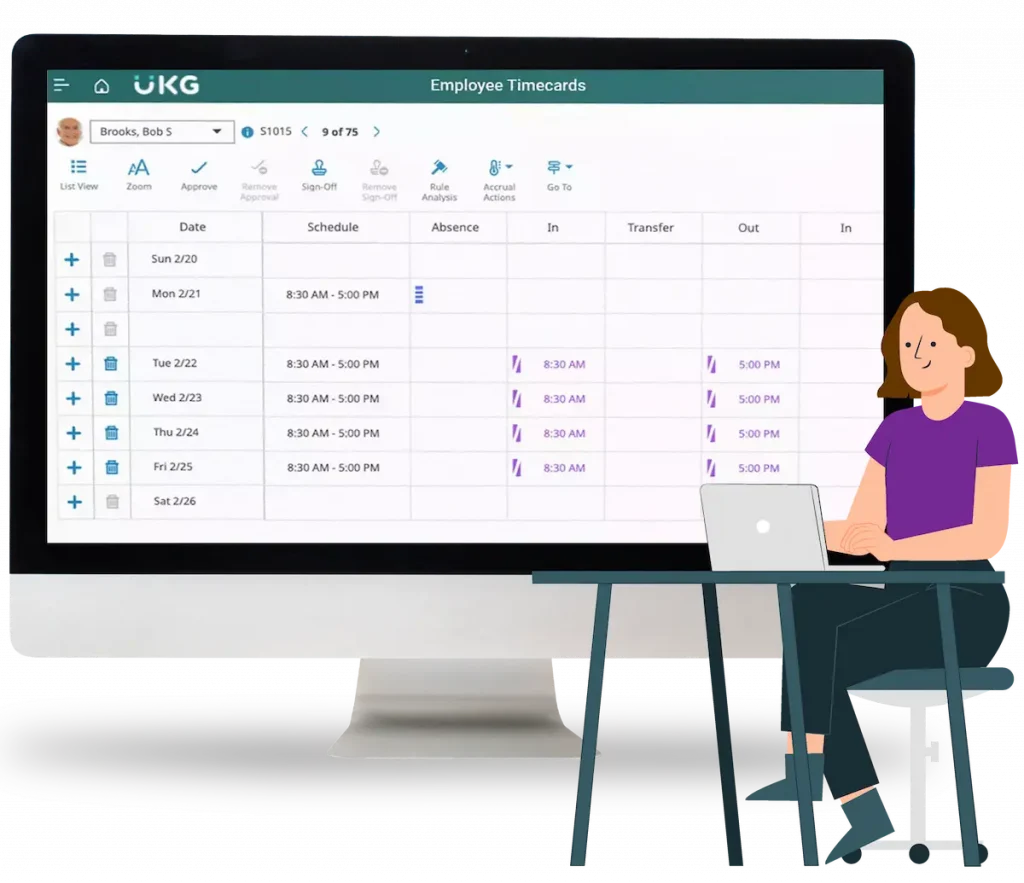

Índice del contenido
¿Cómo gestionar de manera centralizada la distribución masiva de PDFs a nivel global?
Introducción y storytelling gerencial
Imagina que tu organización tiene filiales en cinco continentes, miles de empleados y una red de partners que esperan recibir políticas internas, manuales de formación, reportes financieros y contratos en formato PDF. Antes, cada país gestionaba sus propios envíos: distintos horarios, distintos servidores de correo y sin control global. El caos de versiones, los documentos que no llegaban a tiempo y los problemas de compliance con regulaciones locales se acumulaban. Entonces, el equipo de Tecnología y Transformación Digital propuso un sistema centralizado de distribución de PDFs, unificando procesos y asegurando trazabilidad desde la sede corporativa. Ese fue el punto de inflexión para convertir un dolor operativo en una ventaja competitiva global.
1. Plataforma única de publicación y entrega
Implementar un Content Delivery Network (CDN) especializado en documentos: un CDN global garantiza que cada PDF se aloje cerca de la región del usuario final, reduciendo latencia y asegurando descargas rápidas.
Utilizar un gestor documental (DMS) cloud con API RESTful: de esta forma, los sistemas internos (ERP, CRM, LMS) pueden “empujar” documentos y definir destinatarios sin intervención manual.
Configurar reglas de negocio centralizadas: puedes definir, por ejemplo, que toda actualización de política de RR. HH. se distribuya automáticamente a gerentes de área vía correo seguro y notificación en la intranet.
2. Control de versiones y metadata enriquecida
Metadata obligatoria: al subir un PDF, el usuario debe completar campos como “Departamento Emisor”, “Fecha de Vigencia”, “Clasificación de Seguridad”.
Versionado automático: cada cambio genera una nueva versión numerada, con historial visible para auditorías internas e inspecciones regulatorias.
Etiquetas geográficas y lingüísticas: permite segmentar envíos por región o idioma, vital en empresas multiculturales.
3. Seguridad y compliance integrados
Autenticación federada (SSO/SAML): todos los empleados usan sus credenciales corporativas para acceder al repositorio global de PDFs.
Firma digital y sellado de tiempo: cada documento distribuido lleva un certificado que valida origen y fecha de publicación, esencial para evidencias legales.
Control de accesos basado en roles (RBAC): define quién puede ver, descargar o reenviar cada PDF, minimizando fugas de información y cumpliendo normativas como GDPR o HIPAA.
4. Monitoreo en tiempo real y analítica central
Dashboards globales: indicadores como tasa de descarga por región, tiempos de latencia, errores de entrega y cumplimiento de SLA.
Alertas automatizadas: por ejemplo, si un país no ha descargado un informe obligatorio en X días, se envía notificación a compliance y al gerente local.
Integración con SIEM: todos los eventos de acceso y descarga alimentan el sistema de seguridad, permitiendo detección de anomalías (descargas masivas inusuales, intentos de acceso no autorizados).
5. Workflow y automatización de distribución
Reglas de disparo: sube el PDF “Política de Seguridad 2025” y se dispara el envío al mailing de gerentes, con recordatorios cadenciados.
RPA para excepciones: casos especiales (contratos únicos, NDA) pueden canalizarse a bots que validan destinatario y generan certificados PDF personalizados.
Integración con plataformas de e-learning: manuales de formación en PDF se publican automáticamente como módulos de curso, con seguimiento de finalización.
6. Escalabilidad y resguardo ante desastres
Multi-región y replicación: cada documento se replica en al menos tres regiones geográficas, garantizando alta disponibilidad.
Backup continuo: snapshots diarios y retención a largo plazo en almacenamiento “cold” para auditorías históricas.
Pruebas periódicas de recuperación (DR drills): se simulan caídas de data center para validar los procedimientos y tiempos de restauración.
7. Alineación con la estrategia corporativa
Adopción cultural: campañas de comunicación interna que promuevan el uso de la plataforma única y eduquen sobre beneficios en velocidad, seguridad y trazabilidad.
KPIs gerenciales: medir reducción de tiempos de distribución (objetivo: –50 % en 6 meses), ahorro en costes de correo masivo y disminución de riesgos de compliance.
Evolución continua: roadmap de mejoras (soporte a nuevos formatos PDF interactivos, integración AI para clasificación automática, firma biométrica) alineado con objetivos de innovación.
Conclusión persuasiva para el directorio
La centralización de la distribución masiva de PDFs no solo optimiza procesos operativos: se traduce en ahorro de costos, mejora de la experiencia de usuario y fortalecimiento de la gobernanza documental. Con una plataforma robusta, segura y analítica, los gerentes pueden tomar decisiones basadas en datos reales de uso y cumplimiento, mientras Recursos Humanos y Legal reducen los riesgos de auditoría. Adoptar este enfoque es un paso estratégico para cualquier organización que aspire a ser realmente global, digital y compliant.
