad de entender, predecir y actuar sobre lo que ocurre en toda la infraestructura distribuida. Para los líderes gerenciales, la observabilidad no es un término técnico, es una herramienta estratégica para tomar mejores decisiones. Veamos por qué. 1. Observabilidad: más que monitoreo, un instrumento de negocio El monitoreo tradicional responde preguntas como: “¿El servidor está funcionando?”. La observabilidad va mucho más allá: permite responder por qué algo está fallando, dónde ocurre y cómo prevenirlo. Para un gerente, esto significa transformar datos técnicos en información accionable. No basta con saber que un servicio cayó; la observabilidad revela si el problema es una sobrecarga de un microservicio, un cuello de botella en la base de datos o un error de configuración en una región específica. ✅ Impacto gerencial directo: con esa información, se pueden tomar decisiones inmediatas sobre reasignar recursos, priorizar inversiones o ajustar estrategias operativas. 2. Toma de decisiones proactiva: anticiparse antes de que afecte al cliente En un sistema distribuido, los fallos no siempre son inmediatos. Muchas veces, pequeñas anomalías son señales de problemas mayores. La observabilidad, mediante análisis de logs, métricas y trazas, permite detectar patrones anómalos antes de que se conviertan en incidentes críticos. Ejemplo real: una fintech detecta un aumento gradual en la latencia de un microservicio clave. Gracias a la observabilidad, el equipo técnico redistribuye la carga a tiempo, evitando que miles de transacciones fallen durante un pico de demanda. Perspectiva gerencial: tomar decisiones antes de que el cliente perciba el problema es la diferencia entre mantener la confianza o perderla. 3. Optimización de costos operativos con datos confiables La observabilidad no solo ayuda a prevenir fallas; también permite identificar recursos infrautilizados o sobrecargados. Ejemplo gerencial: un panel de observabilidad muestra que un conjunto de nodos en Asia funciona con solo un 20% de su capacidad, mientras que en Europa están al 90%. Con esta información, un CTO puede redistribuir la infraestructura y reducir costos en la nube sin afectar el rendimiento. Valor estratégico: cada dólar ahorrado en infraestructura es un dólar que puede reinvertirse en innovación. 4. Facilitando decisiones de negocio en tiempo real En sectores como retail, banca o telecomunicaciones, las decisiones no pueden esperar días ni horas; deben tomarse en minutos. La observabilidad proporciona datos en tiempo real que impactan en áreas fuera de TI: En logística: detectar retrasos en actualizaciones de inventario permite redirigir envíos a tiempo. En marketing: identificar picos de tráfico en una campaña digital ayuda a ajustar presupuesto publicitario de inmediato. En RRHH: medir el rendimiento de plataformas internas permite decidir cuándo reforzar o redistribuir equipos de soporte. ✅ Impacto clave: la observabilidad convierte a los líderes tecnológicos en socios estratégicos del negocio, no solo en “guardianes de servidores”. 5. Transparencia y confianza en la alta dirección En muchos consejos directivos, los temas tecnológicos suelen ser percibidos como “una caja negra”. La observabilidad cambia esa percepción al ofrecer reportes visuales y métricas comprensibles para ejecutivos no técnicos. Ejemplo: un CEO puede ver en un dashboard que la disponibilidad general del sistema se mantiene en 99.99% y que el tiempo medio de resolución de incidentes bajó de 2 horas a 30 minutos. Resultado: mayor confianza en las decisiones del CTO y respaldo a futuras inversiones tecnológicas. 6. Cultura basada en datos y aprendizaje continuo Adoptar observabilidad fomenta una cultura empresarial orientada a datos, no a suposiciones. Cada incidente se convierte en una oportunidad de aprendizaje: Los datos históricos permiten identificar patrones y mejorar procesos. Los equipos de RRHH y gerencia pueden evaluar con precisión la productividad y necesidades de capacitación. ✅ Para la alta dirección, esto significa tomar decisiones respaldadas por evidencia y no por intuición. 7. Storytelling: El caso de un gerente visionario Luis, gerente de tecnología en una empresa de comercio electrónico, enfrentaba constantes quejas de clientes por demoras en la plataforma. El equipo técnico aseguraba que “todo estaba bien”, pero las ventas seguían cayendo. Luis decidió invertir en un sistema avanzado de observabilidad. Descubrieron que, aunque los servidores estaban activos, un microservicio encargado de calcular costos de envío sufría picos de latencia durante las noches. Con estos datos, redistribuyeron cargas y ajustaron configuraciones. En menos de un mes, las quejas de clientes disminuyeron un 70% y las ventas aumentaron un 15%. Luis no solo resolvió un problema técnico; recuperó la confianza del CEO y obtuvo presupuesto para nuevos proyectos. 8. Conclusión persuasiva La observabilidad no es una herramienta exclusiva para ingenieros; es un recurso estratégico para la alta gerencia. Permite tomar decisiones basadas en datos, anticiparse a problemas, optimizar costos y demostrar resultados tangibles ante la dirección. En un entorno de sistemas distribuidos, donde cada componente puede ser un eslabón crítico, la observabilidad es la brújula que guía las decisiones inteligentes. Un gerente que no la aproveche estará navegando a ciegas en un mar de complejidad.

¿Cómo los sistemas distribuidos mejoran la eficiencia de la cadena de suministro?
