
Índice del contenido
¿Qué impacto tiene la calidad del código en los indicadores de negocio?
En un entorno empresarial donde la eficiencia operativa, la velocidad de adaptación al mercado y la experiencia del cliente son pilares clave para la competitividad, hablar de “calidad del código” no es un asunto técnico aislado, sino una discusión estratégica directamente conectada a los resultados del negocio. Los CIOs, CTOs y líderes de ingeniería deben comprender que la calidad del código no es solo una preocupación de los desarrolladores; es un activo organizacional que tiene efectos profundos sobre costos, tiempo de entrega, satisfacción del cliente, reputación de la marca, ciberseguridad, rentabilidad y escalabilidad. A continuación, desarrollamos cómo la calidad del código impacta en los principales indicadores empresariales, desde una perspectiva gerencial. 1.1. Productividad del equipo y eficiencia operativa Un código de calidad es: Legible Modular Fácil de mantener Bien documentado Cubierto por pruebas Cuando el código presenta estas características, los desarrolladores pueden trabajar más rápido, entender rápidamente las funciones escritas por otros compañeros, reutilizar módulos existentes y detectar errores con menos esfuerzo. Por el contrario, un código desorganizado y lleno de "parches" incrementa la complejidad cognitiva, eleva la curva de aprendizaje para nuevos miembros del equipo y multiplica los tiempos de desarrollo, mantenimiento y pruebas. Impacto en el negocio: Mayor calidad = menos horas invertidas en tareas repetitivas, menos errores en producción, y más tiempo disponible para innovación. Esto se traduce en reducción de costos operativos y mayor retorno sobre la inversión en TI. 1.2. Time to market y velocidad de respuesta En industrias altamente competitivas, lanzar una nueva funcionalidad incluso una semana antes que la competencia puede significar miles o millones en ingresos adicionales. La calidad del código afecta directamente al time to market, porque: Facilita los despliegues continuos Reduce los ciclos de prueba Minimiza los errores inesperados en producción Acelera las aprobaciones en QA Cuando el código está bien estructurado y probado, se puede lanzar con confianza y rapidez. Impacto en el negocio: Menor tiempo de entrega de valor, posibilidad de reaccionar más rápido ante cambios del mercado y mejor capacidad de capturar oportunidades comerciales emergentes. 1.3. Costos de mantenimiento y deuda técnica La deuda técnica es uno de los conceptos más subestimados por la alta dirección. A medida que una aplicación crece sin estándares de calidad, se acumulan malas decisiones técnicas que luego requieren tiempo, esfuerzo y recursos para corregirse. Un código mal escrito genera: Bugs recurrentes Dificultad para escalar Mayor rotación de talento frustrado Costos imprevistos en mantenimiento Las empresas que no priorizan la calidad del código terminan pagando más, no solo en términos técnicos, sino también financieros y reputacionales. Impacto en el negocio: A mayor deuda técnica, mayores costos operativos a largo plazo y menor margen de maniobra presupuestal. Esto afecta directamente la rentabilidad. 1.4. Experiencia del cliente (CX) Cuando el código es limpio, estructurado y eficiente, la aplicación: Carga más rápido Tiene menos errores visibles para el usuario Responde de forma fluida a las interacciones Mantiene la estabilidad durante picos de tráfico Estas variables son esenciales para ofrecer una experiencia digital superior. En comercio electrónico, banca, servicios en línea o SaaS, una experiencia deficiente puede provocar pérdidas de ventas, baja retención y mala reputación online. Impacto en el negocio: La calidad del código contribuye a una mejor experiencia del cliente, lo que se refleja en más ventas, mayor fidelidad y mejor posicionamiento de marca. 1.5. Seguridad y cumplimiento normativo Los errores de seguridad más comunes —inyección SQL, XSS, CSRF, fugas de datos— muchas veces se deben a mala calidad del código. Sistemas mal estructurados son más difíciles de auditar, de parchear y de proteger. Además, regulaciones como GDPR, HIPAA o PCI DSS exigen niveles específicos de seguridad y trazabilidad, los cuales no se pueden cumplir adecuadamente si el código es deficiente. Impacto en el negocio: Aumenta el riesgo de sanciones legales, pérdida de datos sensibles, incidentes de ciberseguridad y pérdida de confianza por parte de los clientes. 1.6. Capacidad de escalar y expandirse Empresas en crecimiento necesitan que sus sistemas se adapten sin fricciones. La calidad del código determina si se podrá: Aumentar usuarios concurrentes Implementar nuevas funcionalidades rápidamente Escalar en arquitectura distribuida o microservicios Replicar módulos en nuevas unidades de negocio Si el código base es sólido, la expansión se logra con menos esfuerzo y menor inversión. Si es caótico, escalar se convierte en un problema estructural. Impacto en el negocio: La calidad del código es una barrera o un habilitador para el crecimiento empresarial. Las organizaciones que cuidan este aspecto pueden escalar sin poner en riesgo la operación. 1.7. Atracción y retención de talento Los desarrolladores más talentosos evitan trabajar con código desorganizado, sin estándares, ni cultura técnica. La calidad del código también afecta la motivación, la productividad y el compromiso de los equipos de TI. Impacto en el negocio: Mejor calidad de código = mejores profesionales, menos rotación, menor curva de aprendizaje y más innovación interna. 1.8. Medición y mejora continua Un código de calidad facilita: Medición de cobertura de pruebas Auditorías internas Refactorizaciones controladas Trazabilidad de cambios Análisis de performance Esto permite a los líderes de TI tener visibilidad real sobre el estado del sistema, tomar decisiones basadas en datos y optimizar continuamente el rendimiento tecnológico de la empresa. Impacto en el negocio: Decisiones más rápidas, más efectivas y basadas en evidencia concreta, no en percepciones o urgencias. 1.9. Cómo medir la calidad del código con visión gerencial Los líderes tecnológicos deben implementar herramientas y KPIs para monitorear la calidad del código en forma continua: SonarQube, CodeClimate, PHPStan, ESLint, Pylint: detectan bugs, complejidad, duplicación y malas prácticas. Cobertura de pruebas unitarias e integración Tasa de defectos por release Velocidad promedio por ticket o historia Tasa de errores en producción Estas métricas pueden transformarse en reportes ejecutivos que demuestran cómo las inversiones en buenas prácticas se traducen en ahorro, confiabilidad y valor. ✅ Conclusión: la calidad del código es una inversión en resultados Para las empresas modernas, el código fuente no es solo un producto técnico: es un activo estratégico. Su calidad influye directamente en: El crecimiento del negocio La eficiencia de los equipos La experiencia del cliente La rentabilidad y sostenibilidad de la operación Invertir en estándares, cultura de calidad, automatización de pruebas y arquitectura sólida no es un lujo. Es una decisión gerencial inteligente que maximiza el valor de la tecnología como palanca de diferenciación y ventaja competitiva. En resumen, la calidad del código impacta directamente en los indicadores de negocio. Quien invierte en código limpio, invierte en el futuro de su empresa.
¿Cómo estructurar un plan de carrera para ingenieros de software en empresas tech-driven?