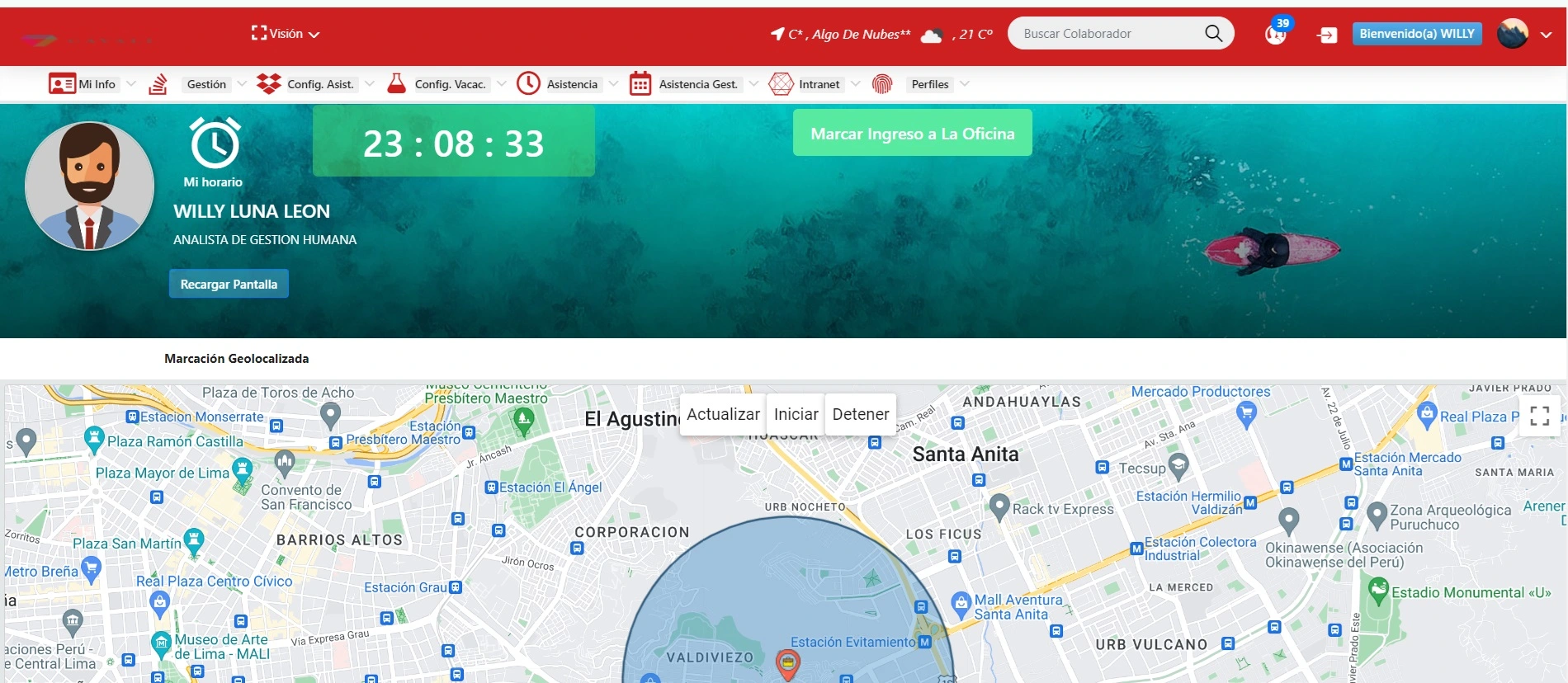
¿Qué métricas clave medir para evaluar la adopción de documentos PDF en la empresa?
Contextualización y storytelling Imagina que eres el director de Tecnología de Recursos Humanos de una gran compañía multinacional. Hace seis meses implementaron una solución integral de gestión y distribución de PDF: manuales de bienvenida, políticas de seguridad, formularios de evaluación de desempeño y contratos de confidencialidad. Ahora, el Comité Ejecutivo te pide datos concretos para demostrar el éxito del proyecto: “¿Cómo sabemos que la adopción está siendo efectiva?” En lugar de presentar solo cifras de descargas, conviene armar un set de indicadores estratégicos que reflejen no solo el uso, sino el valor real que la empresa obtiene de sus documentos digitales PDF. 1. Tasa de adopción de usuarios Definición: Porcentaje de empleados que acceden al repositorio o interactúan con PDFs en un periodo dado, respecto al total de la plantilla. Por qué importa: Indica directamente el nivel de penetración de la herramienta. Una adopción baja puede revelar falta de formación o problemas de usabilidad. Cómo medirlo: Registros de login únicos + eventos de apertura/visualización de PDF, segmentados por departamento y región. Meta recomendada: Alcanzar un 80 % de adopción activa en los primeros 3 meses tras el despliegue. 2. Frecuencia de interacción y hábitos de uso Definición: Número promedio de accesos o descargas de PDF por usuario activo en un periodo determinado. Por qué importa: Revela si el sistema se usa solo para tareas puntuales o se ha integrado en el flujo de trabajo diario. Cómo medirlo: Conteo de eventos “abrir”, “descargar”, “anotar” y “firmar” por usuario. Acción de mejora: Lanzar nudges o recordatorios automáticos para fomentar la consulta frecuente de políticas actualizadas. 3. Tiempo promedio hasta la primera interacción Definición: Duración media entre la publicación de un nuevo PDF y el primer acceso por parte de un usuario. Por qué importa: Cuanto más rápido acceden los usuarios, más efectiva es la comunicación interna y menor el riesgo de incumplimientos. Cómo medirlo: Timestamp de subida vs. timestamp de primer “view” por usuario. Benchmark: Menos de 48 horas en documentos críticos (políticas legales, seguridad). 4. Tasa de finalización de lectura o firma Definición: Porcentaje de usuarios que no solo abren el PDF sino que completan toda la paginación o la firma electrónica. Por qué importa: Distingue entre descargas superficiales y compromiso real con el contenido. Cómo medirlo: Eventos de scroll hasta la última página + hit de “firmar” en PDFs interactivos. Uso estratégico: Identificar documentos con baja finalización para optimizar contenido o formato. 5. Tasa de error y soporte Definición: Número de incidencias (errores de carga, problemas de visualización, fallos en firma) por documentos publicados. Por qué importa: La experiencia sin fricciones impulsa la adopción; un error recurrente ahuyenta a los usuarios. Cómo medirlo: Tickets de soporte, logs de error en la plataforma, feedback recogido en encuestas internas. Objetivo de calidad: Mantener errores por debajo del 1 % del total de interacciones. 6. Impacto en eficiencia operativa Definición: Reducción de tiempos y costes en procesos que antes dependían de documentos físicos (impresión, envío postal, archivado manual). Por qué importa: Traducir la adopción en beneficios económicos y operativos refuerza el ROI del proyecto. Cómo medirlo: Comparar tiempos “antes y después” en ciclos de contratos, gestión de nómina o auditorías, y calcular ahorros en papel e infraestructura. Ejemplo tangible: Menos X horas al mes en reimpresiones y escaneos, ahorros por valor de Y € anuales. 7. Nivel de compliance y auditoría Definición: Porcentaje de documentos requeridos por regulaciones que cuentan con firma válida, sellado de tiempo y registro de acceso. Por qué importa: Garantiza que la empresa cumple con normativas locales e internacionales (GDPR, SOX, HIPAA). Cómo medirlo: Informe de cumplimiento generado automáticamente: cantidad de PDFs críticos con metadatos completos vs. total. Beneficio añadido: Reducción de multas y sanciones por incumplimiento en auditorías externas. 8. Nivel de satisfacción de usuario Definición: Índice derivado de encuestas breves integradas en la plataforma post-descarga. Por qué importa: Mide percepción de usabilidad, utilidad del contenido y confianza en la herramienta. Cómo medirlo: Encuestas NPS (Net Promoter Score) o CSAT (Customer Satisfaction), con preguntas específicas sobre PDFs. Acción derivada: Plan de mejoras UX y formación adicional si la calificación baja del 70 %. 9. Retención y recurrencia de consulta Definición: Porcentaje de usuarios que regresan a consultar PDFs publicados en fechas pasadas. Por qué importa: Demuestra que los documentos son recursos de referencia, no simples envíos puntuales. Cómo medirlo: Usuarios con eventos de “abrir” en documentos de más de X semanas de antigüedad. Estrategia: Destacar en la intranet PDFs más consultados y promoverlos como “mejores prácticas”. 10. ROI global del sistema de gestión de PDFs Definición: Relación entre beneficios netos (ahorro costes, mejora en tiempos de proceso, reducción de riesgos) y la inversión total en la plataforma. Por qué importa: El Comité Ejecutivo requiere un indicador financiero sólido para validar futuras fases del proyecto. Cómo medirlo: Sumar ingresos o ahorros derivados – costes de licencias, infraestructura, formación – y expresar como porcentaje o múltiplo de retorno. Cierre persuasivo Midiendo estas métricas clave, no solo cuantificas el grado de adopción de PDFs en la organización, sino que traducen la transformación digital en resultados tangibles: mayor eficiencia, cumplimiento regulatorio y experiencia de usuario mejorada. Con un tablero de control (dashboard) alineado a estos indicadores, el equipo directivo puede tomar decisiones basadas en datos reales, ajustar planes de formación, priorizar mejoras técnicas y demostrar al Directorio el valor estratégico de la gestión documental digital en PDF. En definitiva, alinear tecnología, procesos y personas con métricas claras es el camino para convertir un formato de archivo en un motor de productividad y compliance.