La cadena de suministro es el sistema circulatorio de cualquier empresa que produce, distribuye o vende bienes. Si este sistema se interrumpe, se ralentiza o no responde a tiempo, las pérdidas pueden ser millonarias. En este contexto, los sistemas distribuidos se han convertido en una de las armas más poderosas para lograr cadenas de suministro ágiles, resilientes y rentables. A continuación, exploraremos cómo esta arquitectura tecnológica no solo mejora la eficiencia operativa, sino que también transforma la forma en que los gerentes toman decisiones estratégicas en logística y distribución. 1. Visibilidad en tiempo real: el poder de saberlo todo, en todo momento En cadenas de suministro tradicionales, la información fluye de manera fragmentada: los datos de inventario están en un sistema, el transporte en otro y la facturación en otro diferente. Esto genera retrasos y errores. Con los sistemas distribuidos, toda esta información se sincroniza y distribuye en tiempo real entre diferentes nodos. Cada almacén, camión o punto de venta se convierte en un nodo que actualiza y recibe datos de manera simultánea. ✅ Ejemplo gerencial: Un gerente de operaciones puede ver al instante: Cuántas unidades quedan en un almacén de México. Si un camión en Brasil sufrió un retraso. Qué proveedor en China tiene capacidad para enviar más productos de inmediato. Este nivel de visibilidad permite tomar decisiones correctivas en minutos, no en días. 2. Optimización de inventarios: menos exceso, menos quiebres de stock Uno de los grandes problemas logísticos es encontrar el equilibrio entre tener suficiente inventario para no perder ventas y no acumular stock innecesario que inmovilice capital. Los sistemas distribuidos utilizan algoritmos que analizan simultáneamente datos de ventas, inventarios y tendencias de demanda en distintas regiones, ajustando los niveles de stock automáticamente. Caso práctico: una cadena de supermercados que usa sistemas distribuidos puede detectar que en una región aumenta la venta de productos frescos y redirigir existencias desde almacenes con menor demanda. Impacto gerencial: menos pérdidas por caducidad, menos costos de almacenamiento y más ventas. 3. Rutas de transporte más eficientes mediante datos en tiempo real En la logística de transporte, los retrasos pueden multiplicar costos. Los sistemas distribuidos permiten que cada vehículo de la flota actúe como un nodo que envía constantemente datos de ubicación, tráfico y estado de carga. Ejemplo real: si un camión se queda atrapado en un embotellamiento, el sistema puede reasignar automáticamente entregas a otro vehículo cercano o notificar al cliente del retraso con precisión. Valor estratégico: estas acciones no solo reducen tiempos de entrega, sino que mejoran la percepción del cliente final. 4. Colaboración ágil entre múltiples actores de la cadena Una cadena de suministro moderna involucra a múltiples actores: proveedores, fabricantes, transportistas, distribuidores y minoristas. Tradicionalmente, cada uno opera en su propio sistema, lo que genera fricciones y demoras. Con sistemas distribuidos, todos los participantes se conectan a una misma red de datos, manteniendo sincronizada la información. ✅ Ejemplo de colaboración: Un proveedor puede ver que un minorista ha agotado cierto producto y enviar automáticamente más unidades. Un transportista puede acceder en tiempo real a la agenda de entregas, reduciendo errores de coordinación. El resultado es una cadena de suministro que actúa como un organismo único y coordinado. 5. Resiliencia ante interrupciones: continuidad garantizada Las interrupciones en la cadena de suministro (huelgas, desastres naturales, fallos tecnológicos) son inevitables. En un sistema centralizado, un fallo en un servidor puede paralizar toda la operación. En cambio, los sistemas distribuidos están diseñados para ser resilientes: Si un nodo falla, otro asume su función. Si una región se desconecta, los demás nodos continúan operando de manera independiente. ✅ Impacto gerencial: en lugar de detener toda la cadena, se pueden aislar problemas regionales mientras el resto de la operación sigue funcionando. 6. Predicción y análisis avanzado con IA y Big Data Los sistemas distribuidos facilitan el procesamiento de grandes volúmenes de datos en tiempo real, lo que habilita el uso de inteligencia artificial para predecir la demanda, anticipar interrupciones y optimizar recursos. Ejemplo: un algoritmo puede detectar patrones climáticos que afectarán la producción agrícola y ajustar los pedidos con semanas de anticipación. Decisión estratégica: los gerentes ya no reaccionan a los problemas; se adelantan a ellos. 7. Reducción de costos operativos Toda esta eficiencia se traduce en ahorros significativos: Menos inventario almacenado = menos costos de bodegaje. Rutas optimizadas = menor gasto en combustible y mantenimiento. Menos errores de coordinación = menos devoluciones y reclamos. ✅ Visión para el CFO: cada optimización respaldada por sistemas distribuidos impacta directamente en el margen operativo. 8. Storytelling: El caso de una empresa transformada Claudia, directora de operaciones en una empresa de distribución farmacéutica, enfrentaba constantes quiebres de stock en ciertas farmacias y exceso de inventario en otras. Tras implementar un sistema distribuido que conectó almacenes, transportistas y puntos de venta: El nivel de quiebres de stock cayó un 60%. Los costos de almacenamiento se redujeron un 25%. Los tiempos de entrega promedio bajaron de 48 a 18 horas. Claudia no solo optimizó la logística; ganó credibilidad ante la junta directiva y obtuvo presupuesto para expandir operaciones internacionales. 9. Conclusión persuasiva En la era de la hipercompetencia, una cadena de suministro eficiente es una ventaja competitiva irremplazable. Los sistemas distribuidos no son simplemente un avance técnico, son un acelerador estratégico que permite responder más rápido, gastar menos y ofrecer un servicio superior al cliente final. Para los líderes gerenciales, invertir en esta arquitectura no es una decisión tecnológica, es una decisión de negocio que impacta directamente en la rentabilidad y en la satisfacción del cliente.

¿Qué factores críticos de éxito para escalar sistemas distribuidos en grandes corporaciones?