En un entorno donde el talento tecnológico se ha convertido en uno de los activos más escasos, competitivos y determinantes del éxito empresarial, estructurar un plan de carrera para ingenieros de software no es solo una iniciativa de recursos humanos: es una estrategia organizacional clave para el crecimiento sostenible, la retención del talento y el desarrollo de productos tecnológicos de alto impacto. Las empresas tech-driven, aquellas cuyo core de negocio depende de la tecnología, necesitan más que buenos salarios para atraer y retener talento. Necesitan ofrecer trayectorias profesionales claras, retadoras, personalizadas y alineadas con los intereses del negocio. Un ingeniero sin un plan de carrera definido es un profesional que, tarde o temprano, migrará a una organización que sí se preocupe por su crecimiento. A continuación, se expone cómo un director de tecnología (CTO), un gerente de ingeniería o un área de desarrollo organizacional puede diseñar un plan de carrera sólido, motivador y adaptado a la dinámica de las organizaciones tecnológicas modernas. 1. El plan de carrera como motor de retención y rendimiento Antes de hablar de frameworks o niveles, es fundamental entender por qué el plan de carrera es vital en empresas de base tecnológica: Los ingenieros valoran más la evolución profesional que los beneficios tangibles de corto plazo. Los entornos ágiles requieren autonomía y crecimiento constante. Un profesional sin perspectiva se desmotiva, disminuye su rendimiento y finalmente abandona la organización. Impacto empresarial: Un plan de carrera bien estructurado disminuye la rotación, potencia la motivación y acelera la formación de equipos de alto rendimiento, lo cual se traduce en mayor eficiencia, mejor calidad del producto y menores costos de reclutamiento. 2. Diseño de la estructura: caminos técnicos y caminos de liderazgo Una práctica fundamental es definir dos rutas de desarrollo distintas pero igual de valoradas: A. Ruta técnica (IC – Individual Contributor) Ideal para ingenieros que desean profundizar en lo técnico sin necesariamente liderar personas. Algunas posiciones en esta línea podrían ser: Junior Developer Mid-Level Developer Senior Developer Staff Engineer Principal Engineer Distinguished Engineer Cada nivel incluye mayores competencias en arquitectura, diseño, calidad, impacto técnico y mentoring de pares. B. Ruta de liderazgo (Managerial Track) Diseñada para ingenieros que quieren evolucionar hacia roles de liderazgo. Ejemplos: Team Lead Engineering Manager Senior Engineering Manager Director of Engineering VP of Engineering CTO Aquí se valoran competencias como gestión de equipos, visión estratégica, entrega de producto, desarrollo de personas y manejo presupuestario. Claves del éxito: Ambas rutas deben tener equivalencia jerárquica y salarial. El mensaje debe ser claro: liderar personas no es más valioso que liderar tecnología. 3. Definición de niveles y expectativas Cada nivel dentro del plan de carrera debe ir acompañado de una matriz clara de expectativas que incluya: Conocimientos técnicos (lenguajes, frameworks, paradigmas) Soft skills (comunicación, trabajo en equipo, pensamiento crítico) Responsabilidad en proyectos (complejidad, autonomía, impacto) Contribución al negocio (alineación con objetivos estratégicos) Aporte a la cultura técnica (mentoring, documentación, buenas prácticas) Ejemplo: Un Senior Engineer podría tener como expectativa: Liderar técnicamente proyectos medianos Documentar buenas prácticas Hacer code reviews de alto valor Participar en definiciones arquitectónicas Mentorizar a perfiles junior Esto permite que el profesional sepa qué se espera de él, qué debe aprender y cómo puede ascender. 4. Evaluaciones periódicas basadas en crecimiento, no solo en entregables Los planes de carrera deben estar conectados con un sistema de evaluación estructurado, justo y transparente. Este sistema puede considerar: Autoevaluación + evaluación del manager Revisión por pares (360º técnica) KPIs de mejora (bugs, tiempo de entrega, calidad del código) Logros relevantes (proyectos liderados, soluciones innovadoras, impacto en negocio) Desarrollo de nuevas competencias La clave está en que la evaluación no mida solo la productividad, sino la evolución de capacidades alineadas al plan de carrera. 5. Apoyo desde la organización: mentoring, capacitación y visibilidad Un plan de carrera no se sostiene solo con títulos. Requiere acciones concretas que faciliten el crecimiento: Mentoring técnico con perfiles senior Presupuesto anual de formación Rotación entre equipos o proyectos para ampliar experiencia Charlas internas, hackatones, tech talks Acceso a herramientas modernas y retos tecnológicos reales Además, se debe generar visibilidad del progreso: reconocer públicamente promociones, compartir hojas de ruta de crecimiento y brindar feedback continuo. 6. Personalización: no todos avanzan igual Cada ingeniero tiene una historia, intereses y ritmos diferentes. El plan de carrera debe permitir: Transiciones entre rutas (de IC a liderazgo, o viceversa) Flexibilidad para ajustar tiempos de promoción Incorporación de intereses personales (investigación, producto, arquitectura, seguridad) El mensaje debe ser: el plan está para guiar, no para encorsetar. Así se genera compromiso genuino, no presión improductiva. 7. Alineación del plan con los objetivos estratégicos del negocio Un plan de carrera no debe ser solo un documento interno de TI. Debe estar alineado a los objetivos de la empresa: Si la organización busca escalar, debe formar líderes técnicos y managers con visión de negocio. Si se apunta a la innovación, se necesitan expertos en arquitecturas modernas, investigación, integración de nuevas tecnologías. Si el foco es la eficiencia, se requieren ingenieros orientados a automatización, calidad y mejora continua. Esta alineación garantiza que la evolución profesional impacte directamente en los resultados corporativos. 8. Indicadores para medir el éxito del plan de carrera Desde el nivel directivo, se deben monitorear métricas que evidencien el valor del plan: Tasa de rotación técnica anual Nivel promedio de seniority Tiempo medio para promociones Porcentaje de ingenieros en desarrollo activo de su carrera Clima laboral técnico (medido con NPS o encuestas internas) Nivel de adopción de buenas prácticas y calidad de código Estos indicadores permiten corregir el rumbo, justificar presupuestos y conectar el desarrollo humano con el éxito empresarial. ✅ Conclusión: el plan de carrera como ventaja competitiva Diseñar un plan de carrera para ingenieros de software en una empresa tech-driven no es un lujo. Es una estrategia de retención, motivación, escalabilidad y eficiencia. En un mercado donde el talento tecnológico decide dónde quedarse según su oportunidad de crecer, ofrecer una ruta clara, flexible, motivadora y bien respaldada es una de las decisiones más inteligentes que puede tomar el liderazgo. Un equipo que sabe hacia dónde va, que entiende cómo crecer y que ve cómo su trabajo impacta el negocio, no solo se queda, sino que se transforma en el motor del cambio y la innovación empresarial. Porque, al final del día, las tecnologías cambian. Pero el talento que sabe crecer con ellas es el que asegura el futuro.
¿Qué tecnologías emergentes deben considerar los directores de TI en sus roadmaps?
En un entorno empresarial cada vez más dinámico, competitivo y dependiente de la tecnología, los directores de tecnología (CTOs), CIOs y responsables de sistemas tienen un reto claro: no solo deben gestionar la operación tecnológica actual, sino anticiparse al futuro y trazar un roadmap de innovación que habilite nuevas ventajas competitivas. El rol del director de TI ha dejado de ser meramente operativo para convertirse en un agente estratégico del negocio. Esto significa que debe estar en constante vigilancia de las tecnologías emergentes que podrían transformar procesos, reducir costos, aumentar productividad, mejorar la experiencia del cliente o abrir nuevas líneas de negocio. A continuación, presentamos un análisis detallado de las tecnologías emergentes que los líderes de TI deben considerar en sus roadmaps 2025-2030, con un enfoque en cómo se alinean con los objetivos estratégicos del negocio. 1. Inteligencia Artificial Generativa y Aplicada (IA) La inteligencia artificial ha dejado de ser una promesa lejana para convertirse en una palanca de productividad inmediata. Tecnologías como modelos de lenguaje (LLMs), visión por computadora, clasificación predictiva, análisis de sentimiento o automatización cognitiva ya están siendo aplicadas en: Atención al cliente automatizada (chatbots inteligentes) Análisis de datos para toma de decisiones Generación de contenido automático (textos, imágenes, código) Mantenimiento predictivo en industrias operativas Automatización de procesos administrativos Por qué incluirla en el roadmap: La IA puede reducir drásticamente el trabajo repetitivo, aumentar la personalización en canales digitales, mejorar la eficiencia operativa y ofrecer ventajas competitivas únicas. 2. Edge Computing A medida que los dispositivos IoT y los sensores proliferan, y se requiere procesar datos más cerca de donde se generan, la computación en el borde (edge computing) se convierte en una alternativa a la latencia y los costos del cloud centralizado. Aplicaciones como: Vehículos conectados Smart cities Dispositivos médicos Monitoreo de fábricas en tiempo real ... requieren que el procesamiento ocurra en el punto más cercano al evento, no en un datacenter lejano. Por qué incluirla en el roadmap: Permite mayor velocidad de respuesta, menor carga en redes, reducción de costos y posibilidad de operar incluso sin conectividad constante. 3. Blockchain y Web3 Empresarial Aunque ha habido mucha especulación en torno a criptomonedas, la tecnología blockchain como estructura de datos distribuida, segura y transparente tiene aplicaciones reales en el mundo corporativo: Trazabilidad de la cadena de suministro Identidad digital verificable Smart contracts en procesos legales o financieros Gestión segura de registros sensibles (certificados, títulos, propiedad) Además, con la llegada de Web3, emergen nuevos modelos de propiedad, descentralización y gobernanza digital. Por qué incluirla en el roadmap: Permite aumentar la confianza, reducir intermediarios, asegurar procesos críticos y explorar modelos disruptivos de negocio. 4. Realidad Aumentada (AR) y Realidad Virtual (VR) Las interfaces digitales tradicionales están evolucionando hacia experiencias inmersivas, especialmente en sectores como: Capacitación técnica o médica Soporte remoto con RA (por ejemplo, en fábricas) Experiencia de cliente en retail (probar productos virtualmente) Visualización de datos tridimensionales Las tecnologías como ARKit, Meta Quest o Microsoft HoloLens están acercando estas capacidades al entorno empresarial. Por qué incluirla en el roadmap: Posibilitan nuevas formas de aprendizaje, asistencia y venta, generando engagement, eficiencia y diferenciación. 5. Automatización Inteligente (Hyperautomation) La automatización ha pasado de ser simple RPA (automatización robótica de procesos) a integrar IA, procesos empresariales, machine learning y herramientas sin código para orquestar procesos de punta a punta. Hyperautomation combina: Bots de procesos Decision engines Chatbots inteligentes Integración de sistemas legacy Analítica y optimización de procesos Por qué incluirla en el roadmap: Reduce costos operativos, acelera procesos y libera capital humano para tareas estratégicas. Fundamental para escalar operaciones sin aumentar proporcionalmente la estructura. 6. Plataformas de Bajo Código / Sin Código (Low-code / No-code) Estas plataformas permiten que perfiles no técnicos construyan aplicaciones, flujos, dashboards o integraciones sin escribir código, mediante interfaces visuales. Ejemplos: OutSystems, Mendix, Microsoft PowerApps, Bubble, Appgyver. Por qué incluirla en el roadmap: Habilitan agilidad en áreas de negocio, reducen la sobrecarga de TI, permiten prototipado rápido y fomentan una cultura de innovación interna. 7. Ciberseguridad Autónoma y Zero Trust La sofisticación de los ataques obliga a migrar desde esquemas tradicionales a modelos Zero Trust, donde cada usuario, dispositivo o servicio debe autenticarse y autorizarse continuamente. Sumado a esto, las herramientas de detección y respuesta automatizadas (XDR, SIEM con IA) permiten respuestas más rápidas y eficientes ante amenazas. Por qué incluirla en el roadmap: El riesgo reputacional, legal y financiero de un ataque exitoso exige una estrategia de seguridad proactiva, inteligente y automatizada. 8. Observabilidad y MLOps En sistemas complejos distribuidos, ya no basta con monitorear CPU y memoria. Se necesita observabilidad integral, que combine: Logs estructurados Métricas personalizadas Trazas distribuidas (Tracing) Dashboards ejecutivos en tiempo real Además, si se adoptan modelos de IA, deben gestionarse como productos: monitorear rendimiento, drift, sesgos, seguridad, versiones y entrenamientos. Esto lo logra MLOps, la práctica de operación de modelos de machine learning. Por qué incluirla en el roadmap: Permite mantener el control, la calidad y la confianza en sistemas complejos o con componentes inteligentes. 9. Computación Cuántica (preparación estratégica) Si bien todavía está en una etapa emergente, la computación cuántica promete resolver problemas que la computación clásica no puede, especialmente en: Criptografía avanzada Modelos moleculares (industria farmacéutica) Optimización logística Simulación financiera Por qué incluirla en el roadmap: No para adoptarla mañana, pero sí para monitorear avances, formar talento y desarrollar capacidades exploratorias. 10. Arquitecturas cloud-native y serverless La tendencia apunta a construir productos que no dependan de servidores físicos o configuraciones manuales, sino que sean: Autosuficientes Escalables Multinube Desplegables con CI/CD Resilientes por diseño Kubernetes, FaaS (Functions as a Service), containers y arquitecturas event-driven son componentes clave de esta transición. Por qué incluirla en el roadmap: Aumenta agilidad, reduce mantenimiento y mejora la elasticidad operativa. Clave para escalar sin fricción. ✅ Conclusión: innovación con visión estratégica Los directores de TI no deben adoptar tecnologías por moda, sino por valor concreto al negocio. El verdadero poder está en construir un roadmap tecnológico que equilibre la innovación con la estabilidad, el riesgo con la oportunidad, y lo técnico con lo estratégico. Incorporar tecnologías emergentes no significa reemplazar todo, sino explorar, pilotar, integrar y escalar aquellas que aportan ventajas competitivas claras. En un mundo donde la disrupción puede surgir de cualquier industria, quedarse con el stack actual sin evolucionar es más arriesgado que experimentar. Por eso, un roadmap tecnológico bien estructurado, informado y conectado con los objetivos del negocio es el mayor activo de cualquier líder de tecnología del siglo XXI.