¿Cómo se audita el acceso y la modificación de PDFs críticos en la organización?
Contexto y storytelling Hace un año, en la empresa GlobalTech, un incidente de seguridad puso en evidencia la falta de trazabilidad sobre quién consultaba y editaba los manuales de políticas internas en PDF. Una cláusula cambiada sin registro casi provoca una sanción por incumplimiento regulatorio. Ese día, el equipo de Auditoría y Seguridad decidió implementar un sistema riguroso de auditoría para todo PDF crítico, transformando un punto débil en un pilar de confianza para el Comité de Gobierno. 1. Definición del alcance y clasificación de documentos Identificar PDFs críticos: catálogo de documentos con alto valor legal, financiero o de cumplimiento (contratos marco, manuales de políticas, informes regulatorios). Asignar niveles de sensibilidad: Clasificación (pública, interna, confidencial, restringida) para determinar el nivel de detalle de auditoría requerido. Establecer propietarios y custodios: responsables de cada documento que validan qué acciones deben registrarse (aperturas, descargas, impresiones, ediciones). 2. Implementación de un sistema de logging centralizado Registro de eventos detallados (WORM): Write Once Read Many asegura que los logs no puedan alterarse una vez escritos. Tipos de eventos a capturar: Apertura y cierre de sesión en el visor de PDF. Descargas, impresiones y envíos por correo. Inserción de firma electrónica y sellado de tiempo. Modificaciones de contenido mediante herramientas de edición (anotaciones, comentarios, redacciones). Metadatos asociados: usuario, dirección IP, timestamp preciso (con zona horaria), cliente/versión de software, hash del documento antes y después. 3. Utilización de hash y firmas digitales para inmutabilidad Generación de hash criptográficos: al momento de crear o actualizar el PDF, calcular SHA-256 o SHA-512 y almacenar el valor en un repositorio seguro. Comparación periódica: auditorías automáticas que recalculan el hash en el PDF en reposo y comparan con el original para detectar alteraciones no autorizadas. Certificados digitales y PKI: cada firma inserta un certificado que valida autoría e integridad, creando una cadena de confianza auditable. 4. Integración con sistemas SIEM y DLP SIEM (Security Information and Event Management): centraliza logs de acceso y envía alertas en tiempo real ante patrones anómalos (descargas masivas, accesos fuera de horario). DLP (Data Loss Prevention): identifica flujos de datos sensibles y bloquea o marca documentos PDF con información crítica antes de que salgan de la red corporativa. Correlación de eventos: vincula actividad en PDFs con otros indicadores de riesgo (intentos de phishing, escalada de privilegios), enriqueciendo los informes de auditoría. 5. Dashboards y reportes gerenciales KPIs de auditoría: Número de accesos por documento y por perfil de usuario. Incidencias de integridad detectadas (hash mismatches). Alertas de comportamiento inusual (top 5 usuarios con más descargas). Visualización temporal: gráficas de tendencias semanal y mensual para anticipar picos inusuales y diseñar acciones preventivas. Informes periódicos: envíos automáticos a Compliance y al Consejo de Dirección con resumen ejecutivo y detalles de alta prioridad. 6. Procesos y roles en la auditoría Equipo de Seguridad IT: configura logging, SIEM y DLP; define reglas y umbrales de alerta. Auditor interno: revisa los logs y reportes, valida la conformidad con políticas y normas regulatorias. Responsables de área: analizan accesos a sus documentos críticos, responden a alertas y ejecutan acciones de mitigación (revocación de accesos, revisión de versiones). 7. Revisiones y auditorías externas Preparación de evidencias: exportar logs WORM y certificados digitales en formatos estándar (CSV, JSON) para los auditores externos. Simulacros de auditoría: ejercicios periódicos donde un tercero verifica la trazabilidad completa de un documento desde su creación hasta la última consulta. Feedback y mejora continua: incorporar recomendaciones de auditores en políticas y configuraciones, cerrando brechas detectadas. 8. Automatización y alerta temprana Reglas de alerta: notificaciones instantáneas cuando se detecta un acceso no autorizado, múltiples fallos de firma o intento de modificación fuera de proceso. RPA para respuestas: bots que bloquean temporalmente al usuario o revocan enlaces de descarga cuando se dispara una alerta crítica, hasta que un analista valide la situación. 9. Formación y cultura de compliance Capacitaciones obligatorias: formación a todos los usuarios sobre prácticas seguras de manejo de PDFs, riesgo de compartir enlaces sin control, importancia de la firma digital. Guías y manuales accesibles: documentación interna actualizada en PDF formativo, con checklist de auditoría que cada área puede autoevaluar. 10. Ciclo de mejora continua Revisión trimestral de políticas: ajustar niveles de detalle de auditoría según evolución de amenazas y cambios regulatorios. Evaluación de nuevas tecnologías: explorar blockchains privados para sellado de documentos, herramientas de análisis forense de PDF y AI para detección de modificaciones sutiles. Conclusión persuasiva Auditar el acceso y modificación de PDFs críticos no es solo un requisito de seguridad: es un pilar de confianza que refuerza la gobernanza corporativa. Con un sistema robusto de logging WORM, hash, SIEM/DLP, dashboards gerenciales y roles claros, el equipo directivo dispone de datos en tiempo real para prevenir incidentes y garantizar cumplimiento. Esta visibilidad convierte cada PDF en un activo trazable, fortalece la posición ante auditores externos y mitiga riesgos reputacionales y legales. Implementar esta estrategia es clave para proteger la información crítica y demostrar al Directorio que la gestión documental digital es, sin duda, una ventaja competitiva.

¿Qué soluciones de analytics permiten extraer insights de lotes de PDFs?