Escalar un sistema distribuido en una gran corporación no es simplemente “agregar más servidores”. Implica una orquestación estratégica de recursos tecnológicos, talento humano y procesos gerenciales. Para un director de tecnología (CTO) o un gerente general, el éxito de esta escalabilidad determina si la empresa podrá crecer sin fricciones, soportar picos de demanda y mantener una ventaja competitiva sostenida. A continuación, desglosamos los factores críticos que todo líder debe dominar para garantizar una escalabilidad exitosa. 1. Arquitectura flexible y diseñada para escalar El primer paso es diseñar con visión de crecimiento desde el inicio. Muchas corporaciones fallan porque construyen sistemas pensados para el presente, no para el futuro. ✅ Buenas prácticas: Adoptar microservicios, donde cada módulo pueda escalarse de manera independiente según su demanda. Usar contenedores y orquestadores (Kubernetes, Docker) que permitan desplegar rápidamente nuevas instancias. Impacto gerencial: una arquitectura flexible permite reaccionar de inmediato ante nuevas oportunidades de negocio, sin esperar meses para redimensionar la infraestructura. 2. Automatización como base de la escalabilidad En sistemas distribuidos de gran tamaño, la administración manual es inviable. La automatización es un factor clave para escalar sin multiplicar el equipo técnico. ✅ Aspectos críticos: Autoscaling: sistemas que aumentan o reducen recursos automáticamente según la demanda. CI/CD (Integración y entrega continua): permite desplegar actualizaciones sin interrumpir el servicio. Automatización del monitoreo: alertas automáticas que identifican problemas antes de que impacten a los usuarios. Valor gerencial: automatizar reduce errores humanos, disminuye costos operativos y libera a los equipos para que se enfoquen en innovación. 3. Gobernanza de datos sólida y consistente A medida que un sistema distribuido crece, los datos se multiplican y se replican en diferentes nodos, aumentando el riesgo de inconsistencias. ✅ Factores críticos: Implementar políticas de consistencia eventual o fuerte según el tipo de negocio. Establecer un gobierno de datos corporativo, asegurando integridad, calidad y cumplimiento normativo (GDPR, HIPAA, etc.). Impacto para la alta dirección: decisiones estratégicas solo serán tan buenas como la calidad de los datos en los que se basan. 4. Observabilidad avanzada para escalar con confianza Mientras más grande es un sistema distribuido, mayor es su complejidad. No se puede escalar lo que no se puede observar. ✅ Recomendaciones: Integrar herramientas de observabilidad que muestren métricas clave (latencia, throughput, tasa de errores) en tiempo real. Implementar trazas distribuidas para identificar cuellos de botella en microservicios específicos. Valor estratégico: la observabilidad no solo detecta problemas, sino que guía decisiones de inversión: ¿es mejor añadir más nodos, optimizar código o redistribuir carga? 5. Talento especializado y cultura orientada al crecimiento La escalabilidad no es solo tecnológica; es también un reto humano y cultural. ✅ Factores humanos críticos: Formar y retener ingenieros especializados en arquitecturas distribuidas, DevOps y seguridad en la nube. Fomentar una cultura de aprendizaje continuo para que los equipos se adapten a nuevas herramientas. Romper los silos organizacionales mediante metodologías ágiles y colaboración entre áreas (TI, operaciones, finanzas). Impacto en RRHH: escalar un sistema distribuido con un equipo desmotivado o sin las competencias necesarias es una receta para el fracaso. 6. Seguridad integrada desde el diseño (Security by Design) A medida que se escala un sistema distribuido, también crece su superficie de ataque. ✅ Buenas prácticas: Autenticación y autorización robusta en cada microservicio. Cifrado extremo a extremo para proteger datos sensibles. Auditorías y pruebas de penetración periódicas. Valor para la alta dirección: una brecha de seguridad puede costar millones en multas y reputación. La escalabilidad no debe comprometer la seguridad. 7. Estrategia financiera clara y alineada al negocio Escalar sistemas distribuidos requiere inversión, pero no todo crecimiento tecnológico se traduce en retorno inmediato. ✅ Aspectos financieros clave: Calcular el costo por transacción o usuario antes y después de escalar. Proyectar el ROI considerando nuevos ingresos habilitados por la escalabilidad (más clientes, nuevos mercados). Negociar con proveedores cloud modelos de pago por uso que optimicen costos. Impacto gerencial: el CFO y el CTO deben trabajar juntos para justificar cada dólar invertido en escalabilidad. 8. Plan de contingencia y pruebas de estrés continuas Antes de escalar a gran escala, los sistemas deben probarse en condiciones extremas. ✅ Buenas prácticas: Realizar pruebas de estrés periódicas que simulen picos de demanda. Contar con planes de contingencia para redirigir tráfico en caso de fallas masivas. Valor estratégico: garantizar que el sistema pueda crecer sin colapsar protege la reputación corporativa y la confianza de los clientes. 9. Storytelling: El caso de éxito en telecomunicaciones Rodrigo, CTO de una gran empresa de telecomunicaciones, enfrentaba un dilema: cada vez que lanzaban una promoción, el sistema centralizado colapsaba por el exceso de usuarios. Decidieron escalar mediante una arquitectura distribuida basada en microservicios y autoscaling automático. En menos de un año: Soportaron picos de 5 millones de usuarios simultáneos sin interrupciones. Redujeron los costos de infraestructura en un 30% gracias a un modelo de pago por demanda. Aumentaron sus ingresos en un 25% al mantener la plataforma estable en fechas de alta demanda. Rodrigo no solo resolvió un problema técnico; demostró que la escalabilidad bien ejecutada es un impulsor directo del negocio. 10. Conclusión persuasiva Escalar sistemas distribuidos en grandes corporaciones no es solo cuestión de añadir más nodos; es un desafío estratégico que combina arquitectura, talento, cultura y finanzas. Los líderes que dominen estos factores críticos no solo garantizarán la estabilidad técnica, sino que abrirán la puerta a nuevos mercados, aumentarán ingresos y reforzarán la confianza de los clientes. En un mundo donde la demanda cambia cada minuto, la capacidad de escalar rápido y con eficiencia ya no es opcional; es el nuevo estándar competitivo.
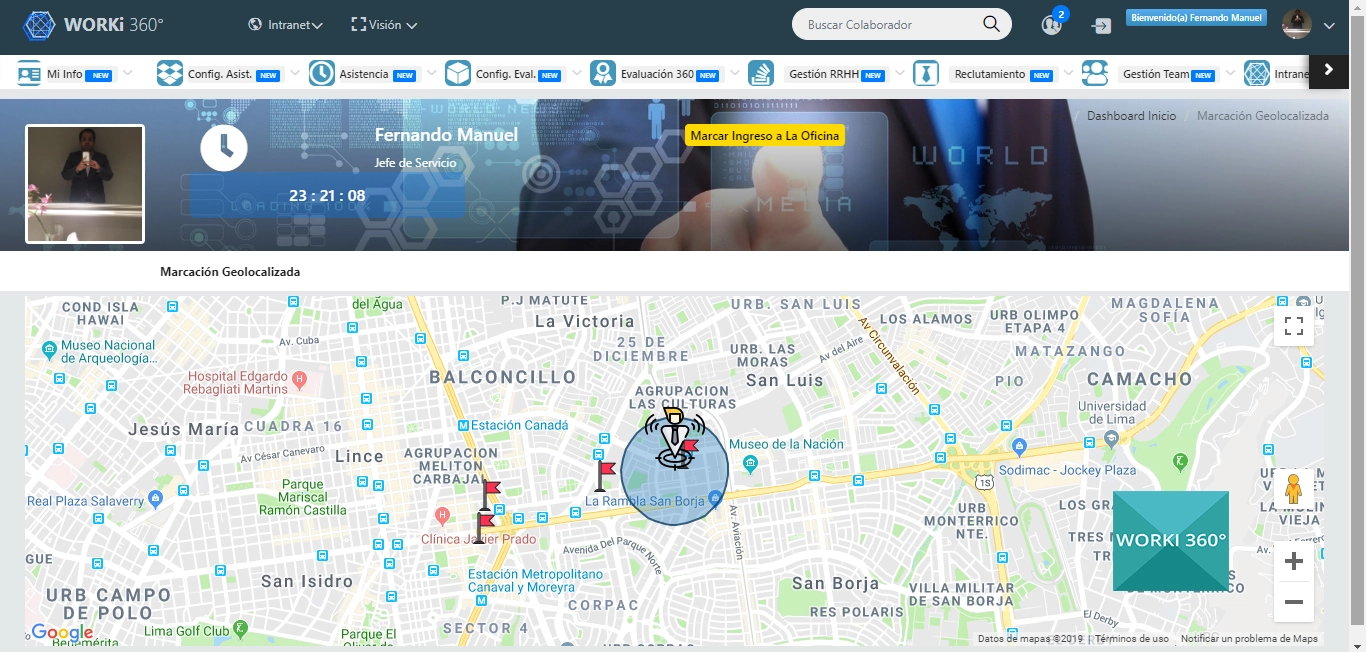
¿Qué pasos estratégicos debe seguir un gerente para liderar la migración hacia sistemas distribuidos?