¿Cómo garantizar la interoperabilidad entre diferentes plataformas tecnológicas?
La interoperabilidad entre plataformas tecnológicas es uno de los desafíos más críticos —y estratégicos— que enfrentan las organizaciones modernas. En un entorno empresarial donde conviven soluciones de múltiples proveedores, desarrollos propios, aplicaciones legacy y tecnologías emergentes, lograr que todos estos sistemas se comuniquen de forma fluida, segura y eficiente se ha convertido en un habilitador clave de la eficiencia operativa, la innovación y la transformación digital. Para los CTOs, CIOs y gerentes de arquitectura, la interoperabilidad no es solo un problema técnico: es una prioridad estratégica, porque de ella depende la capacidad de automatizar procesos, escalar operaciones, tomar decisiones basadas en datos y ofrecer experiencias consistentes al cliente. A continuación, exploramos cómo garantizar la interoperabilidad entre plataformas, desde la planificación estratégica hasta la implementación técnica, con foco en beneficios concretos para el negocio. 1. ¿Qué entendemos por interoperabilidad? La interoperabilidad es la capacidad que tienen distintos sistemas, plataformas o tecnologías para intercambiar datos y operar de forma conjunta, sin importar quién los haya desarrollado, dónde se ejecuten o cómo estén construidos. Esto puede implicar: Integración entre un ERP y un CRM Comunicación entre microservicios construidos en diferentes lenguajes Acceso compartido a bases de datos distribuidas Conexión entre aplicaciones cloud y sistemas legacy Sincronización entre plataformas internas y soluciones de terceros Nivel gerencial: la interoperabilidad permite que la empresa funcione como un ecosistema unificado, en lugar de una colección de silos desconectados. 2. Principales riesgos de una arquitectura no interoperable Cuando no se gestiona adecuadamente la interoperabilidad, surgen problemas como: Duplicación de datos y esfuerzos Inconsistencias entre sistemas Tiempos de respuesta lentos en procesos clave Dificultad para automatizar flujos de trabajo Dependencia de integraciones manuales o procesos semiautomáticos Mayores costos de mantenimiento y soporte técnico En resumen, se compromete la agilidad, la calidad del servicio y la capacidad de escalar del negocio. 3. Enfoque estratégico: interoperabilidad como parte del diseño arquitectónico Garantizar la interoperabilidad no es una tarea reactiva, sino que debe formar parte del diseño desde el principio. Para ello: Definir una arquitectura empresarial clara, que mapee las relaciones entre sistemas, sus entradas y salidas. Establecer un plan de gobernanza de datos e integraciones, que defina estándares, protocolos y responsables. Diseñar APIs como primera clase, asegurando que cualquier sistema nuevo pueda exponerse o consumir servicios. Claves del liderazgo tecnológico: Ver la interoperabilidad no como un “tema de IT” sino como una ventaja competitiva de la empresa. 4. Estándares y protocolos que habilitan la interoperabilidad Un principio clave para garantizar la interoperabilidad es adoptar estándares abiertos y protocolos ampliamente aceptados. Algunos ejemplos: REST, GraphQL y SOAP para intercambio de datos entre servicios. JSON y XML como formatos de datos comunes. OAuth 2.0 y OpenID Connect para autenticación federada. HL7 y FHIR en sectores como salud. EDIFACT y EDI en logística y manufactura. El uso de estos estándares permite que sistemas heterogéneos puedan integrarse sin reescrituras ni adaptaciones excesivas. 5. El papel central de las APIs Las interfaces de programación de aplicaciones (APIs) son el principal habilitador de interoperabilidad hoy. Una buena estrategia de APIs incluye: Diseñar APIs modulares, versionadas y seguras. Publicar documentación clara y actualizada (Swagger, Postman). Utilizar API gateways para controlar el tráfico, autenticación y rate limiting. Monitorear uso y rendimiento en tiempo real. Crear un catálogo interno de APIs para fomentar su reutilización. Nivel empresarial: una empresa que domina sus APIs puede integrar nuevos sistemas, partners o canales de distribución en semanas, no en meses. 6. Middleware, ESB y plataformas de integración En entornos más complejos, con decenas de sistemas, puede ser necesario implementar soluciones middleware o Enterprise Service Bus (ESB) para facilitar la interoperabilidad. Estas herramientas actúan como "traductores" entre sistemas con diferentes tecnologías. Ejemplos: MuleSoft Dell Boomi IBM App Connect Apache Camel WSO2 También se puede usar una arquitectura basada en eventos con tecnologías como Kafka o RabbitMQ, que permite desacoplar sistemas mediante colas de mensajes. Beneficio organizacional: reducción de complejidad técnica y aumento en la velocidad de integración. 7. Gestión del dato como eje de interoperabilidad Si los sistemas pueden hablar entre sí, pero los datos están mal estructurados, desactualizados o duplicados, la interoperabilidad pierde valor. Se debe trabajar en: Data governance: políticas claras de propiedad, calidad y seguridad de datos. Modelos de datos unificados: definir entidades comunes a toda la organización. Catálogos de datos y diccionarios corporativos: para facilitar su interpretación. Integración con herramientas de calidad de datos y master data management (MDM). Resultado esperado: los sistemas comparten no solo datos, sino significado, lo que es fundamental para evitar errores y automatizar procesos correctamente. 8. Seguridad, cumplimiento y auditoría en la interoperabilidad Una plataforma interoperable también debe ser segura. Toda integración debe considerar: Autenticación y autorización entre sistemas Cifrado de datos en tránsito (HTTPS, TLS) Registros de auditoría Protección contra abusos o uso indebido de APIs Además, se deben cumplir normativas como: GDPR / CCPA para privacidad de datos personales PCI-DSS si hay transacciones financieras SOX o ISO 27001 si se opera en sectores regulados La interoperabilidad sin seguridad es una puerta abierta al riesgo. 9. Observabilidad e indicadores clave Una arquitectura interoperable requiere ser observable. Para ello, se deben implementar herramientas que permitan: Monitorear transacciones entre sistemas Detectar errores o interrupciones en integraciones Medir tiempos de respuesta Generar alertas en tiempo real KPIs recomendados: Tasa de éxito en llamadas entre sistemas Latencia media en integraciones Frecuencia de errores por sistema Tiempo medio de resolución de incidentes en integraciones Estos indicadores permiten medir la salud del ecosistema tecnológico y tomar decisiones informadas. 10. Cultura organizacional y trabajo transversal Finalmente, la interoperabilidad no es solo técnica. Requiere colaboración entre áreas, estandarización de procesos y una cultura de trabajo transversal. Crear comités de arquitectura con participación de múltiples equipos. Establecer canales de comunicación entre equipos de sistemas, negocio y proveedores. Promover el uso de herramientas colaborativas para documentar, versionar y validar integraciones. Porque la interoperabilidad no se impone: se construye entre todos. ✅ Conclusión: interoperabilidad como motor de eficiencia y agilidad La interoperabilidad no es un lujo, ni una moda tecnológica. Es una condición estructural para que las organizaciones puedan innovar, operar con eficiencia y escalar con agilidad. Para garantizarla, los líderes tecnológicos deben: Adoptar estándares abiertos y APIs Diseñar arquitectura con enfoque integrador Invertir en middleware y gobernanza de datos Medir, asegurar y mejorar continuamente las integraciones En un mundo donde el éxito depende de conectar sistemas, procesos, personas y datos, la interoperabilidad es el lenguaje común de la transformación digital. Una empresa que domina esta capacidad, tiene menos fricción, más velocidad y mayor resiliencia. Y en tiempos de disrupción, eso lo es todo.

¿Qué implica implementar arquitectura hexagonal en entornos empresariales?