Contextualización y storytelling gerencial Hace unos meses, en una gran compañía de servicios financieros, el equipo de Auditoría detectó que existía un volumen inmenso de reportes en PDF acumulados sin analizar: años de estados financieros, contratos de clientes y documentos regulatorios. La información se almacenaba, pero no se aprovechaba para extraer tendencias, riesgos ocultos o indicadores de desempeño. El Director de Tecnología propuso entonces implementar una capa de analytics específica para PDFs, capaz de procesar lotes masivos y convertir texto disperso en dashboards accionables. En cuestión de semanas, lo que antes era un “cementerio documental” se transformó en un repositorio dinámico de insights que permitió optimizar la gestión de riesgos y mejorar la toma de decisiones estratégicas. 1. Ingestión y pre-procesamiento de lotes de PDFs Conectores especializados: herramientas que integran directamente con repositorios (SharePoint, DMS, AWS S3) para ingestar carpetas enteras de PDFs de forma automatizada. Control de calidad inicial: validación de integridad (checksum), detección de PDFs corruptos o encriptados y normalización de versiones (PDF/A para archivo). Pipeline de transformación: orquestación mediante frameworks como Apache NiFi o Talend para asegurar fiabilidad y trazabilidad de cada documento procesado. 2. Extracción de texto y OCR avanzado OCR híbrido: soluciones como ABBYY FlexiCapture o Tesseract mejorado con deep learning permiten capturar texto incluso en PDFs escaneados de baja resolución. Reconocimiento de estructuras: tablas, formularios y zonas de interés (cabeceras, pies de página) se extraen mediante modelos entrenados para identificar patrones específicos de cada tipo de documento. Normalización lingüística: limpieza de caracteres especiales, unificación de formatos de fecha y normalización de mayúsculas/minúsculas garantizan consistencia en el texto extraído. 3. Enriquecimiento de metadatos Etiquetado automático: herramientas de AI (Google Document AI, Azure Form Recognizer) que asignan categorías temáticas, entidades (nombres, fechas, montos) y niveles de confidencialidad. Reconocimiento de entidades y relaciones: uso de NLP para extraer personas, organizaciones, ubicaciones, y establecer vínculos (“Contrato X firmado por Cliente Y el 01/02/2025”). Georreferenciación y temporalización: si aplica, asignar coordenadas geográficas a menciones de lugares y normalizar las fechas a un mismo huso para análisis temporal. 4. Plataformas on-premise vs. cloud On-premise: ABBYY FineReader Server, Kofax Insight o soluciones basadas en Apache Solr + Tika, ideales para industrias con regulaciones severas sobre datos (banca, salud). Cloud services: AWS Textract + Comprehend para extracción de texto y análisis de sentimiento. Azure Form Recognizer + Cognitive Search para indexado y consultas semánticas. Google Document AI + AutoML para modelos personalizados de extracción y clasificación. Ventaja híbrida: combinar un gateway local para pre-procesar documentos sensibles y enviar solo metadatos o extractos mínimos a la nube. 5. Integración con BI y data-warehouses ETL a almacenes de datos: automatizar la carga de entidades y métricas derivadas de PDFs a un DWH (Snowflake, Redshift, Azure Synapse). Conectores nativos a Power BI, Tableau o Qlik: refresco programado de datasets que incorporan resultados de OCR, análisis de entidades y métricas propias (número de cláusulas, frecuencia de términos críticos). Dashboards interactivos: filtros por periodo, autor, cliente y tipo de documento, permitiendo desgloses en tiempo real. 6. Análisis avanzado con AI/ML Topic modeling: algoritmos LDA (Latent Dirichlet Allocation) para identificar clusters temáticos en grandes volúmenes de texto. Análisis de sentimiento y tono: detectar lenguaje adversarial o patrones de riesgo contractual mediante modelos entrenados con ejemplos de red flags. Clasificación supervisada: entrenar modelos que etiqueten automáticamente los documentos según riesgo, urgencia o categoría de negocio, reduciendo horas de revisión manual. 7. Soluciones de visualización de insights Narrativas automatizadas: plataformas como ThoughtSpot o Sisense que generan descripciones en lenguaje natural de tendencias detectadas (p. ej., “Se observó un incremento del 35% en cláusulas de indemnidad en contratos de 2024”). Heatmaps documentales: representaciones gráficas de las secciones más consultadas o con mayor número de modificaciones anotadas. Alertas y suscripciones: notificaciones vía email o Teams cuando se detectan cambios bruscos (picos de documentos marcados como “alto riesgo”). 8. Gobernanza, seguridad y compliance Enmascaramiento de datos sensibles: soluciones de DLP integradas en el pipeline de analytics que ocultan o redaccionan automáticamente datos personales o financieros antes del análisis. Control de acceso granular: integración con Active Directory/LDAP para definir quién puede ver insights agregados y quién puede profundizar en extractos de texto. Auditoría de pipelines: historial WORM de todas las transformaciones y análisis aplicados, con trazabilidad de cada dato extraído. 9. Casos de uso gerenciales Gestión de riesgos contractuales: monitorizar automáticamente cláusulas de renovación automática o penalizaciones y generar alertas al equipo legal. Optimización de procesos financieros: extraer montos, fechas de vencimiento y condiciones de pago para alimentar sistemas de tesorería, mejorando la gestión de cash-flow. Cumplimiento normativo: detectar patrones de no-conformidad en documentos regulatorios y reportar a Compliance antes de auditorías oficiales. 10. Escalabilidad y roadmap de evolución Arquitectura serverless: en la nube, aprovechar funciones (AWS Lambda, Azure Functions) para procesar cada documento de forma independiente y escalar según demanda. Feedback loop con usuarios: incorporar correcciones y etiquetas manuales para enriquecer continuamente los modelos de AI, mejorando la precisión. Exploración de tecnologías emergentes: blockchain para sello de tiempo descentralizado y validación de integridad, gafas de realidad aumentada para revisión colaborativa de PDFs en campo. Conclusión persuasiva para el Comité Ejecutivo Implementar soluciones de analytics para lotes de PDFs es mucho más que extraer texto: se trata de transformar información desestructurada en activos estratégicos. Con un pipeline que combina OCR avanzado, enriquecimiento de metadatos, plataformas de AI/ML y dashboards integrados en el ecosistema BI corporativo, los gerentes obtienen visibilidad total sobre riesgos, costos y oportunidades ocultas en sus documentos. Además, la gobernanza y la seguridad inherentes al proceso garantizan compliance y trazabilidad. Adoptar estas tecnologías posiciona a la organización como líder en eficiencia documental, maximizando el valor de sus activos de información y apoyando decisiones basadas en datos sólidos.

¿Cómo garantizar la confidencialidad de datos en PDFs compartidos externamente?
Contexto y storytelling gerencial
Imagina que la multinacional InnoBank lanza una nueva línea de crédito para PYMEs y necesita enviar, de forma masiva, contratos en PDF que contienen datos sensibles de sus clientes: montos de préstamo, datos fiscales y garantías. Sin un control estricto, esos PDFs podrían filtrarse, violando acuerdos de confidencialidad y exponiendo a la empresa a multas millonarias por incumplir GDPR y regulaciones locales. La Dirección de Riesgos encargó al equipo de Seguridad de la Información diseñar un marco sólido para proteger cada archivo PDF enviado a socios, auditores y clientes externos. Gracias a esa iniciativa, InnoBank pasó de temer fugas a presumir de un sistema que impide copias no autorizadas, tracking en tiempo real y blindaje criptográfico.
1. Encriptación de extremo a extremo
Cifrado en reposo y en tránsito: cada PDF debe almacenarse cifrado con AES-256 en el repositorio y transferirse a través de canales TLS 1.3 o superiores.
Llaves gestionadas por la empresa (BYOK): utilizar un sistema de gestión de claves (KMS) corporativo donde solo el departamento de Seguridad pueda generar, rotar y revocar llaves de cifrado.
Contenedores cifrados: cuando se requiera envío por correo o descarga directa, encapsular los PDFs dentro de un paquete cifrado (ZIP o contenedor PDF nativo) protegido con contraseña o certificado X.509.
2. Control de acceso basado en identidad y contexto
Autenticación fuerte (MFA): antes de permitir la descarga, el receptor externo debe validar su identidad con autenticación multifactor, preferiblemente combinando OTP móvil y certificado digital.
Access Control Lists (ACL) dinámicas: definir permisos por usuario o grupo, con caducidad automática y posibilidad de revocación inmediata.
Contextual Access Management: medir riesgo en tiempo real (ubicación, dispositivo, hora) y aplicar políticas adaptativas: por ejemplo, requerir re-autenticación si el acceso se produce desde una IP desconocida.
3. Gestión de derechos y DRM en PDFs
Digital Rights Management (DRM) especializado: soluciones como Adobe LiveCycle Rights Management o Vitrium Security permiten establecer restricciones granulares:
Impedir impresión o limitarla a X copias.