Migrar hacia sistemas distribuidos no es un simple proyecto de TI; es una transformación organizacional profunda que impacta procesos, cultura, costos y, sobre todo, la capacidad de la empresa para competir en un mercado digitalizado. Para un gerente, liderar esta transición no solo requiere conocimiento técnico, sino también visión estratégica, habilidades de liderazgo y una comunicación impecable con todas las áreas de la compañía. A continuación, detallo los pasos estratégicos esenciales que un gerente debe seguir para garantizar una migración exitosa y con impacto positivo en los resultados del negocio. 1. Definir una visión estratégica clara y alineada al negocio Antes de tocar un solo servidor, el gerente debe responder: ¿Por qué migrar a sistemas distribuidos? ¿Qué objetivos de negocio queremos lograr? (¿Mayor escalabilidad? ¿Reducción de costos? ¿Mejor experiencia del cliente?) ✅ Acción clave: presentar un business case sólido a la alta dirección, mostrando beneficios tangibles como: Reducción de tiempos de inactividad. Soporte a nuevos mercados o líneas de negocio. Incremento proyectado en ingresos o satisfacción del cliente. Impacto: una visión clara alinea a todos los actores (TI, finanzas, RRHH y operaciones) y evita la percepción de que la migración es “solo un capricho tecnológico”. 2. Formar un equipo multidisciplinario de alto rendimiento Migrar a sistemas distribuidos requiere la colaboración de múltiples áreas. El gerente debe construir un equipo élite con roles bien definidos: ✅ Perfiles clave: Arquitectos de sistemas distribuidos: para diseñar la infraestructura. Ingenieros DevOps y SRE: para garantizar despliegues y confiabilidad. Especialistas en seguridad: para integrar controles desde el inicio. Representantes de negocio: que traduzcan necesidades comerciales en requerimientos técnicos. Valor estratégico: un equipo diverso garantiza que la migración no se enfoque solo en tecnología, sino en resolver problemas de negocio reales. 3. Evaluar la infraestructura actual y diseñar la hoja de ruta Un gerente no puede liderar a ciegas. Es necesario un análisis exhaustivo del estado actual: ¿Qué sistemas son críticos? ¿Qué dependencias existen entre aplicaciones? ¿Qué procesos pueden migrarse primero sin riesgo? ✅ Acción clave: construir una hoja de ruta en fases, priorizando: Migración de servicios menos críticos (para aprender sin poner en riesgo el negocio). Evolución gradual de sistemas centrales, asegurando compatibilidad con sistemas heredados. Impacto: este enfoque por fases reduce riesgos y permite mostrar resultados tempranos a la dirección. 4. Adoptar una estrategia híbrida y evitar el “Big Bang” Intentar migrar toda la infraestructura de una sola vez (modelo Big Bang) es una receta para el desastre. ✅ Estrategia recomendada: Adoptar un modelo híbrido temporal, donde convivan sistemas centralizados y distribuidos mientras se completa la migración. Usar API y middleware para garantizar interoperabilidad durante la transición. Beneficio gerencial: esta estrategia minimiza interrupciones y da confianza a los equipos de negocio, que temen afectaciones en operaciones diarias. 5. Invertir en capacitación y gestión del cambio cultural Uno de los mayores retos no es técnico, sino humano. Los empleados deben entender y aceptar el cambio. ✅ Acciones estratégicas: Programas de reskilling y upskilling: formar al talento interno en microservicios, cloud, DevOps, etc. Comunicación constante: explicar beneficios en términos claros (menos fallas, mayor innovación, oportunidades de crecimiento profesional). Reconocimiento y liderazgo visible: destacar públicamente a los equipos que lideran con éxito cada fase. Impacto: la motivación y el compromiso del personal son factores críticos para evitar sabotajes involuntarios o errores por falta de conocimiento. 6. Asegurar la observabilidad y el monitoreo desde el inicio Migrar sin visibilidad es como conducir con los ojos cerrados. ✅ Acciones críticas: Implementar herramientas de observabilidad desde la primera fase, no después. Monitorear métricas clave: latencia, throughput, error rate, costo por transacción. Establecer tableros ejecutivos para que la alta dirección vea los avances en tiempo real. Valor estratégico: estos datos no solo ayudan a resolver problemas, sino a demostrar resultados concretos al CEO y al CFO. 7. Garantizar la seguridad como prioridad absoluta Los sistemas distribuidos amplían la superficie de ataque. Una brecha en plena migración puede destruir la confianza del cliente. ✅ Acciones: Integrar cifrado, autenticación y auditorías desde el diseño. Establecer un plan de respuesta a incidentes claro. Capacitar al personal en buenas prácticas de seguridad en entornos distribuidos. Impacto gerencial: proteger la reputación corporativa y evitar sanciones legales por incumplimiento normativo. 8. Medir resultados y comunicar victorias rápidas Los altos directivos quieren ver resultados. El gerente debe definir indicadores claros de éxito (KPIs): Disponibilidad del sistema. Reducción de tiempos de respuesta. Ahorro en costos operativos. Incremento en satisfacción del cliente. ✅ Acción estratégica: comunicar “victorias rápidas” al finalizar cada fase, reforzando la confianza de la junta directiva y asegurando más presupuesto para continuar. 9. Preparar un plan de contingencia y reversión Toda migración tiene riesgos. El gerente debe estar preparado para retroceder parcialmente sin interrumpir el negocio. ✅ Buenas prácticas: Contar con sistemas de respaldo y recuperación automática. Definir protocolos claros para volver temporalmente al sistema anterior en caso de fallas críticas. Valor estratégico: mantener la continuidad del negocio mientras se avanza con confianza. 10. Storytelling: Un gerente que cambió la historia de su empresa Verónica, gerente de tecnología en una cadena de retail, lideró la migración hacia sistemas distribuidos con un enfoque estratégico. En lugar de intentar un cambio masivo, priorizó las operaciones de e-commerce, implementó microservicios y capacitó al personal interno. En seis meses: Redujo los tiempos de carga del sitio web de 4 segundos a 800 ms. Logró un incremento del 20% en ventas online. Presentó a la junta un ROI del 150% sobre la inversión tecnológica. Verónica no solo ejecutó una migración; posicionó la tecnología como un habilitador de negocio y fue promovida a directora de innovación. 11. Conclusión persuasiva Migrar hacia sistemas distribuidos no es una carrera técnica, es una maratón estratégica. Requiere visión de negocio, liderazgo inspirador y decisiones basadas en datos. Los gerentes que sigan estos pasos no solo lograrán una transición sin contratiempos, sino que transformarán la tecnología en un motor de crecimiento y en una ventaja competitiva sostenible. En un mundo donde la agilidad es sinónimo de supervivencia, el verdadero liderazgo está en quienes guían a sus empresas hacia esta nueva era digital con confianza y estrategia.