En un contexto donde los sistemas tecnológicos deben ser cada vez más escalables, mantenibles y adaptables al cambio, la arquitectura hexagonal (también conocida como puertos y adaptadores) se posiciona como un enfoque poderoso para construir software independiente de frameworks, tecnologías o bases de datos específicas, y alineado a los principios de diseño limpio. Para los CTOs, CIOs y arquitectos de software en entornos empresariales, la adopción de una arquitectura hexagonal no es una decisión meramente técnica, sino una estrategia organizacional que impacta directamente en la calidad del producto, la velocidad de entrega, la capacidad de evolución del sistema y la eficiencia de los equipos. A continuación, se desglosa en profundidad qué significa implementar arquitectura hexagonal en una organización, sus beneficios, desafíos y el impacto directo que genera en la transformación tecnológica empresarial. 1. ¿Qué es la arquitectura hexagonal? La arquitectura hexagonal, propuesta por Alistair Cockburn, plantea un modelo de diseño en el que: El núcleo de la aplicación (dominio) está aislado completamente del mundo exterior. Las interacciones con el exterior (bases de datos, APIs, interfaces gráficas, redes, etc.) se manejan a través de puertos y adaptadores, es decir, interfaces desacopladas. Este enfoque permite que el corazón del sistema no dependa de tecnologías externas. Los frameworks, bases de datos o canales de entrada y salida son simplemente adaptadores que pueden cambiarse sin afectar el núcleo del negocio. Desde una perspectiva empresarial, esto significa que la lógica más valiosa —la que define cómo gana dinero la empresa— queda protegida de los cambios tecnológicos inevitables. 2. Beneficios estratégicos para la empresa A. Mayor facilidad de mantenimiento Cuando el sistema está modularizado en capas independientes, es más fácil: Cambiar una tecnología sin reescribir todo el sistema. Detectar y corregir errores con precisión. Probar partes específicas sin afectar otras. Esto se traduce en costos de mantenimiento más bajos y tiempos de corrección más rápidos. B. Escalabilidad progresiva Los sistemas hexagonales permiten: Escalar vertical u horizontalmente módulos individuales. Exponer servicios internos a otros canales sin duplicar código. Añadir nuevos adaptadores (por ejemplo, una API REST o un bot conversacional) sin alterar el dominio. Esto acelera el time-to-market y facilita la diversificación de canales o productos. C. Independencia tecnológica Las organizaciones pueden: Cambiar de base de datos (por ejemplo, de MySQL a PostgreSQL) Migrar de un framework obsoleto a otro moderno Moverse de monolitos a microservicios Todo sin necesidad de reescribir la lógica del negocio. D. Alta capacidad de testing automatizado Como el dominio está aislado, se pueden escribir pruebas unitarias y de integración sin necesidad de levantar toda la infraestructura técnica, lo cual reduce los ciclos de validación y aumenta la calidad del software. 3. ¿Cómo se estructura una arquitectura hexagonal? En términos simples, la estructura es: Centro (Core): contiene las entidades, servicios del dominio, lógica de negocio pura. Puertos (Ports): son interfaces que representan las dependencias que el núcleo necesita o expone. Adaptadores (Adapters): implementan los puertos para integrarse con tecnologías externas. Por ejemplo: Un puerto de persistencia define operaciones como guardarPedido() o buscarCliente(). Un adaptador implementa este puerto usando MySQL, MongoDB o una API externa. Si mañana se cambia la tecnología, solo el adaptador se modifica, el dominio no se toca. 4. Aplicación práctica en entornos empresariales Ejemplo: plataforma de pedidos de una empresa retail Escenario tradicional: El módulo de pedidos depende directamente del ORM (por ejemplo, Eloquent o Doctrine), de un framework web y de un sistema de colas. Cualquier cambio en uno de estos componentes puede impactar el flujo completo. Con arquitectura hexagonal: La lógica de validación de pedidos, cálculo de descuentos y reglas de stock vive en el núcleo. Las interfaces para guardar pedidos, enviar confirmaciones o comunicar con logística están definidas como puertos. Hay adaptadores que implementan estas interfaces usando las tecnologías actuales. Resultado: Si mañana se quiere reemplazar la API de logística, se cambia el adaptador, no el corazón del negocio. Esto permite agilidad sin riesgo. 5. Desafíos en su implementación Aunque los beneficios son claros, adoptar arquitectura hexagonal también tiene desafíos: Curva de aprendizaje: requiere formación para que todos los equipos comprendan el patrón. Cambio cultural: rompe con la lógica de desarrollo tradicional (centrado en el framework). Sobrecarga inicial: al principio parece más complejo y puede aumentar el tiempo de desarrollo. Necesidad de disciplina técnica: requiere definición rigurosa de interfaces, contratos y responsabilidades. Recomendación para líderes: Iniciar con un módulo piloto, capacitar equipos, mostrar resultados concretos y escalar progresivamente. 6. Herramientas, tecnologías y lenguajes compatibles La arquitectura hexagonal es un patrón de diseño, no depende de un lenguaje o herramienta específica. Puede implementarse en: PHP (Laravel o Symfony desacoplado) Java (Spring Boot) .NET (C# con Clean Architecture) Node.js Python (con FastAPI o Flask desacoplado) Lo importante es adoptar principios como: Inversión de dependencias (Dependency Inversion Principle) Interfaces bien definidas Separación entre dominio y lógica técnica 7. Impacto en la organización y sus equipos Una empresa que adopta este modelo logra: Equipos más autónomos y especializados por contexto Mejor colaboración entre perfiles técnicos y de negocio Mayor flexibilidad para innovar sin miedo Disminución de dependencia de proveedores o tecnologías particulares Además, facilita la rotación de personal, la incorporación de talento nuevo y la sostenibilidad del producto a largo plazo. 8. Casos de uso donde es especialmente valiosa Reescritura progresiva de sistemas legados Plataformas con múltiples canales (web, móvil, chatbot) Integración con múltiples sistemas externos Soluciones SaaS con clientes que tienen requisitos distintos Productos con alta rotación tecnológica o crecimiento acelerado ✅ Conclusión: una apuesta a la sostenibilidad tecnológica Implementar arquitectura hexagonal en entornos empresariales no es simplemente un ejercicio de estilo arquitectónico. Es una decisión estratégica para construir software: Más mantenible Más adaptable Más robusto Más alineado con el negocio En un mundo donde la única constante es el cambio, este enfoque permite a las organizaciones evolucionar con control, escalar sin temor y mantener el corazón del negocio protegido ante cualquier disrupción tecnológica. Porque en la era de la transformación digital, la verdadera innovación no está solo en lo que se construye, sino en cómo se construye para durar.

¿Cómo liderar un proceso de reingeniería de sistemas core en empresas tradicionales?
La reingeniería de sistemas core —es decir, aquellos que soportan los procesos críticos de negocio como facturación, logística, finanzas, CRM o producción— es una de las tareas más complejas, riesgosas y transformadoras que puede liderar un CIO, CTO o director de sistemas. Y también una de las más necesarias. En muchas empresas tradicionales, los sistemas legacy fueron diseñados hace una o dos décadas, en tecnologías obsoletas, con arquitecturas monolíticas, documentaciones incompletas y alta dependencia de desarrolladores que ya no están en la compañía. Estos sistemas, si bien aún operan, limitan la innovación, afectan la escalabilidad y elevan el costo operativo. Liderar su transformación no es solo un proyecto tecnológico: es una estrategia corporativa que involucra a todas las áreas del negocio, cambia la cultura organizacional y habilita la competitividad futura. A continuación, te detallo cómo dirigir exitosamente un proceso de reingeniería de sistemas core en empresas tradicionales, combinando perspectiva gerencial, técnica y humana. 1. Reconocer que la necesidad de reingeniería es estratégica, no solo técnica Los sistemas core obsoletos generan: Procesos lentos, poco flexibles o manuales Integraciones costosas y frágiles con nuevas plataformas Pérdida de talento por tecnologías poco atractivas Incapacidad de innovar con rapidez El primer paso es redefinir el problema: no se trata de “modernizar un sistema viejo”, sino de liberar a la empresa del lastre que impide su evolución. Mensaje desde el liderazgo: Este no es un proyecto de TI, sino una iniciativa de transformación del negocio habilitada por tecnología. 2. Construir un caso de negocio sólido Antes de mover una sola línea de código, el liderazgo tecnológico debe armar un business case persuasivo, incluyendo: Costos actuales de mantener el sistema legacy Impacto operativo de sus limitaciones (errores, lentitud, procesos duplicados) Riesgos legales y de seguridad por falta de actualización Costos ocultos de integración o soporte Oportunidades de eficiencia, escalabilidad y nuevos ingresos si se moderniza Este caso debe expresarse en términos financieros, de crecimiento y competitividad, no solo en lenguaje técnico. Es la herramienta clave para obtener respaldo de la alta dirección y stakeholders. 3. Diagnóstico profundo del sistema actual Una reingeniería efectiva no parte de suposiciones, sino de un diagnóstico exhaustivo del sistema en uso. El equipo debe mapear: Módulos funcionales y sus dependencias Lenguajes y frameworks utilizados Integraciones con terceros (ERP, bancos, logística) Base de datos y calidad del modelo de datos Uso real del sistema por áreas y usuarios Documentación disponible (o ausente) Personas clave que conocen el sistema (aunque no estén en TI) Este diagnóstico permite definir el alcance real de la reingeniería, priorizar componentes y anticipar riesgos. 4. Elegir el enfoque de reingeniería adecuado Existen varios enfoques, según el nivel de riesgo que la organización puede asumir: A. Big Bang Reescribir todo desde cero y reemplazar el sistema actual en un solo evento. Alta velocidad, pero alto riesgo. Requiere mucha inversión y testing. B. Strangler Pattern (estrangulamiento progresivo) Se va extrayendo funcionalidad del sistema legacy hacia componentes modernos, módulo por módulo, hasta apagar el core antiguo. Permite evolución controlada. Ideal para organizaciones que no pueden interrumpir su operación. C. Wrap & Extend Se mantiene el sistema legacy y se construyen nuevas funcionalidades por fuera, integradas vía APIs o servicios. Menos invasivo, pero puede aumentar complejidad temporalmente. Recomendación para empresas tradicionales: El enfoque progresivo es el más viable. Minimiza el riesgo y permite aprendizaje continuo. 5. Formación de un equipo multidisciplinario Una reingeniería de esta magnitud requiere más que buenos desarrolladores. El equipo debe incluir: Arquitectos de software modernos Analistas funcionales con visión de negocio Líderes del área operativa involucrada Especialistas en legacy (aunque ya no desarrollen) DevOps para automatización QA para pruebas automáticas y regresión Project Manager o Scrum Master con experiencia en proyectos complejos Además, debe tener sponsorship directo de la alta dirección. 6. Redefinición funcional: modernizar procesos, no replicarlos Un error común es intentar replicar el sistema viejo “tal como está” pero con tecnología nueva. Eso traslada ineficiencias pasadas al futuro. Durante la reingeniería, se debe: Replantear procesos obsoletos o manuales Eliminar redundancias Estandarizar y simplificar reglas de negocio Incorporar automatización e inteligencia donde aplique Alinear la solución con objetivos actuales de la empresa El objetivo no es digitalizar el pasado, sino diseñar el futuro. 7. Gobernanza, metodología y control del proceso Un proyecto de esta envergadura requiere una metodología clara (ágil, híbrida o en cascada, según el caso) y una gobernanza que garantice: Reuniones de seguimiento frecuentes Reportes ejecutivos con KPIs (avance, riesgos, calidad) Gestión de cambios efectiva Comunicación transparente con todas las áreas Espacios de validación funcional con usuarios reales Los KPIs pueden incluir: % de funcionalidades migradas Reducción de errores críticos Incremento en performance Nivel de satisfacción de usuarios Ahorro operativo estimado 8. Gestión del cambio cultural y organizacional La reingeniería de sistemas core no falla por código, falla por personas. Es vital: Involucrar a los usuarios finales desde el inicio Comunicar objetivos, avances y beneficios Escuchar temores, resistencias y propuestas Capacitar a las áreas operativas en la nueva plataforma Alinear a los líderes funcionales como embajadores del cambio Sin cultura de transformación, no hay transformación tecnológica. 9. Migración y puesta en marcha El paso final debe ser cuidadosamente planificado. Requiere: Estrategia de migración de datos segura y validada Pruebas de rendimiento, estrés y funcionalidad en entorno real Plan de contingencia (rollback) ante fallos Capacitación final a usuarios Monitoreo intensivo en los primeros días El éxito de la puesta en marcha define la credibilidad del proyecto y la confianza en futuras modernizaciones. ✅ Conclusión: reingeniería como reinvención, no como reemplazo Liderar la reingeniería de sistemas core en una empresa tradicional es una de las tareas más desafiantes y estratégicas que puede asumir un líder de TI. Más que cambiar un software, se trata de repensar cómo opera la organización y cómo debe evolucionar para seguir siendo competitiva. Cuando se aborda con visión de negocio, planificación inteligente, equipos capaces y cultura colaborativa, este tipo de proyectos no solo mejoran la tecnología, sino que transforman la organización para enfrentar con éxito el futuro digital. Porque, al final, reingeniería no significa volver a hacer lo mismo con nuevas herramientas. Significa aprovechar la oportunidad de reconstruir mejor, más rápido y más alineado con lo que el mercado realmente necesita.