Bloquear la función de copiar/pegar texto.
Desactivar anotaciones o redacciones no autorizadas.
Fechas de expiración y caducidad: cada PDF puede programarse para dejar de abrirse automáticamente después de una fecha prevista o un número de visualizaciones.
Watermarking dinámico: incrustar marcas de agua visibles e invisibles con datos del receptor (nombre, correo) para disuadir la compartición no autorizada y facilitar la trazabilidad en caso de filtración.
4. Sellado de tiempo y firmas digitales
Certificados digitales PKI: firmar cada PDF con un certificado institucional que garantice origen e integridad.
Timestamping de confianza: agregar un sello de tiempo confiable (TSA) para establecer una cadena irrefutable de custodia y demostrar cuándo se creó o firmó el documento.
Evidencia forense: mantener un registro WORM de todas las firmas y sellados, de forma que cualquier alteración posterior sea fácilmente detectable en auditorías.
5. Compartición a través de plataformas seguras
Portales de intercambio con autenticación: usar portales dedicados (SharePoint Online, Box Shield, Citrix ShareFile) en lugar de correo electrónico genérico.
Enlaces de descarga con token único: cada link es de un solo uso o caduca al primer acceso, impidiendo reenvíos no controlados.
Notificaciones y tracking en tiempo real: alertas automáticas al emisor cuando se produce la apertura, descarga o intento fallido de acceso.
6. Data Loss Prevention (DLP) y monitoreo continuo
Inspección de contenido: los sistemas DLP escanean los PDFs antes del envío para detectar filtraciones de datos personales, financieros o estratégicos.
Bloqueo automático: en caso de identificar datos sensibles fuera de política (p. ej., números de tarjeta, SSN), el sistema impide la compartición o redirecciona el documento a revisión.
Reporte de incidentes: logs centralizados con detalles de quién, cuándo y cómo se intentó compartir información no autorizada, alimentando un SIEM para análisis de riesgos.
7. Auditoría post-distribución y trazabilidad
Logs WORM de acceso: cada evento (view, download, print) queda inmovilizado para garantizar rastreabilidad.
Dashboard de confidencialidad: KPIs como porcentaje de descargas legítimas vs. bloqueadas, tentativas de acceso rechazadas y documentos expirados.
Informes ejecutivos: envíos regulares a Compliance y Dirección de Riesgos con análisis de tendencias y recomendaciones de refuerzo de políticas.
8. Cumplimiento de regulaciones y normas
Alineamiento con GDPR, CCPA, HIPAA: las medidas de protección garantizan los derechos de los titulares de los datos y las obligaciones de notificación ante brechas.
Certificaciones ISO/IEC 27001: integrar el manejo de PDFs en el Sistema de Gestión de Seguridad de la Información, con auditorías periódicas para recertificación.
Políticas internas claras: manuales de uso de PDFs para personal interno y externos, definiendo niveles de clasificación, flujo de aprobación y sanciones por incumplimiento.
9. Educación y cultura de privacidad
Formación obligatoria: módulos e-learning centrados en mejores prácticas de envío de PDFs, identificación de phishing y uso de contraseñas seguras.
Guías rápidas y checklists: infografías en PDF para reforzar, paso a paso, cómo compartir de forma segura.
Campañas de concienciación: comunicaciones periódicas que destaquen incidentes reales (sin datos sensibles) y lecciones aprendidas para mantener alerta a los usuarios.
10. Mejora continua y evolución tecnológica
Revisión semestral de políticas y tecnologías: evaluar nuevas versiones de estándares PDF, algoritmos de cifrado y herramientas DRM emergentes.
Proof of Concept (PoC) de blockchain: explorar registros distribuidos para sellado de tiempo descentralizado y validación de integridad sin depender de un único proveedor.
Integración de AI para anonimización: soluciones que detectan y redaccionan automáticamente datos sensibles en PDFs antes de cualquier envío.
Conclusión persuasiva para el Directorio
Garantizar la confidencialidad de datos en PDFs compartidos externamente es un imperativo estratégico que va más allá de la tecnología: es un compromiso con los clientes, socios y reguladores. Al combinar cifrado de grado militar, DRM granular, control de acceso inteligente, DLP proactivo y una cultura organizacional enfocada en la privacidad, la empresa no solo mitiga riesgos de brechas y sanciones, sino que refuerza su reputación como líder consciente de la protección de la información. Implementar este marco robusto transforma cada PDF en un activo seguro, confiable y trazable, alineado con los objetivos de negocio y el compliance corporativo.

¿Cómo integrar la encriptación de PDFs con soluciones de PKI corporativa?
Contexto y storytelling gerencial
En MedTech Solutions, una empresa global de dispositivos médicos, la Dirección de Tecnología descubrió que los documentos PDF que contenían especificaciones técnicas, manuales de uso y resultados de ensayos clínicos circulaban sin una capa robusta de encriptación vinculada a la infraestructura de certificados corporativos. Esa carencia puso en riesgo el cumplimiento de normas como FDA 21 CFR Part 11 y ISO 13485, donde la trazabilidad y seguridad de los documentos críticos son esenciales. Así nació la iniciativa de integrar la encriptación de PDFs con la PKI (Public Key Infrastructure) interna, convirtiendo cada archivo en un contenedor seguro y confiable, alineado con los más altos estándares regulatorios.
1. Fundamentos de la PKI y su valor en la gestión documental
PKI como columna vertebral de confianza: la PKI corporativa gestiona el ciclo de vida de certificados digitales (emisión, revocación, expiración) y claves criptográficas, garantizando identidad, integridad y no repudio.
Certificados X.509 en PDFs: se utilizan para cifrar (encriptación asimétrica) y firmar digitalmente documentos, de modo que solo los destinatarios autorizados puedan descifrar y validar el contenido.
Elementos clave:
Autoridad de Certificación (CA): emite y firma certificados para usuarios y equipos.
Autoridad de Registro (RA): valida las solicitudes de certificado.
Repositorio de CRL/OCSP: lista de certificados revocados para verificar vigencia en tiempo real.
2. Diseño de la arquitectura de integración
Generación y gestión de certificados
Configurar la CA interna para emitir certificados de “Firma de documento” y “Cifrado de documento” con atributos específicos (key usage: digitalSignature, keyEncipherment).
Implementar RA automatizada para que usuarios y sistemas soliciten certificados desde portales autenticados (SSO).
Infraestructura de claves y almacenamiento seguro
Utilizar Hardware Security Modules (HSM) para almacenar claves privadas de la CA y de los usuarios de manera resistente a manipulaciones.
Integrar la PKI con el KMS de la nube (AWS KMS, Azure Key Vault) para sistemas híbridos, garantizando que las claves nunca abandonen el HSM.
3. Flujo de trabajo para encriptar un PDF
Pasos principales:
Selección de destinatarios: el emisor elige uno o varios certificados X.509 de los destinatarios autorizados.
Cifrado asimétrico: se genera una clave simétrica temporal (por ejemplo, AES-256), que a su vez se cifra con la clave pública de cada destinatario.
Empaquetado en el PDF: el contenedor PDF nativo incluye el contenido cifrado y los “envelope keys” cifrados por cada destinatario.
Registro de metadatos PKI: dentro de las propiedades del PDF se almacena información sobre la CA emisora, la cadena de certificación y la política de cifrado aplicada.
Herramientas recomendadas: Adobe Acrobat Enterprise, iTextPDF con módulo Bouncy Castle y SDKs de desarrollo de OpenSSL adaptados a flujos corporativos.
4. Automatización mediante APIs y servicios
Servicios de microservicios PKI
Exponer endpoints RESTful para:
Obtener certificados válidos (ListarCertificados).
Solicitar cifrado de documento (EncryptPDF), especificando certificado y nivel de protección.
Verificar vigencia de certificado (CheckRevocationStatus) antes de cifrar.