¿Qué beneficios tienen los sistemas distribuidos en empresas con operaciones globales 24/7?
Las empresas con operaciones globales —ya sean bancos multinacionales, plataformas de e-commerce o cadenas de suministro internacionales— enfrentan un reto monumental: estar disponibles y ser eficientes las 24 horas del día, los 7 días de la semana, en diferentes husos horarios y con millones de interacciones simultáneas. En este contexto, los sistemas distribuidos no son solo una ventaja tecnológica; son un requisito imprescindible para mantener la competitividad y la satisfacción del cliente en un mundo hiperconectado. A continuación, exploraremos los beneficios más importantes que esta arquitectura ofrece a empresas que no pueden permitirse un solo minuto de inactividad. 1. Alta disponibilidad y continuidad operativa global El mayor beneficio de los sistemas distribuidos para operaciones 24/7 es su capacidad de garantizar que los servicios estén siempre disponibles, sin importar la hora o el lugar. ✅ Por qué es clave: En un sistema centralizado, un fallo en el servidor principal puede dejar fuera de servicio a toda la empresa. En un sistema distribuido, si un nodo falla en Asia, otro en Europa o América puede asumir automáticamente la operación. Impacto gerencial: Menos pérdidas por interrupciones en ventas. Mayor confianza de clientes e inversores, quienes esperan servicios ininterrumpidos, especialmente en sectores críticos como banca, salud y telecomunicaciones. 2. Reducción de la latencia para clientes en diferentes regiones Las empresas globales tienen usuarios dispersos en todo el mundo. Un sistema centralizado obliga a que todas las solicitudes viajen a un único punto, aumentando la latencia y degradando la experiencia. ✅ Beneficio clave de los sistemas distribuidos: Al tener nodos en múltiples regiones, las solicitudes se procesan en el nodo más cercano al usuario, reduciendo significativamente el tiempo de respuesta. Ejemplo: Un cliente en Tokio puede recibir respuesta en milisegundos desde un nodo local, en lugar de esperar varios segundos si los datos viajaran a un servidor en Estados Unidos. Impacto comercial: una experiencia de usuario rápida y consistente se traduce en más ventas y mayor fidelización. 3. Escalabilidad dinámica según la demanda en cada región Las operaciones 24/7 implican picos de tráfico en diferentes momentos, dependiendo de los husos horarios y eventos especiales. ✅ Con sistemas distribuidos: Es posible aumentar la capacidad de procesamiento en una región específica cuando hay más demanda (por ejemplo, en promociones nocturnas en Europa), mientras se reduce en otras regiones donde la demanda es baja. Impacto financiero: esto optimiza el uso de recursos y reduce costos operativos, ya que no es necesario mantener toda la infraestructura activa al máximo todo el tiempo. 4. Resiliencia ante fallos y desastres regionales Las empresas globales enfrentan riesgos como cortes eléctricos, desastres naturales o problemas regulatorios en regiones específicas. ✅ Ventaja estratégica: En un sistema distribuido, los datos y servicios se replican en diferentes regiones, por lo que una caída local no detiene toda la operación. El tráfico puede redirigirse automáticamente a nodos activos en otras ubicaciones. Impacto en reputación: la capacidad de mantener operaciones ininterrumpidas ante crisis refuerza la confianza de clientes y socios comerciales. 5. Operación y soporte ininterrumpidos en diferentes husos horarios En operaciones 24/7, no solo los sistemas, sino también los equipos humanos deben coordinarse globalmente. Los sistemas distribuidos facilitan esta dinámica: ✅ Beneficios operativos: Los equipos de soporte en Asia pueden monitorear los sistemas durante la noche en América y viceversa. La información y los registros están sincronizados en tiempo real, por lo que los turnos pueden dar continuidad sin pérdida de contexto. Impacto en RRHH: mejora la eficiencia de los equipos y reduce la carga de trabajo concentrada en un solo grupo de soporte. 6. Procesamiento de datos en tiempo real para decisiones estratégicas Las empresas globales necesitan datos en tiempo real para tomar decisiones rápidas: ajustar precios, redirigir inventarios o detectar fraudes. ✅ Con sistemas distribuidos: Los datos se procesan y analizan localmente en cada región, enviando solo la información crítica consolidada a los centros de decisión. Esto reduce la latencia y permite actuar con agilidad ante cambios en el mercado. Ejemplo: Una aerolínea global puede ajustar automáticamente precios de vuelos según la demanda en cada región sin esperar consolidaciones manuales. 7. Cumplimiento normativo y soberanía de datos Las leyes de protección de datos varían por región (GDPR en Europa, LGPD en Brasil, etc.). Los sistemas distribuidos permiten almacenar y procesar datos en nodos locales para cumplir con estas normativas. ✅ Impacto para los gerentes: Evita multas millonarias por incumplimiento. Permite operar en mercados donde las leyes exigen que los datos no salgan del país. 8. Reducción de costos operativos globales Aunque implementar sistemas distribuidos implica inversión inicial, a largo plazo ofrece ahorros significativos: Optimización de recursos según la demanda regional. Menos pérdidas por interrupciones. Reducción de costos logísticos al operar inventarios con datos en tiempo real. ✅ Visión para el CFO: cada dólar invertido en esta arquitectura se traduce en eficiencia operativa y mayor rentabilidad. 9. Storytelling: El caso de un gigante del e-commerce Fernando, director de operaciones de una plataforma de e-commerce global, enfrentaba quejas constantes: en Asia, los usuarios reportaban lentitud; en América, los picos de demanda colapsaban el sistema en fechas especiales. Tras migrar a sistemas distribuidos con nodos en diferentes continentes: La latencia se redujo un 70% en Asia. Las ventas en fechas de alto tráfico crecieron un 25% al soportar picos sin interrupciones. Los costos operativos bajaron un 15% gracias a la escalabilidad dinámica. Fernando no solo solucionó problemas técnicos; logró aumentar las ventas globales y consolidar la reputación de la marca como una plataforma confiable las 24 horas. 10. Conclusión persuasiva En empresas con operaciones globales 24/7, los sistemas distribuidos no son opcionales; son la base de la competitividad. Garantizan disponibilidad constante, mejoran la experiencia del cliente en todas las regiones, optimizan costos y permiten tomar decisiones estratégicas en tiempo real. Para los líderes gerenciales, adoptar esta arquitectura es una inversión estratégica que protege la reputación, impulsa ingresos y asegura la continuidad del negocio en un mundo que nunca duerme.