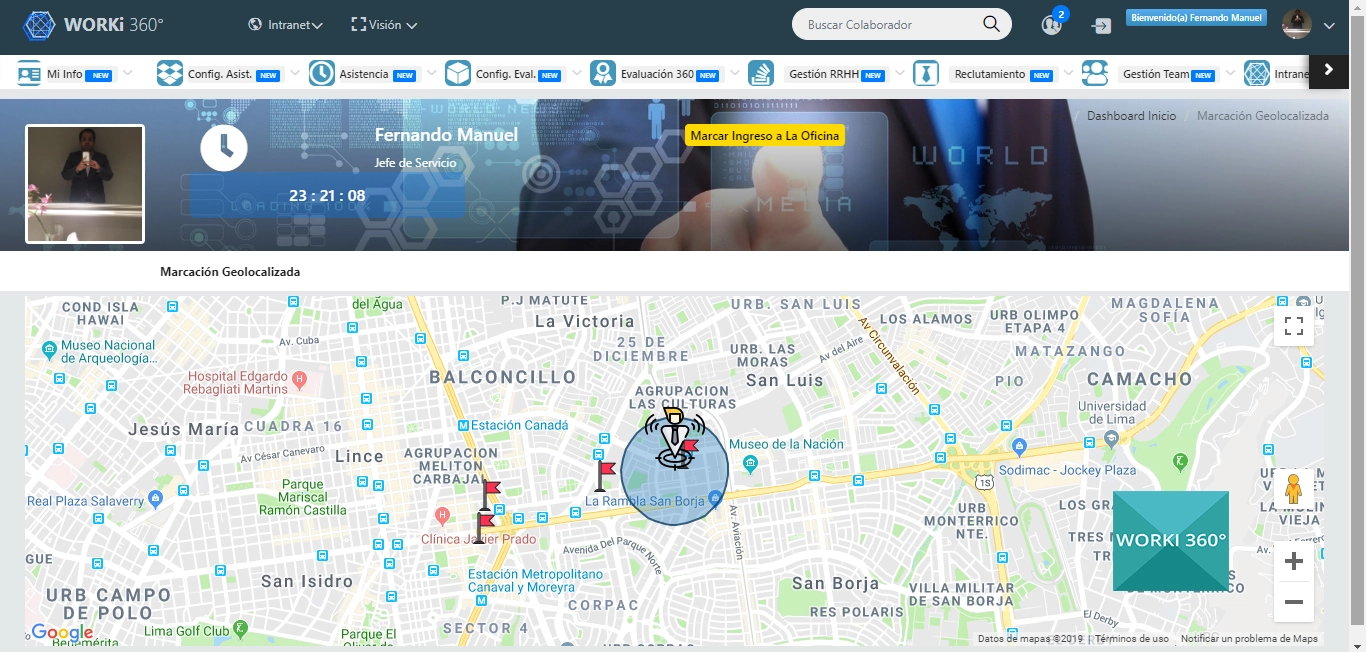
¿Qué metodologías ágiles se adaptan mejor a estructuras corporativas complejas?
En las grandes organizaciones con estructuras jerárquicas, múltiples departamentos, equipos distribuidos y sistemas legacy, la implementación de metodologías ágiles representa un desafío importante, pero también una oportunidad de transformación profunda. La agilidad ya no es exclusiva de startups o empresas tech; hoy en día, grandes corporaciones buscan volverse más flexibles, más rápidas y más centradas en el cliente. Sin embargo, para que la agilidad funcione en una estructura corporativa compleja, no basta con implementar Scrum en un equipo aislado. Se necesita una adaptación estratégica de los marcos ágiles a gran escala, con modelos de gobernanza, coordinación y liderazgo adecuados. A continuación, se presenta un análisis detallado de las metodologías ágiles más efectivas para entornos empresariales grandes, cómo elegirlas, sus ventajas y los retos que conllevan, todo desde una perspectiva ejecutiva. 1. Entendiendo el reto de “escalar la agilidad” Las estructuras corporativas complejas suelen presentar: Jerarquías verticales y múltiples niveles de aprobación Equipos distribuidos en distintas ubicaciones y husos horarios Proyectos con múltiples stakeholders, tecnologías y regulaciones Procesos internos rígidos (presupuestos anuales, auditorías, compliance) Sistemas heredados difíciles de adaptar Estas características dificultan la adopción ágil si no se adapta correctamente el marco metodológico. Conclusión clave: No existe una única metodología ágil que funcione universalmente en empresas grandes. La clave está en elegir, adaptar y escalar la metodología correcta según el contexto, la madurez del equipo y la cultura organizacional. 2. Metodologías ágiles más utilizadas en entornos corporativos A continuación, se presentan las metodologías y marcos de trabajo más efectivos para entornos complejos, explicando sus características y aplicación estratégica. A. SAFe (Scaled Agile Framework) Ideal para: empresas grandes con múltiples equipos trabajando en productos interdependientes. Características clave: Define niveles de agilidad: equipo, programa, solución y portafolio Introduce roles como Release Train Engineer, Product Management y Solution Architect Conecta la ejecución ágil con la estrategia de negocio Alinea equipos mediante PI Planning (planificación trimestral a gran escala) Ventajas para estructuras complejas: Facilita la sincronización de equipos Permite visibilidad desde la alta dirección hasta el equipo técnico Alinea objetivos de TI con estrategia empresarial Recomendación: SAFe es ideal para empresas donde se necesita gobernanza y visibilidad total sin perder velocidad en la entrega. B. LeSS (Large Scale Scrum) Ideal para: empresas que quieren escalar Scrum sin agregar demasiada complejidad. Características clave: Un único Product Owner para múltiples equipos Equipos trabajan sobre un único Backlog Enfocado en simplificación y entrega de valor Basado en principios ágiles puros Ventajas: Menor burocracia que otros marcos Fomenta la colaboración entre equipos Promueve la excelencia técnica Recomendación: LeSS funciona muy bien en empresas que ya dominan Scrum y quieren escalarlo manteniendo la agilidad sin estructuras jerárquicas nuevas. C. Disciplined Agile (DA) Ideal para: organizaciones con muchos tipos de equipos (TI, datos, diseño, infraestructura). Características clave: Enfoque pragmático: adapta prácticas según contexto y necesidades Incluye técnicas de Scrum, Kanban, Lean y SAFe Promueve el “tailoring” o personalización del marco metodológico Da libertad para elegir los caminos de trabajo más adecuados Ventajas: Flexibilidad total para entornos complejos Adopta principios DevOps, gobernanza y entrega continua Promueve la toma de decisiones basada en contexto, no en dogmas Recomendación: Ideal para empresas con entornos híbridos, donde un solo marco no es suficiente. D. Nexus (by Scrum.org) Ideal para: empresas que usan Scrum y desean coordinar hasta 9 equipos de forma estructurada. Características clave: Añade roles y eventos para escalar Scrum Utiliza un Backlog integrado Mantiene simplicidad sin perder control Ventajas: Rápido de implementar si ya se usa Scrum Facilita la detección de dependencias y bloqueos Requiere poca formación adicional Recomendación: Excelente para organizaciones que ya tienen Scrum funcionando y desean coordinar múltiples equipos con bajo overhead. E. Spotify Model Ideal para: empresas que buscan agilidad cultural, más allá de marcos rígidos. Características clave: Equipos organizados en “squads”, “tribes”, “chapters” y “guilds” Fomenta la autonomía con alineación Altamente flexible y adaptable Más un modelo organizacional que un framework Ventajas: Promueve la cultura ágil más que el proceso Alta autonomía de equipos Innovación descentralizada Recomendación: Funciona mejor en organizaciones con una cultura abierta, de confianza y responsabilidad. No es ideal como primer paso hacia la agilidad. 3. Factores clave para elegir la metodología correcta No se trata de copiar lo que hacen otras empresas, sino de elegir en función de la realidad interna. Factores a considerar: Número de equipos: ¿cuántos trabajan en el mismo producto? Nivel de madurez ágil actual: ¿se está empezando o ya hay experiencia previa? Estructura organizacional: ¿centralizada o distribuida? Visión desde la alta dirección: ¿hay apoyo ejecutivo? Naturaleza del producto: ¿estático o en evolución constante? Necesidades de cumplimiento y auditoría: ¿cuánto control se requiere? 4. Buenas prácticas para la implementación exitosa No imponer, co-crear: involucrar a los equipos en la selección y adaptación del marco Formación continua: capacitar a líderes, stakeholders y equipos técnicos Adoptar roles ágiles con claridad: PO, SM, RTE según el caso Transparencia radical: tableros, métricas y feedback abiertos Governanza ágil: establecer mecanismos de toma de decisiones sin burocracia Cambio cultural progresivo: acompañar con coaching, comunicación y liderazgo empático 5. Indicadores de éxito en la adopción de agilidad empresarial Ciclo promedio de entrega (lead time) Velocidad de resolución de incidentes Nivel de satisfacción de usuarios internos y clientes Grado de autonomía de los equipos Cumplimiento de OKRs o KPIs estratégicos Reducción de retrabajos o errores post-producción Participación del negocio en ciclos de desarrollo ✅ Conclusión: agilidad adaptada, no adoptada La agilidad en entornos corporativos complejos no se trata de “ser más rápidos”, sino de entregar más valor, con mayor foco y adaptabilidad al cambio, sin perder control ni sacrificar calidad. No existe una única metodología ideal. Lo que sí existe es un principio clave: adaptar la agilidad al contexto, no al revés. Las empresas que logran esta adaptación —con visión estratégica, apoyo de la alta dirección y equipos empoderados— crean entornos capaces de aprender, evolucionar y liderar mercados, incluso en contextos altamente regulados o estructurados. Porque al final, la verdadera agilidad no está en la metodología elegida, sino en la capacidad de adaptarse con inteligencia a lo que el negocio realmente necesita.