Integración con sistemas corporativos
ERP/CRM/LMS: añadir acciones automáticas post-generación de PDF para invocar el microservicio EncryptPDF con los certificados de clientes o empleados.
RPA: bots que detecten nuevos PDFs en carpetas de red y los envíen al servicio de PKI para su encriptación masiva y etiquetado posterior.
5. Gestión de acceso y descifrado
Requerimientos del receptor
Instalar en su visor de PDFs (Adobe Reader Enterprise o visor corporativo) el plugin de PKI que solicite la clave privada del usuario al HSM local o al KMS.
Autenticación MFA previa al uso de la clave privada para elevar la seguridad (certificado hardware, token U2F, biometría).
Procesos de descifrado
Validación de la cadena de certificados: el visor consulta la CA y el repositorio OCSP/CRL para asegurar que el certificado receptor no esté revocado.
Unwrapping de la clave simétrica: la clave pública descifra la clave simétrica, con la que se desencripta el contenido.
Auditoría de acceso: el visor registra un evento en el sistema de logging corporativo (siempre WORM) con timestamp, usuario y documento accedido.
6. Políticas y buenas prácticas de seguridad
Rotación de certificados: establecer periodos de validez breves (1–2 años) y procesos automáticos de renovación para evitar certificados expirados.
Revocación ágil: si un empleado se retira o un dispositivo se compromete, la CA revoca el certificado y el OCSP/CRL asegura que se impida cualquier acceso futuro a PDFs cifrados con esa clave.
Control de versiones de políticas: documentar y versionar las directrices de cifrado, uso de certificados y procesos de incidentes de seguridad.
7. Auditoría y monitoreo de la integración
Logs unificados
Capturar eventos de emisión, revocación, solicitud de cifrado y descifrado en un SIEM.
Analizar patrones de descifrado anómalos (p. ej., múltiples reintentos con certificados no válidos).
Dashboards de PKI
Indicadores clave: número de documentos cifrados por mes, certificados expirados, solicitudes de revocación y tiempo medio de emisión de certificados.
Alertas: cuando los procesos automáticos de cifrado fallen o existan certificados próximos a expirar.
8. Capacitación y cultura organizacional
Formación a usuarios finales: talleres prácticos sobre cómo usar certificados digitales en PDFs, gestionar HSM/KMS y resolver errores comunes.
Guías y manuales interactivos: PDFs auto-encriptados que enseñan a descifrar otros documentos, reforzando el aprendizaje.
Campañas de comunicación: newsletters trimestrales informando de nuevas políticas PKI, avisos de expiración y mejores prácticas.
9. Beneficios gerenciales y ROI
Reducción de riesgos: minimizar fugas de información y sanciones regulatorias gracias a un cifrado uniforme y gestionado centralmente.
Eficiencia operativa: automatizar el cifrado de PDFs reduce errores manuales y tiempos de espera, alineando procesos de TI y de negocio.
Visibilidad y control: los cuadros de mando sobre PKI permiten a los directores tomar decisiones informadas sobre renovación de infraestructuras y dimensionamiento de HSM/KMS.
10. Hoja de ruta de evolución
Integración con Blockchain para CTS: explorar registros distribuidos para almacenar metadatos de cifrado como un registro inmutable.
Adaptación a estándares emergentes: evaluar soporte para PDF 2.0 y algoritmos post-cuánticos para preparar la seguridad a futuro.
Expansión a otros formatos: aplicar la misma PKI corporativa a emails S/MIME, faxes electrónicos y contenedores Office cifrados.
Conclusión persuasiva
Integrar la encriptación de PDFs con la PKI corporativa no es solo un ejercicio técnico: es una estrategia que fortalece la confianza de clientes, socios y reguladores. Al aprovechar certificados X.509, HSM/KMS, microservicios RESTful y políticas de seguridad claras, las organizaciones logran un cifrado robusto, gestión ágil de claves y visibilidad total sobre acceso y uso de documentos críticos. Esta sinergia entre criptografía y gestión documental digital se traduce en un activo estratégico, reduciendo riesgos, mejorando la eficiencia y proporcionando un ROI tangible en protección y gobernanza de la información.
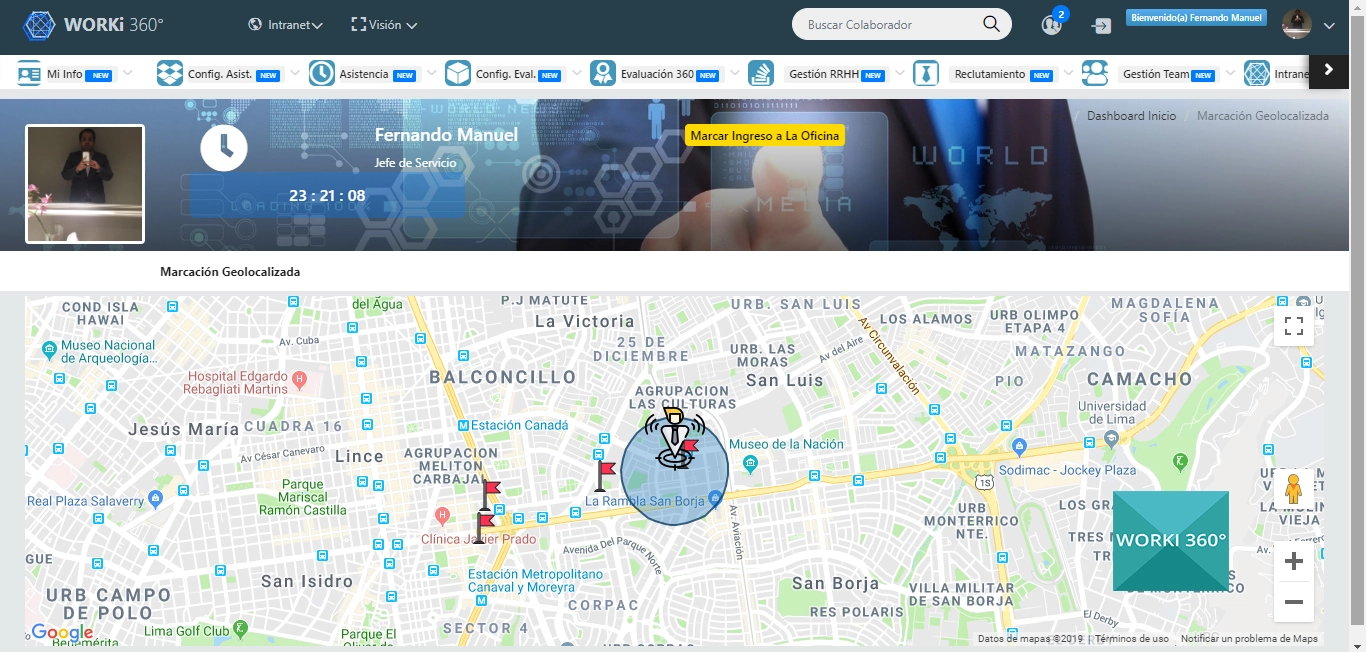
¿Qué estrategias de backup y recuperación específicos para PDFs críticos?
Contexto y storytelling gerencial
A inicios de 2024, la empresa GreenEnergy Corp sufrió un incidente de incendio en uno de sus centros de datos regionales en Europa, donde se almacenaban versiones maestras de manuales de operación y contratos regulatorios en formato PDF. La copia de seguridad de documentos generales se restauró sin mayores inconvenientes, pero los PDFs etiquetados como “críticos” —aquellos vinculados a acuerdos de suministro de energía, licencias medioambientales y protocolos de seguridad de planta— estaban desorganizados, con metadatos corruptos y sin claridad en las versiones. La Dirección de Operaciones advertía riesgos legales y de continuidad de negocio, y el Comité Ejecutivo exigió un plan de backup y recuperación infalible, específicamente diseñado para estos PDFs críticos. A partir de ese desafío, el equipo de Infraestructura diseñó un esquema que garantiza recuperación en minutos, integridad comprobable y trazabilidad total, asegurando que un evento catastrófico no vuelva a poner en riesgo la información más valiosa de la organización.