¿Cómo garantizar la continuidad de negocio mediante sistemas distribuidos?
En el mundo corporativo actual, donde cada minuto de inactividad puede representar pérdidas millonarias, la continuidad de negocio se ha convertido en una prioridad estratégica. Para un CEO, un CTO o un gerente de operaciones, garantizar que la empresa siga funcionando, sin importar si hay fallas tecnológicas, desastres naturales o ataques cibernéticos, es un requisito indispensable para mantener la confianza de clientes e inversores. Los sistemas distribuidos son una de las herramientas más poderosas para asegurar esa continuidad, gracias a su arquitectura resiliente y su capacidad de adaptarse a fallos. Sin embargo, no basta con implementarlos; se requiere una estrategia bien definida para sacar todo su potencial. A continuación, exploramos los pasos y buenas prácticas para lograrlo. 1. Arquitectura resiliente desde el diseño La resiliencia no se improvisa: debe ser parte del diseño de los sistemas distribuidos desde el inicio. ✅ Buenas prácticas arquitectónicas: Redundancia geográfica: replicar servicios en diferentes regiones o centros de datos. Balanceo de carga inteligente: distribuir el tráfico entre nodos, redirigiéndolo automáticamente en caso de fallas. Desacoplamiento de servicios (microservicios): evitar que el fallo de un módulo afecte al resto del sistema. Impacto estratégico: un sistema diseñado con estas premisas minimiza interrupciones incluso ante eventos catastróficos. 2. Replicación y respaldo constante de datos La información es el activo más valioso de cualquier empresa. En sistemas distribuidos, garantizar la continuidad del negocio implica mantener datos actualizados y accesibles en todo momento. ✅ Buenas prácticas: Replicación en tiempo real: los datos deben copiarse constantemente en diferentes nodos. Backups automatizados y distribuidos: mantener respaldos en múltiples ubicaciones físicas o en la nube. Pruebas periódicas de restauración: no basta con hacer copias; hay que asegurar que realmente funcionen al momento de necesitarlas. Valor para la alta dirección: estas medidas garantizan que, incluso ante la pérdida de un centro de datos, la empresa pueda retomar operaciones en minutos. 3. Planes de recuperación ante desastres (DRP) basados en sistemas distribuidos Un sistema distribuido facilita la creación de planes de recuperación robustos. ✅ Elementos críticos del DRP: Definir objetivos RTO y RPO claros: RTO (Recovery Time Objective): tiempo máximo aceptable para restaurar operaciones. RPO (Recovery Point Objective): cantidad máxima de datos que se pueden perder. Automatización de failover: conmutación automática a nodos alternativos cuando se detecta un fallo. Impacto gerencial: un DRP bien definido es una carta de presentación frente a inversionistas y reguladores, demostrando madurez operativa y compromiso con la continuidad del negocio. 4. Observabilidad y monitoreo predictivo La continuidad no se garantiza reaccionando a los problemas, sino anticipándose a ellos. ✅ Acciones clave: Implementar herramientas de observabilidad que identifiquen anomalías antes de que se conviertan en fallos críticos. Configurar alertas automáticas y análisis predictivo con IA para detectar patrones de fallos. Valor estratégico: la detección temprana permite tomar decisiones preventivas, evitando interrupciones costosas. 5. Pruebas de estrés y simulaciones de fallos controlados Una de las mayores ventajas de los sistemas distribuidos es que permiten realizar pruebas de resiliencia en entornos controlados. ✅ Prácticas recomendadas: Chaos Engineering: simular fallos aleatorios (apagado de nodos, desconexión de redes) para evaluar la respuesta del sistema. Simulaciones periódicas: entrenar a los equipos en escenarios de desastre para que sepan actuar sin pánico. Impacto para la alta gerencia: estas pruebas aumentan la confianza en que el sistema funcionará incluso en condiciones extremas. 6. Estrategia de escalabilidad para responder a picos imprevistos En muchos casos, la “caída” de un sistema no se debe a fallos, sino a picos de demanda no previstos. ✅ Solución con sistemas distribuidos: Configurar autoscaling, donde nuevos nodos se activen automáticamente cuando aumenta la carga. Monitorizar tendencias para anticipar incrementos de tráfico en fechas específicas (Black Friday, campañas globales). Valor financiero: mantener el servicio activo durante picos de demanda puede significar millones en ingresos adicionales. 7. Seguridad integrada como garantía de continuidad Un ciberataque puede ser tan destructivo como un desastre natural. Por ello, la seguridad debe ser parte de la estrategia de continuidad. ✅ Buenas prácticas en sistemas distribuidos: Autenticación robusta y cifrado extremo a extremo. Segmentación de microservicios: un ataque en un nodo no compromete todo el sistema. Monitoreo en tiempo real de amenazas. Impacto gerencial: evitar brechas protege tanto la operación como la reputación corporativa. 8. Capacitación continua y cultura de respuesta rápida La mejor tecnología no servirá si los equipos no saben cómo reaccionar. ✅ Estrategias gerenciales: Capacitar regularmente a los equipos en protocolos de continuidad. Fomentar una cultura de aprendizaje continuo donde los incidentes se analicen sin buscar culpables, sino soluciones. Valor para RRHH: un equipo preparado actúa con confianza y reduce los tiempos de respuesta en momentos críticos. 9. Comunicación clara con clientes y stakeholders En situaciones de crisis, la confianza se mantiene informando de manera proactiva. ✅ Acciones estratégicas: Integrar sistemas que notifiquen automáticamente a los clientes sobre posibles interrupciones o soluciones en curso. Mantener informados a directivos e inversores con dashboards en tiempo real. Impacto en reputación: una empresa que comunica de forma transparente fortalece la lealtad incluso durante incidentes. 10. Storytelling: El banco que nunca se detuvo Andrés, CTO de un banco con operaciones en América Latina, enfrentó un apagón masivo en una de las principales ciudades donde operaban. Gracias a su sistema distribuido: Los nodos en otras regiones asumieron automáticamente las transacciones. Los clientes ni siquiera notaron la interrupción. La junta directiva destacó el incidente como un ejemplo de madurez tecnológica y confianza institucional. En lugar de ser una crisis, el evento se convirtió en un argumento de venta para atraer nuevos clientes corporativos. 11. Conclusión persuasiva La continuidad de negocio ya no es una opción, es el nuevo estándar de competitividad global. Los sistemas distribuidos, bien diseñados y gestionados, son la columna vertebral que asegura operaciones ininterrumpidas, protege ingresos y mantiene la confianza de clientes e inversores. Para los líderes gerenciales, invertir en esta arquitectura no es solo una decisión tecnológica, sino un seguro estratégico para el futuro de la empresa.