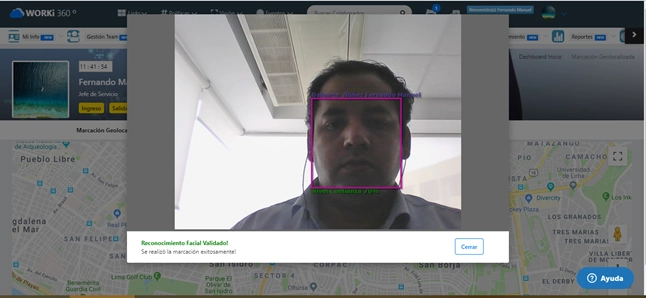
¿Cómo aplicar principios de arquitectura limpia en grandes organizaciones?
Aplicar principios de arquitectura limpia (Clean Architecture) en una organización grande y compleja no es solo una decisión técnica, sino una estrategia profunda de sostenibilidad tecnológica, escalabilidad y alineamiento entre TI y negocio. Este enfoque, promovido por Robert C. Martin (Uncle Bob), busca que el sistema sea independiente de frameworks, bases de datos, interfaces y detalles técnicos, poniendo en el centro la lógica de negocio y su estabilidad a largo plazo. Para CTOs, CIOs, gerentes de arquitectura y líderes técnicos, implementar arquitectura limpia implica redefinir cómo se construyen, mantienen y escalan los productos de software, con impactos directos en la productividad, el time-to-market, la calidad del producto y la retención de talento técnico. A continuación, desglosamos cómo implementar arquitectura limpia en empresas grandes, los beneficios, desafíos, mejores prácticas y su impacto organizacional desde una visión estratégica. 1. ¿Qué es la arquitectura limpia y por qué importa? La arquitectura limpia plantea una estructura de software basada en capas concéntricas, donde: El centro contiene la lógica del negocio (entidades, reglas, casos de uso). Las capas externas contienen los detalles de implementación (frameworks, bases de datos, interfaces web, etc.). La dependencia solo fluye hacia el centro, es decir, los detalles dependen de la lógica, y nunca al revés. Esto permite construir sistemas: Más fáciles de mantener Altamente testeables Independientes de la tecnología Más robustos frente al cambio Con mayor cohesión de negocio Mensaje clave para entornos corporativos: Este modelo protege el core del negocio ante cambios en la tecnología, lo que permite evolucionar sin necesidad de reescribir todo. 2. Principios clave que guían la arquitectura limpia Para implementarla con éxito, es fundamental comprender y aplicar los principios base: Separación de responsabilidades: cada capa tiene una función bien definida. Inversión de dependencias (DIP): los módulos de alto nivel no deben depender de módulos de bajo nivel, sino de abstracciones. Aislamiento del dominio: el core de la aplicación no debe tener referencias a frameworks, bases de datos ni librerías externas. Simplicidad estructural: evitar acoplamientos innecesarios y dependencias circulares. Alta cohesión, bajo acoplamiento: los componentes del sistema deben ser autónomos, reusables y entendibles. 3. Estructura típica de una arquitectura limpia Aunque puede variar, una estructura común en empresas grandes incluye: Entidad (Enterprise Business Rules) Contiene las reglas de negocio más estables y genéricas (entidades, objetos de dominio). Casos de uso (Application Business Rules) Define la lógica específica de aplicación (qué se hace, en qué orden, con qué validaciones). Interfaz de entrada (Interface Adapters) Controladores, presentadores, mapeadores entre los modelos de dominio y los datos externos. Infraestructura (Frameworks & Drivers) Aquí viven las bases de datos, frameworks web, motores de colas, API REST, etc. Impacto empresarial: Al mantener la lógica del negocio aislada de los detalles técnicos, la organización gana velocidad para cambiar tecnologías sin tocar la esencia del sistema. 4. Beneficios para grandes organizaciones A. Sostenibilidad a largo plazo Los sistemas grandes tienen una vida útil de muchos años. Con arquitectura limpia, los cambios futuros son controlables, y el sistema se puede mantener sin depender de los mismos desarrolladores. B. Mayor velocidad de evolución Nuevas funcionalidades se integran con menos fricción y sin miedo a romper lo existente. La alta testabilidad facilita regresiones y validaciones rápidas. C. Independencia tecnológica Permite cambiar de framework, motor de base de datos, proveedor de servicios o interfaz de usuario sin reescribir la lógica de negocio. D. Facilidad de testing automatizado La arquitectura limpia promueve pruebas unitarias desde el core, sin necesidad de levantar servicios externos. E. Alineación entre negocio y tecnología El dominio del negocio se modela claramente, y los stakeholders no técnicos pueden entender la estructura de los sistemas. 5. Desafíos al implementar arquitectura limpia a gran escala Aunque poderosa, su adopción tiene retos, especialmente en estructuras corporativas complejas: Curva de aprendizaje técnica para equipos acostumbrados a arquitecturas acopladas Mayor complejidad inicial en la configuración de capas y dependencias Resistencia cultural de equipos que ven esta práctica como “overengineering” Mayor necesidad de disciplina para mantener las capas separadas y respetar principios Recomendación: No intentar migrar todo de golpe. Comenzar por proyectos piloto, capacitar a líderes técnicos y demostrar beneficios tangibles. 6. Estrategia de adopción para empresas grandes Formación del equipo técnico Capacitar a arquitectos, tech leads y developers senior en principios SOLID, arquitectura hexagonal y patrones de diseño. Elección de un proyecto piloto Idealmente un sistema nuevo, mediano, no crítico, donde pueda probarse el modelo sin presiones extremas. Definición de un marco de referencia común Estandarizar la estructura de carpetas, nomenclatura, interfaces y dependencias para todos los equipos. Integración con herramientas DevOps y CI/CD Aprovechar el desacoplamiento para facilitar los pipelines, testing, despliegues y auditoría de calidad. Medición de resultados Indicadores como tiempo de entrega, tasa de errores, cobertura de pruebas, satisfacción del equipo, pueden usarse para evaluar el impacto de la arquitectura. 7. Ejemplo de impacto real en la organización Antes (arquitectura tradicional): Una aplicación monolítica en .NET con lógica de negocio mezclada en controladores, dependiente de Entity Framework y con pruebas limitadas. Después (con arquitectura limpia): La lógica de negocio se aisló en su propia capa con casos de uso independientes. Las tecnologías se desacoplaron mediante interfaces. La interfaz web se reemplazó sin tocar el dominio. Se mejoró la cobertura de pruebas al 80%. El equipo redujo el tiempo de entrega de nuevas funcionalidades en un 35%. 8. Integración con microservicios y modernización legacy En empresas que usan (o quieren usar) microservicios, la arquitectura limpia es altamente compatible. Cada microservicio puede implementarse siguiendo este patrón, lo que: Mejora el mantenimiento de servicios individuales. Evita dependencias tecnológicas entre ellos. Aumenta la resiliencia del ecosistema. Además, puede usarse para modernizar aplicaciones legacy aplicando el patrón Strangler Fig, migrando funcionalidad por funcionalidad hacia una nueva arquitectura sin necesidad de reescribir todo de golpe. ✅ Conclusión: arquitectura limpia como decisión estratégica Adoptar arquitectura limpia en una organización grande no es una decisión técnica aislada. Es una forma de pensar el software como una inversión estratégica: estable, adaptable y centrada en el negocio. Permite construir productos más robustos, equipos más productivos, sistemas más escalables y empresas más resilientes. En un mercado donde la tecnología cambia constantemente, pero los principios sólidos perduran, la arquitectura limpia no es solo una tendencia: es una base sólida para la innovación sostenible. Porque al final, un software bien construido no es el que usa la tecnología más nueva, sino el que permite evolucionar sin miedo y entregar valor con consistencia.