1. Clasificación y catálogo de PDFs críticos
Inventario y catalogación inicial: Crear un catálogo maestro de PDFs críticos, asignando a cada documento un identificador único, nivel de sensibilidad (por ejemplo, “Nivel 1: contratos regulatorios”, “Nivel 2: manuales de seguridad”) y responsable de custodia.
Metadatos de respaldo: Enriquecer cada entrada del catálogo con metadatos clave para recuperación: fecha de última versión, checksum SHA-256, tamaño de archivo y ubicación original en el DMS.
Política de retención y ciclo de vida: Definir cuánto tiempo deben conservarse las versiones antiguas (por ejemplo, retención de versiones principales por 10 años) y cuándo purgar copias obsoletas conforme al marco regulatorio.
2. Arquitectura de backup híbrida y georreplicada
Backup on-premise + nube:
On-premise para RTO ultrabajos: copias diarias incrementales y semanales full en un appliance de backup local (por ejemplo, Veeam o Commvault), permitiendo restaurar un PDF en minutos.
Backup en la nube (AWS S3 Glacier Deep Archive o Azure Archive Storage) para retención a largo plazo y protecciones contra desastres a nivel regional y global.
Replicación geográfica activa: Mantener réplicas sincronizadas en al menos dos regiones distintas (por ejemplo, Europa Oeste y América Norte), garantizando acceso aún si un centro de datos completo queda fuera de servicio.
3. Estrategias de versionado y snapshots
Versionado a nivel de objeto: Usar sistemas de almacenamiento que soporten versioning (S3 Versioning, Azure Blob Versioning) para guardar cada cambio importante en los PDFs críticos, permitiendo rollbacks a cualquier versión histórica.
Snapshots consistentes con aplicaciones: Coordinar snapshots de volúmenes de DMS o repositorios de documentos al nivel de base de datos, capturando el estado completo de metadatos y archivos PDF para restauración coherente.
Retención escalonada: Configurar políticas de snapshot:
Snapshots diarios retenidos 7 días.
Snapshots semanales retenidos 4 semanas.
Snapshots mensuales retenidos 12 meses.
Snapshots anuales retenidos por lo que exijan las regulaciones.
4. Pruebas periódicas de recuperación (DR drills)
Planificación de simulacros: Definir un calendario semestral de pruebas de recuperación, donde se restaure un subconjunto representativo de PDFs críticos desde backup on-premise y desde nube, validando integridad y tiempos de recuperación (RTO).
Checklist de verificación: Para cada DR drill, asegurar que se comprueben:
Integridad de archivos (hash coincidencia).
Metadatos completos (todas las etiquetas presentes).
Compatibilidad de versiones y permisos (propietarios, ACLs).
Capacidad de firma digital (certificados cargados y válidos).
Documentación y mejora continua: Tras cada simulacro, recopilar lecciones aprendidas, ajustar políticas de retención y actualizar manuales de recuperación.
5. Backup incremental y deduplicación de datos
Incrementales basados en cambio de bloque: Herramientas que sólo respalden los bloques de archivo modificados en el PDF, minimizando ventana de backup y espacio en disco.
Deduplicación global: En el appliance on-premise y en la capa de nube, activar deduplicación de contenido para no almacenar múltiples copias de un mismo PDF o versiones muy similares.
Compresión eficiente: Comprimir datos de backup (por ejemplo, con LZ4 o zstd) para optimizar coste de almacenamiento y ancho de banda en replicación.
6. Aseguramiento de la integridad y encriptación de backups
Checksums y hash: Almacenar hashes de cada backup completo y de cada versión incremental, verificando automáticamente la integridad antes de cada DR drill.
Encriptación de backups: Tanto on-premise como en la nube deben cifrarse con AES-256, utilizando llaves gestionadas por un KMS corporativo, evitando que un backup robado sea recuperable sin autorización.
Política de rotación de llaves: Renovar llaves de cifrado de backup cada 12 meses y revocar versiones antiguas tras migración de datos.
7. Automatización y orquestación de backup/recovery
Frameworks de automatización: Emplear herramientas como Ansible, Terraform y API de proveedores para configurar, ejecutar y monitorizar jobs de backup y restore de forma programática.
Alertas y reportes: Integrar con el sistema de monitoreo (Nagios, Grafana, Azure Monitor) para recibir alertas tempranas de fallos en backup, descensos de rendimiento y latencias en replicación.
Self-service recovery: Portales internos que permitan a los custodios solicitar restauraciones de PDFs individuales o carpetas completas, con aprobación automática basada en políticas de seguridad.
8. Gobernanza y cumplimiento normativo
Políticas de retención alineadas: Garantizar que los plazos definidos en el ciclo de vida de backup cumplan con normativas como Sarbanes-Oxley, GDPR, FDA 21 CFR y otras aplicables según industria.
Auditoría de backups: Mantener logs WORM de todas las operaciones de backup y restore, accesibles para auditorías externas e internas.
Certificación de proveedores: Verificar que los servicios de nube para backup cuentan con certificaciones ISO 27001, SOC 2 Type II y otras relevantes.
9. Plan de comunicación y formación
Roles y responsabilidades claras: Documentar quién en TI, Compliance y cada área de negocio es responsable de validar restauraciones y mantener el catálogo de documentos críticos.
Entrenamiento a custodios: Talleres prácticos para enseñar cómo usar portales de self-service, interpretar reportes de integridad y coordinar DR drills.
Simulacros de mesa redonda: Reuniones trimestrales donde se discuten escenarios hipotéticos de desastre y se revisan planes de contingencia, involucrando a gerentes de todas las áreas.
10. Evolución y mejora continua
Integración de IA para predicción de fallos: Modelos que analicen métricas de hardware y éxito de backups anteriores para predecir posibles errores y sugerir optimizaciones de ventana o configuración.
Backup en contenedores y microservicios: Adaptar estrategias a arquitecturas modernas, asegurando que los PDFs generados por aplicaciones serverless o contenedorizadas también se incluyan en el plan.
Roadmap tecnológico: Evaluar nuevas opciones, como almacenamientos inmortales (WORM en nube), respaldo en redes distribuidas (IPFS) y orquestadores de DR basados en blockchain para mayor transparencia.
Conclusión persuasiva
Diseñar estrategias de backup y recuperación específicas para PDFs críticos es esencial para garantizar la continuidad operativa, la integridad de la información y el cumplimiento regulatorio. Combinando clasificación rigurosa, arquitecturas híbridas georreplicadas, versionado inteligente, automatización, pruebas periódicas y un enfoque de mejora continua, las organizaciones logran tiempos de recuperación mínimos (RTO), reducir pérdidas de datos (RPO) y demostrar al Comité Ejecutivo un control total sobre los documentos más valiosos. Esta robustez operacional no solo mitiga riesgos, sino que fortalece la confianza de clientes, reguladores y socios en la capacidad de la empresa para superar cualquier adversidad sin perder información estratégica.
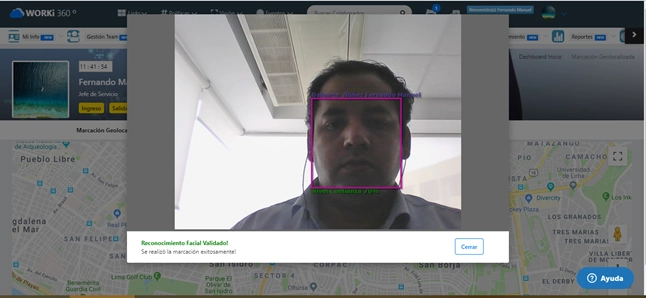
¿Cómo reducir el tiempo de procesamiento de facturas en PDF mediante RPA?