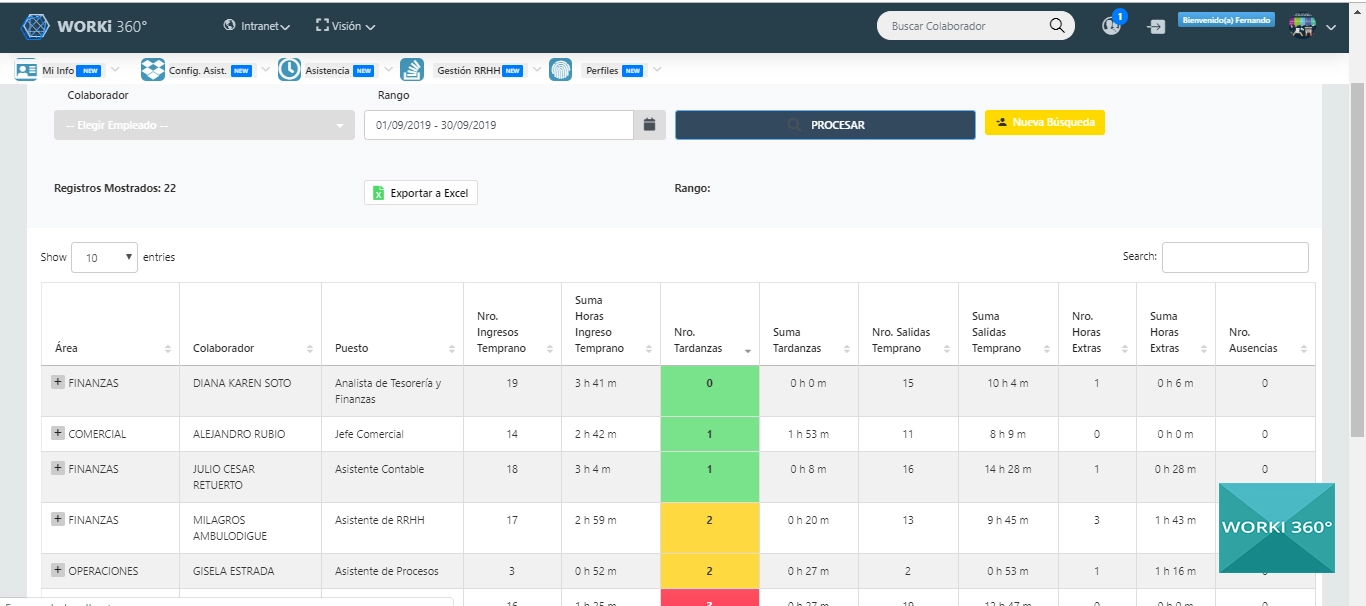
¿Por qué los sistemas distribuidos son fundamentales para la transformación digital de las grandes empresas?
La transformación digital no es simplemente digitalizar procesos o implementar nuevas herramientas; es redefinir la manera en que una empresa opera, toma decisiones y entrega valor a sus clientes. En este contexto, los sistemas distribuidos son mucho más que una tendencia tecnológica: son el motor que hace posible esa transformación en grandes corporaciones que buscan agilidad, escalabilidad y competitividad global. A continuación, veremos por qué esta arquitectura es la piedra angular de la transformación digital y cómo impacta directamente en la estrategia corporativa. 1. Base para la escalabilidad digital y el crecimiento sin límites La transformación digital implica manejar volúmenes masivos de datos, millones de interacciones y usuarios conectados simultáneamente. Los sistemas centralizados, con su capacidad limitada, no pueden soportar este crecimiento. ✅ Con sistemas distribuidos: Las empresas pueden escalar horizontalmente, agregando nodos o servidores según la demanda. Cada microservicio puede crecer de forma independiente, permitiendo que áreas como ventas online, analítica de datos o atención al cliente se amplíen sin afectar al resto de la operación. Impacto estratégico: las empresas pueden entrar en nuevos mercados o lanzar productos digitales rápidamente sin temer un colapso tecnológico. 2. Agilidad para innovar y adaptarse al mercado En la transformación digital, la capacidad de innovar rápido es clave. Los sistemas distribuidos, gracias a su diseño modular, permiten: Desplegar nuevas funcionalidades de forma independiente y continua (metodologías CI/CD). Experimentar con nuevos productos o servicios digitales sin comprometer la estabilidad del sistema completo. Ejemplo: una fintech puede probar un nuevo módulo de préstamos digitales en una región específica antes de expandirlo globalmente. Valor gerencial: los sistemas distribuidos convierten la tecnología en un habilitador de la innovación constante, algo que los sistemas monolíticos no pueden ofrecer. 3. Procesamiento de datos en tiempo real: decisiones más inteligentes La transformación digital se basa en decisiones impulsadas por datos. Con sistemas distribuidos, los datos se procesan en tiempo real, desde múltiples regiones o puntos de interacción. ✅ Beneficios directos: Análisis instantáneo del comportamiento del cliente para personalizar ofertas. Monitoreo continuo de la operación, anticipando fallos o ineficiencias. Predicción de la demanda, optimizando inventarios y producción. Impacto para la alta dirección: decisiones más rápidas y acertadas significan ventaja competitiva inmediata. 4. Experiencia del cliente superior y omnicanal La transformación digital tiene un objetivo central: mejorar la experiencia del cliente. Los sistemas distribuidos hacen esto posible gracias a: Baja latencia: los usuarios obtienen respuestas en milisegundos desde nodos cercanos. Sin interrupciones: la disponibilidad 24/7 mantiene la confianza del cliente. Omnicanalidad real: los datos del cliente se sincronizan en tiempo real entre tiendas físicas, apps móviles y plataformas web. ✅ Ejemplo: un cliente puede comprar en línea, recoger en tienda y recibir actualizaciones en su app sin inconsistencias en la información. 5. Reducción de riesgos operativos y mayor resiliencia La transformación digital no puede avanzar con sistemas frágiles. Los sistemas distribuidos, con su capacidad de replicación y conmutación automática, garantizan que: Un fallo en un nodo no afecte al resto de la operación. Las operaciones continúen activas incluso ante desastres regionales. Impacto en reputación: la resiliencia se traduce en confianza para clientes e inversionistas, un activo clave en la era digital. 6. Integración con tecnologías emergentes La verdadera transformación digital no se limita a digitalizar procesos; también implica integrar IA, machine learning, blockchain o IoT. ✅ Por qué los sistemas distribuidos son esenciales: Soportan grandes volúmenes de datos generados por dispositivos IoT. Permiten procesar algoritmos de IA de forma distribuida, acelerando análisis predictivos. Facilitan arquitecturas híbridas donde blockchain puede integrarse para mayor transparencia. Valor estratégico: esta flexibilidad posiciona a las empresas para adoptar futuras innovaciones sin reconstruir todo su sistema. 7. Cumplimiento regulatorio y adaptación local Las grandes corporaciones operan en múltiples países, cada uno con normas específicas de protección de datos (como GDPR en Europa o LGPD en Brasil). ✅ Con sistemas distribuidos: Los datos pueden almacenarse localmente en cada país, cumpliendo regulaciones. Se puede mantener una operación global sin sacrificar la legalidad en ninguna región. Impacto gerencial: evita multas millonarias y daños a la reputación, protegiendo el crecimiento digital de la empresa. 8. Optimización de costos en la era digital Aunque implementar sistemas distribuidos requiere inversión inicial, a largo plazo reduce costos operativos gracias a: Escalabilidad bajo demanda: pagar solo por los recursos utilizados. Menos interrupciones: evitando pérdidas millonarias por caídas del sistema. Automatización de procesos: menos carga manual para los equipos de TI. Visión para el CFO: la migración a sistemas distribuidos no es un gasto, sino una inversión con retorno directo en eficiencia y rentabilidad. 