¿Qué herramientas permiten orquestar múltiples microservicios en producción?
El éxito de un proyecto de software empresarial no depende únicamente de la tecnología empleada o del presupuesto asignado. Su verdadera columna vertebral está en las personas que lo construyen, lo lideran y lo mantienen. Formar un equipo de desarrollo robusto y equilibrado es una de las decisiones más estratégicas que puede tomar un CIO, CTO o gerente de tecnología. En entornos corporativos donde los sistemas deben ser escalables, seguros, mantenibles y alineados al negocio, la definición correcta de roles no solo optimiza el desarrollo, sino que reduce errores, mejora la comunicación y acelera la entrega de valor. A continuación, analizamos en profundidad los perfiles clave en un equipo de desarrollo empresarial, su importancia, responsabilidades, cómo se relacionan entre sí y qué impacto tienen sobre la eficiencia operativa y el retorno de inversión. 1. Arquitecto de software Rol estratégico. Define las decisiones estructurales de los sistemas. Es el responsable de que el producto sea escalable, mantenible, seguro y alineado con la visión tecnológica de la empresa. Responsabilidades: Definir patrones de arquitectura (monolito, microservicios, hexagonal, etc.) Seleccionar tecnologías base Diseñar la integración entre sistemas Garantizar cumplimiento de buenas prácticas Supervisar la calidad técnica de los desarrollos Impacto empresarial: El arquitecto reduce la deuda técnica, acelera el time-to-market y asegura la sostenibilidad tecnológica del producto. 2. Product Owner (PO) Puente entre el negocio y el equipo técnico. Representa los intereses del cliente, usuarios internos o stakeholders. Responsabilidades: Gestionar y priorizar el backlog del producto Entender y traducir necesidades del negocio Validar entregables junto a stakeholders Alinear la visión del producto con los objetivos de la organización Impacto empresarial: El PO asegura que cada línea de código tenga sentido estratégico, evitando desviaciones costosas o funcionalidades innecesarias. 3. Scrum Master / Agile Coach Facilita los procesos ágiles y remueve obstáculos que afectan al equipo. No lidera jerárquicamente, pero sí genera condiciones para el alto rendimiento. Responsabilidades: Guiar al equipo en la metodología ágil (Scrum, Kanban, SAFe) Moderar ceremonias (daily, sprint planning, retrospectivas) Promover la mejora continua Detectar cuellos de botella Proteger al equipo de interferencias externas Impacto empresarial: Mejora la productividad del equipo, reduce la fricción interna y acelera la entrega de valor. 4. Desarrollador Backend Responsable de la lógica del negocio, acceso a datos y procesamiento del sistema. Suele trabajar con APIs, bases de datos y servicios internos. Responsabilidades: Diseñar y desarrollar servicios y microservicios Implementar reglas de negocio Integrar con bases de datos y sistemas externos Garantizar seguridad y escalabilidad en la lógica del servidor Impacto empresarial: Construye el núcleo funcional del sistema. Su calidad y eficiencia determinan la robustez operativa del producto. 5. Desarrollador Frontend Se encarga de la interfaz visual y la interacción con el usuario final. Es clave en la experiencia digital del cliente interno o externo. Responsabilidades: Desarrollar componentes UI/UX Integrar APIs con diseño responsive Garantizar accesibilidad y rendimiento en el navegador Aplicar buenas prácticas de usabilidad y seguridad en la presentación Impacto empresarial: Una interfaz bien diseñada mejora la satisfacción del usuario, reduce errores y aumenta la adopción de los sistemas internos o externos. 6. QA Engineer / Tester Responsable de la calidad funcional y técnica del software antes de salir a producción. Actúa como garante de confianza. Responsabilidades: Diseñar e implementar casos de prueba Automatizar pruebas de regresión Realizar testing funcional, de carga, seguridad y usabilidad Reportar y documentar errores Impacto empresarial: Previene errores en producción, lo que reduce costos de soporte, pérdida de reputación o interrupciones operativas. 7. DevOps Engineer Conecta el desarrollo con las operaciones, automatizando procesos de integración, despliegue y monitoreo. Es clave para lograr entregas rápidas y seguras. Responsabilidades: Configurar pipelines de CI/CD Administrar infraestructura como código Gestionar entornos de testing, staging y producción Monitorear disponibilidad, rendimiento y logs Impacto empresarial: Acelera la frecuencia de releases, reduce errores en despliegues y habilita la escalabilidad automática de los sistemas. 8. UX/UI Designer Aunque a veces se subestima, este perfil define cómo los usuarios perciben y entienden el producto. Responsabilidades: Investigar necesidades de usuarios Diseñar wireframes, prototipos y flujos Validar hipótesis con pruebas de usabilidad Colaborar con frontend para asegurar coherencia visual Impacto empresarial: Mejora la eficiencia operativa, satisfacción del cliente y tasa de adopción de soluciones tecnológicas. 9. Data Engineer / Data Analyst (opcional, pero estratégico) Cada vez más organizaciones integran este perfil al equipo para construir soluciones basadas en datos. Responsabilidades: Diseñar pipelines de datos Garantizar calidad y disponibilidad de información Crear dashboards e indicadores clave Apoyar en decisiones estratégicas con insights reales Impacto empresarial: Permite tomar decisiones basadas en evidencias, optimizando procesos y anticipando oportunidades. 10. Tech Lead Lidera técnicamente al equipo de desarrollo. Es mentor, referente y decisor técnico. Responsabilidades: Revisar código Tomar decisiones sobre librerías, frameworks y arquitectura Asegurar coherencia técnica entre componentes Formar a desarrolladores más junior Ser el punto de contacto entre arquitectura y ejecución Impacto empresarial: Evita desviaciones técnicas, promueve la excelencia y mantiene al equipo alineado. 11. Business Analyst (BA) Actúa como traductor entre necesidades del negocio y soluciones técnicas. Aunque a veces se solapa con el PO, su rol es más analítico y táctico. Responsabilidades: Analizar procesos existentes Detectar oportunidades de automatización o mejora Especificar requerimientos funcionales Priorizar funcionalidades con stakeholders Impacto empresarial: Reduce el riesgo de malinterpretar necesidades del negocio, evitando desperdicio de recursos. ✅ Conclusión: sin los perfiles adecuados, no hay producto exitoso Un equipo de desarrollo empresarial no es solo un grupo de programadores. Es un conjunto orquestado de perfiles multidisciplinarios, cada uno con una función crítica para que el sistema funcione, crezca y cumpla con su propósito. El CIO o CTO debe ser consciente de que cada rol bien definido es una inversión que retorna en calidad, velocidad, innovación y sostenibilidad. Porque al final del día, la tecnología es tan buena como el equipo que la construye. Y un equipo equilibrado, con roles claros y liderazgo efectivo, es la mejor garantía de éxito en cualquier proyecto de software empresarial.
¿Qué tipo de liderazgo técnico se requiere para escalar productos tecnológicos?
En el contexto actual, donde las organizaciones buscan ser más ágiles, resilientes y escalables, los microservicios se han convertido en un modelo arquitectónico muy atractivo. Sin embargo, para los CTOs y directores de sistemas, la decisión de migrar o construir con microservicios no debe basarse en modas tecnológicas, sino en un análisis estratégico profundo que considere las verdaderas necesidades del negocio y las capacidades de la organización. Implementar microservicios con éxito va mucho más allá de la fragmentación del código. Implica repensar cómo se diseñan, despliegan, mantienen y escalan las aplicaciones, así como reorganizar equipos, procesos y responsabilidades. A continuación, exploramos en profundidad las consideraciones clave que un CTO debe tener al evaluar, diseñar e implementar una arquitectura de microservicios en un entorno empresarial. 1. ¿Qué son los microservicios (realmente)? Los microservicios son un enfoque arquitectónico que propone dividir una aplicación en múltiples servicios pequeños, autónomos y desplegables de forma independiente, donde cada servicio se encarga de una función específica del negocio. Características clave: Independencia de despliegue Propiedad de datos y lógica encapsulada Comunicación a través de APIs (REST, gRPC, eventos) Alta cohesión, bajo acoplamiento Escalabilidad individual de cada componente Para el CTO: Esto se traduce en flexibilidad para evolucionar componentes por separado, asignar equipos independientes y reducir riesgos de cambios globales. 2. Evaluar la madurez organizacional antes de adoptar microservicios Los microservicios no son para todos los contextos. Requieren una madurez técnica, cultural y organizacional que muchas empresas no tienen al inicio. Preguntas clave que un CTO debe hacerse: ¿Tenemos DevOps maduro (CI/CD, monitoreo, infraestructura ágil)? ¿Nuestros equipos pueden asumir ownership total de servicios? ¿Contamos con capacidad de automatización de pruebas, despliegues y rollback? ¿La lógica de negocio permite una división clara y coherente? ¿Estamos listos para asumir la complejidad operativa extra? Conclusión: Si la respuesta a varias de estas preguntas es “no”, se recomienda fortalecer la base organizacional antes de adoptar microservicios a gran escala. 3. Justificar el cambio con beneficios tangibles para el negocio Un CTO debe poder explicar por qué migrar a microservicios genera valor estratégico: Permite escalar partes específicas del sistema, reduciendo costos de infraestructura. Mejora el time-to-market al permitir que equipos trabajen de forma paralela e independiente. Aumenta la resiliencia: un error en un módulo no cae todo el sistema. Facilita experimentos y cambios tecnológicos graduales. Mejora la adaptabilidad frente a cambios del negocio. Mensaje para la alta dirección: Adoptar microservicios debe tener un retorno claro en velocidad, escalabilidad, disponibilidad o eficiencia operativa. 