9. Storytelling: La empresa que dio el salto digital Sofía, directora de transformación digital en una compañía aseguradora, enfrentaba quejas constantes por procesos lentos y falta de visibilidad en tiempo real. Los sistemas centralizados tardaban días en procesar solicitudes de pólizas. Al migrar a una arquitectura distribuida: El procesamiento de solicitudes pasó de 48 horas a 10 minutos. La satisfacción del cliente subió un 30%. La empresa lanzó nuevos productos digitales en 3 meses, cuando antes tardaban más de un año. Sofía no solo modernizó la tecnología; redefinió la forma en que la empresa se relaciona con sus clientes, convirtiéndose en líder del sector. 10. Conclusión persuasiva La transformación digital de las grandes empresas no es posible sin sistemas distribuidos. Son el pilar que permite escalar, innovar, tomar decisiones en tiempo real y ofrecer experiencias superiores a los clientes. Para los líderes gerenciales, apostar por esta arquitectura no es simplemente modernizar TI; es asegurar la supervivencia y el liderazgo en la economía digital. Las empresas que entiendan esto hoy serán las que dominen los mercados del mañana. 🧾 Resumen Ejecutivo La adopción de sistemas distribuidos se presenta como un pilar estratégico para las grandes corporaciones que buscan eficiencia, resiliencia y competitividad en un mundo digitalizado. A partir del análisis de las 10 preguntas desarrolladas, se destacan los siguientes puntos clave orientados a los beneficios que WORKI 360 puede capitalizar para posicionarse como socio estratégico en transformación digital. ✅ 1. Impacto directo en la eficiencia operativa Los sistemas distribuidos reducen tiempos de respuesta, optimizan recursos y eliminan cuellos de botella, permitiendo a las empresas responder con agilidad a la demanda del mercado. WORKI 360 puede presentar esta ventaja como un argumento central para líderes que buscan aumentar productividad sin elevar drásticamente los costos operativos. ✅ 2. Métricas claras para la toma de decisiones gerenciales La observabilidad y monitoreo en tiempo real brindan a los directores visibilidad sobre el rendimiento (latencia, throughput, tasa de errores), lo que permite decisiones basadas en datos y no en suposiciones. WORKI 360 puede posicionarse como proveedor de herramientas que traduzcan métricas técnicas en reportes ejecutivos orientados a resultados de negocio. ✅ 3. Gestión cultural y liderazgo transformador El éxito en la migración hacia sistemas distribuidos depende de una cultura de colaboración, capacitación continua y comunicación clara. WORKI 360 puede diferenciarse ofreciendo programas de acompañamiento gerencial y formación especializada para reducir resistencia al cambio y alinear equipos. ✅ 4. Observabilidad como ventaja competitiva La capacidad de anticipar fallos y actuar antes de que impacten al cliente convierte a la observabilidad en una herramienta estratégica. WORKI 360 puede ofrecer paneles de control ejecutivos que traduzcan la complejidad técnica en indicadores de negocio, fortaleciendo la confianza en la alta dirección. ✅ 5. Eficiencia en la cadena de suministro Los sistemas distribuidos sincronizan inventarios, optimizan rutas logísticas y reducen costos operativos, mejorando la satisfacción del cliente. WORKI 360 puede posicionar soluciones orientadas a sectores con cadenas globales, ofreciendo visibilidad total y optimización predictiva. ✅ 6. Escalabilidad como motor de crecimiento La arquitectura distribuida permite escalar sin fricciones, responder a picos de demanda y entrar en nuevos mercados con rapidez. WORKI 360 puede resaltar este punto para empresas en expansión, presentando soluciones modulares y flexibles adaptadas al crecimiento progresivo. ✅ 7. Migración estratégica y progresiva El éxito en la migración requiere visión, planificación por fases y métricas claras de ROI, evitando riesgos del enfoque “Big Bang”. WORKI 360 puede ofrecer metodologías probadas de migración gradual, reduciendo riesgos y asegurando victorias rápidas que consoliden la confianza de la dirección. ✅ 8. Operaciones globales 24/7 sin interrupciones Los sistemas distribuidos garantizan disponibilidad constante, reducen latencia y optimizan recursos según demanda regional. WORKI 360 puede utilizar este argumento para atraer corporaciones globales que necesitan asegurar calidad de servicio en múltiples husos horarios. ✅ 9. Continuidad de negocio garantizada Con replicación de datos, failover automático y planes de contingencia, la arquitectura distribuida protege ingresos y reputación incluso ante desastres o ciberataques. WORKI 360 puede posicionar su propuesta como un seguro estratégico para empresas que no pueden permitirse interrupciones en sus operaciones críticas. ✅ 10. Pilar de la transformación digital Los sistemas distribuidos son el fundamento para innovar, integrar IA y big data, cumplir normativas y ofrecer experiencias digitales superiores. WORKI 360 debe presentar esta arquitectura como el paso obligatorio para cualquier empresa que quiera liderar en la economía digital, destacando su capacidad para acompañar integralmente este proceso. ✅ Conclusión Ejecutiva La transformación hacia sistemas distribuidos no es solo un proyecto de TI, es una decisión estratégica que impacta en la eficiencia, la escalabilidad, la resiliencia y la competitividad global. WORKI 360 tiene la oportunidad de posicionarse como un aliado clave de las grandes corporaciones, ofreciendo no solo tecnología, sino también consultoría estratégica, formación especializada y metodologías que garanticen resultados medibles en cada fase de la transformación digital.