4. Definir correctamente los límites del dominio (Domain-Driven Design) El error más común en microservicios es dividir la aplicación sin entender el negocio. Se deben aplicar principios de Domain-Driven Design (DDD) para: Identificar Bounded Contexts: zonas funcionales bien delimitadas. Definir claramente qué datos y procesos pertenecen a cada microservicio. Evitar dependencias ocultas o duplicación de lógica entre servicios. Ejemplo: En un sistema de ecommerce, "Pedidos", "Pagos" y "Inventario" deben ser servicios separados con sus propias reglas y base de datos, no fragmentos de un mismo módulo. 5. Elegir el protocolo de comunicación adecuado Los microservicios pueden comunicarse entre sí de varias formas: Síncrona (REST, gRPC): fácil de implementar, pero puede generar dependencia y latencia. Asíncrona (mensajería/eventos – Kafka, RabbitMQ, NATS): mejora desacoplamiento, tolerancia a fallos y escalabilidad. Recomendación del CTO: Adoptar comunicación asíncrona entre servicios clave y reservar llamadas síncronas solo para operaciones críticas o de lectura rápida. 6. Consideraciones para la infraestructura y DevOps Un ecosistema de microservicios puede pasar de 5 a 100 servicios en producción. Esto requiere una infraestructura preparada para: Automatización de CI/CD (GitLab CI, Jenkins, ArgoCD) Orquestación con Kubernetes o plataformas como AWS ECS, GKE, etc. Observabilidad: logs centralizados, métricas, trazabilidad (Prometheus, Grafana, ELK, Jaeger) Seguridad entre servicios: mutual TLS, mallas de servicios (Istio, Linkerd) Gestión de secretos y configuración (Vault, SOPS, ConfigMaps) Impacto organizacional: El CTO debe asegurar que su equipo tiene competencias en DevOps, o bien considerar alianzas con proveedores externos. 7. Garantizar la consistencia de datos En una arquitectura distribuida, la consistencia fuerte es difícil de mantener. Por eso se adoptan patrones como: Eventual Consistency Saga Pattern para coordinar transacciones distribuidas CQRS (Command Query Responsibility Segregation) Event Sourcing para reconstruir el estado del sistema desde eventos Decisión clave: El CTO debe liderar el diseño de un modelo de datos que no dependa de integridad transaccional global, priorizando disponibilidad y resiliencia. 8. Gobernanza y documentación A mayor cantidad de servicios, mayor riesgo de: Duplication de lógica APIs mal diseñadas Servicios inconsistentes Dificultad para nuevos integrantes del equipo Por ello, se debe implementar: Catálogo de servicios con ownership claro Documentación centralizada (Swagger, OpenAPI, Backstage) Reglas de versionado, validación y publicación de APIs Políticas de naming, logging y monitoreo unificadas Recomendación: Establecer una oficina de arquitectura o gobernanza técnica que supervise el ecosistema sin frenar la innovación. 9. Diseño organizacional orientado a equipos multidisciplinarios Un principio fundamental de microservicios es: “organiza los equipos como organizas tu arquitectura”. Cada equipo debe ser dueño de uno (o pocos) servicios. Equipos multidisciplinarios: frontend, backend, QA, DevOps, PO. Autonomía para desplegar y operar su componente. KPIs técnicos y de negocio alineados al microservicio. Beneficio: Equipos más motivados, responsables y capaces de entregar valor sin depender de otros. 10. Establecer KPIs e indicadores de éxito Para evaluar la efectividad de una arquitectura de microservicios, se deben monitorear indicadores como: Tiempo de despliegue por servicio Tasa de fallos en producción Tiempo medio de recuperación (MTTR) Uso de recursos por servicio Velocidad de entrega por equipo Satisfacción del usuario final Velocidad de onboarding de nuevos desarrolladores Conclusión del CTO: Si no se mejora la entrega de valor, la resiliencia y la adaptabilidad del negocio, entonces la arquitectura no está generando retorno. ✅ Conclusión: los microservicios no son el fin, sino el medio Adoptar microservicios no es una moda, ni una obligación para parecer “moderno”. Es una decisión estratégica que debe responder a una necesidad real del negocio: escalar, innovar, reducir fricción o acelerar la entrega. Un CTO que lidera esta transición debe: Evaluar la madurez interna Justificar el valor para el negocio Acompañar la evolución cultural y técnica Invertir en automatización y observabilidad Medir constantemente el impacto en valor entregado Porque al final, una arquitectura bien diseñada no es la más compleja, sino la que mejor resuelve los problemas del negocio de manera sostenible, flexible y segura. Y en ese camino, los microservicios son una herramienta poderosa, pero solo si se utilizan con inteligencia, estrategia y visión de largo plazo. 🧾 Resumen Ejecutivo Este artículo ha explorado, en profundidad y con enfoque gerencial, diez de las preguntas más relevantes en el ámbito de la ingeniería de software y sistemas computacionales, dirigidas a líderes de tecnología, directores de sistemas, CIOs, CTOs y equipos responsables de guiar la transformación digital en sus organizaciones. A continuación, se presenta una síntesis ejecutiva de los principales hallazgos y recomendaciones extraídas de cada una de las preguntas desarrolladas, con especial énfasis en su valor estratégico para organizaciones como WORKI 360, que buscan mantenerse competitivas, ágiles y preparadas para el futuro tecnológico. 1. Tendencias que redefinirán el futuro del desarrollo de software Las tecnologías emergentes como inteligencia artificial generativa, plataformas de bajo código, edge computing, realidad aumentada, automatización inteligente y arquitecturas nativas cloud están rediseñando la forma en que se desarrollan, operan y escalan los sistemas. Para WORKI 360, anticiparse a estas tendencias y alinearlas con sus objetivos de negocio es clave para mantener su liderazgo tecnológico. 2. Interoperabilidad entre plataformas tecnológicas La eficiencia operativa y la escalabilidad empresarial dependen cada vez más de una interoperabilidad robusta, basada en estándares abiertos, APIs bien diseñadas y una arquitectura modular. La implementación de middleware, gobernanza de datos y estrategias de integración flexible permitirá a WORKI 360 conectar sistemas legacy con soluciones modernas, garantizando fluidez e innovación continua. 3. Tecnologías emergentes en los roadmaps de TI CTOs y líderes de TI deben incluir tecnologías como IA aplicada, blockchain empresarial, computación cuántica emergente y observabilidad avanzada en sus planes estratégicos. No se trata de adoptar todo, sino de pilotar, validar e integrar tecnologías que ofrezcan retorno tangible. WORKI 360 puede beneficiarse especialmente de soluciones que aceleren decisiones con datos e inteligencia artificial. 4. Arquitectura hexagonal y su impacto empresarial La arquitectura hexagonal permite diseñar software independiente de la tecnología, favoreciendo la evolución sostenible. Este enfoque protege la lógica de negocio de los cambios tecnológicos. Para WORKI 360, adoptar esta arquitectura en nuevos desarrollos o como parte de una estrategia de modernización permitirá mayor flexibilidad, mantenibilidad y eficiencia en sus productos. 5. Liderar la reingeniería de sistemas core Actualizar sistemas legacy críticos requiere visión estratégica, gobernanza sólida y equipos multidisciplinarios. La reingeniería no solo implica reemplazar tecnología, sino redefinir procesos, estructuras y cultura organizacional. WORKI 360 puede liderar esta transición con enfoques progresivos, como el patrón Strangler, maximizando valor y minimizando riesgos. 6. Metodologías ágiles para estructuras complejas Marcos como SAFe, LeSS, DA y Nexus ofrecen distintos grados de gobernanza y escalabilidad para aplicar agilidad en organizaciones grandes. La elección debe basarse en el contexto de la empresa. WORKI 360 puede impulsar una cultura ágil adaptada a su estructura, con foco en autonomía, alineación estratégica y entrega continua de valor. 7. Arquitectura limpia en empresas grandes Aplicar principios de arquitectura limpia mejora la sostenibilidad, testabilidad y flexibilidad del software, separando la lógica de negocio de la tecnología externa. WORKI 360 puede estandarizar esta práctica para acelerar nuevos desarrollos, facilitar cambios tecnológicos futuros y construir soluciones resistentes al paso del tiempo. 8. Perfiles clave en equipos de desarrollo empresarial La definición correcta de roles como arquitecto, product owner, QA, DevOps, desarrolladores especializados, UX y analistas de negocio es esencial para el éxito de proyectos tecnológicos. WORKI 360 debe priorizar la formación de equipos multidisciplinarios bien coordinados, alineados con objetivos de negocio y con autonomía técnica. 9. Selección estratégica de arquitectura de microservicios La arquitectura de microservicios ofrece escalabilidad, resiliencia y agilidad, pero también exige madurez organizacional, inversión en DevOps y diseño basado en dominios. WORKI 360 debe evaluar con rigor su contexto antes de adoptar este enfoque, asegurando que genere valor real, no complejidad innecesaria. 10. Consideraciones clave para liderar la transformación tecnológica Desde la evaluación de tecnologías emergentes hasta la formación de equipos y el rediseño arquitectónico, los líderes tecnológicos deben integrar visión estratégica, capacidades técnicas y gestión del cambio. WORKI 360 puede posicionarse como referente en innovación, siempre que alinee su transformación digital con objetivos corporativos claros y métricas de valor bien definidas. 🎯 Conclusión Ejecutiva para WORKI 360 Las 10 preguntas abordadas revelan una verdad fundamental: la ingeniería de software y sistemas computacionales ha dejado de ser un soporte operativo y se ha convertido en el eje estratégico del crecimiento empresarial. Para una organización como WORKI 360, que busca mantenerse a la vanguardia, estas reflexiones permiten: Definir arquitecturas sostenibles y escalables Formar equipos técnicos alineados con el negocio Incorporar tecnologías emergentes con propósito Reducir la fricción entre innovación y operación Impulsar una cultura ágil adaptada a estructuras complejas Modernizar sistemas core sin afectar la continuidad del negocio La clave está en integrar lo técnico con lo estratégico, lo humano con lo tecnológico y lo innovador con lo sostenible. WORKI 360 no solo puede aplicar estas prácticas; puede liderar su adopción en el mercado, marcando el camino hacia una ingeniería de software verdaderamente centrada en el valor.