Contexto y storytelling gerencial
En 2023, la empresa global de distribución FastLogistics revisó sus indicadores de cuentas por pagar y detectó que, en promedio, cada factura en PDF tardaba entre 3 y 5 días hábiles en ser procesada desde su recepción hasta su validación y pago. Esto generaba cuellos de botella en tesorería, penalizaciones por pagos tardíos y dificultades para proyectar flujos de caja. El CFO, cansado de retrasos y altos costes operativos, aprobó un proyecto piloto de automatización con RPA (Robotic Process Automation) para facturas en PDF. En solo dos meses, lograron reducir el ciclo a menos de 24 horas y liberar al equipo de tareas repetitivas, redirigiendo su tiempo hacia análisis financiero estratégico.
1. Mapeo y estandarización del proceso actual
Documentar el flujo manual: identificar cada paso—recepción (correo, portal proveedor), descarga del PDF, extracción de datos (número, fecha, importe, proveedor), validación interna, aprobación y registro en ERP.
Identificar excepciones y variaciones: facturas con diseños distintos, firmas digitales, múltiples idiomas o monedas, líneas de descuento o impuestos especiales.
Estandarizar formatos: acordar con proveedores un template mínimo compatible (por ejemplo, campos ubicados siempre en posiciones similares) para facilitar la extracción automatizada.
2. Selección de la herramienta RPA adecuada
Capacidades de OCR y Computer Vision: elegir plataformas como UiPath, Automation Anywhere o Blue Prism que integren motores de OCR avanzado (ABBYY, Google Vision) y habilidades para reconocer zonas de interés en el PDF.
Integración con sistemas empresariales: la solución debe conectarse vía API o web services al ERP (SAP, Oracle, Microsoft Dynamics) y al sistema de correo/intranet donde llegan las facturas.
Orquestación y escalabilidad: gestionar colas de trabajo, balanceo de bots y monitorización centralizada desde un Control Room.
3. Pipeline de automatización de facturas
a. Ingestión y clasificación de PDFs
Recolectar facturas: el bot monitoriza bandejas de correo y carpetas compartidas, descarga nuevos PDFs y los nombra según convenciones (Proveedor_Fecha_NºFactura).
Clasificar Diseño: mediante aprendizaje automático, el bot determina el “layout” de cada factura para aplicar el template de extracción correcto.
b. Extracción de datos con OCR y reglas de negocio
OCR preprocesamiento: mejora de contraste, eliminación de marcas de agua y rotación automática para garantizar alta tasa de reconocimiento.
Zonal OCR: extracción de campos específicos (RFC/CIF, fechas, importes, conceptos) basándose en coordenadas o anclas de texto.
Validaciones automáticas: chequeo de formatos (fecha válida, importe numérico, coincidencia de CIF con base de proveedores).
c. Validación y enriquecimiento
Comparativa con PO: el bot consulta pedidos de compra abiertos en el ERP y valida que los importes y conceptos coincidan con el PO correspondiente.
Gestión de excepciones: si hay discrepancias, el bot genera un caso en la herramienta de workflow (ServiceNow, Jira) asignado al responsable de compra o finanzas.
d. Aprobación y registro
Envío para firma electrónica: si la política lo exige, el bot envía la factura al sistema de firma digital, espera el sellado y confirma el proceso.
Creación de asiento en el ERP: a través de API o interacción con la interfaz, el bot introduce los datos validados, asocia centros de costo y proyectos, y registra la factura para pago.
e. Notificación y archivado
Notificación a stakeholders: el bot envía un correo o alerta en Teams a tesorería indicando que la factura está lista para pago.
Archivado en DMS: el PDF original y la factura digitalizada se almacenan en el gestor documental con metadatos enriquecidos (fecha de registro, usuario bot, número de asiento contable).
4. Ahorro de tiempo y reducción de errores
Rendimiento de bots: una máquina virtual con 4 bots trabajando en paralelo puede procesar cientos de facturas diarias frente a las 20–30 que gestiona un empleado manualmente.
Tasa de éxito OCR: con preprocesamiento y entrenamiento continuo, se puede alcanzar un 95–98 % de precisión en extracción, minimizando revisiones humanas.
Ciclo end-to-end: pasar de un promedio de 72 horas a menos de 24 horas por factura (objetivo < 8 horas en visión 6 meses).
5. Gestión de excepciones y aprendizaje continuo
Dashboards de excepciones: visualizar tipos y causas de errores (facturas no reconocidas, PO no encontrado, discrepancias de importe) para tomar acciones correctivas con proveedores.
Feedback loop: cada vez que un operador corrige un dato extraído, el sistema alimenta un modelo de ML que mejora la clasificación de layouts y el zonal OCR.
Capacitación a proveedores: compartir indicadores de error para que los emisores (proveedores) adapten sus formatos y reduzan excepciones.
6. Seguridad, compliance y auditoría
Logs detallados: cada acción del bot (descarga, extracción, validación, registro) se guarda con timestamp, ID de bot y hash del PDF original.
Segregación de funciones: el bot no autoriza pagos; solo deja la factura en estado “aprobada para pago”, asegurando que un controlador humano finalice la transferencia.
Firma digital y sellado: el registro en el ERP y el PDF final llevan la firma digital del responsable financiero con sello de tiempo para auditorías futuras.
7. Gobernanza y rol del equipo RPA
Centro de Excelencia RPA: define estándares de desarrollo, pruebas y despliegue de bots, así como métricas de calidad (MTTR, tasa de fallos, volumen procesado).
Colaboración cross-funcional: finanzas, compras, TI y compliance trabajan juntos en definir excepciones, reglas de negocio y SLAs de procesamiento.
Roadmap de mejoras: incorporación de tecnologías emergentes como RPA+AI (Inteligencia de Procesos) para detectar facturas fraudulentas y aplicar aprendizajes automáticos.
8. Métricas clave y ROI
Tiempo medio de proceso: métrica central que debe reducirse en un 70–80 % tras la implementación completa.
Coste por factura: calcular el costo operativo manual vs. automático (costo hora bot + infra) y proyectar ahorro anual.
SLA de excepciones: porcentaje de facturas que requieren intervención humana y tiempo medio de resolución, idealmente < 5 % y < 4 horas respectivamente.
9. Casos de éxito y benchmarking
FastLogistics: implementó RPA y recortó 4 días de ciclo de facturas, ahorrando 200.000 € anuales en costes de demora.
GlobalRetail: alcanzó un 98 % de precisión OCR y redujo disputas con proveedores en un 60 %, gracias a validación automática de PO.
EnergyCorp: integró RPA con blockchain ligero para sellado de facturas y garantizó inmutabilidad ante auditorías de la CNMV.
10. Mejora continua y escalabilidad
Expansión a otros procesos: aplicar el mismo framework de RPA a órdenes de compra, gestión de contratos y reportes de gastos.
Automatización cognitiva: avanzar hacia RPA asistido por AI que interprete condiciones de pago complejas y detecte posibles fraudes.
Orquestación centralizada: integrar RPA con iPaaS y plataformas de integración (MuleSoft, Dell Boomi) para coordinar procesos end-to-end sin silos operativos.
Conclusión persuasiva
La automatización del procesamiento de facturas en PDF mediante RPA no solo acelera drásticamente el ciclo de cuentas por pagar, sino que reduce errores, mejora la relación con proveedores y libera al equipo financiero para tareas estratégicas. Con una arquitectura robusta de ingestión, OCR, validación de negocio, control de excepciones y gobernanza clara, las organizaciones logran un proceso confiable, auditable y escalable. Este enfoque transforma un cuello de botella operativo en una ventaja competitiva, optimizando el flujo de caja y demostrando un ROI significativo que justifica la adopción masiva de RPA en finanzas.

¿Qué aprendizajes aporta el Big Data aplicado al análisis de PDFs empresariales?
Contexto y storytelling gerencial En DigitalHealth Inc., una empresa global dedicada a servicios sanitarios digitales, el equipo de Innovación Tecnológica reunió un archivo histórico de más de 5 millones de PDFs: informes clínicos, consentimientos informados, registros de auditorías y documentación regulatoria. Hasta entonces, esos documentos dormían en repositorios sin aprovechar su riqueza de datos. Con la iniciativa “Proyecto Claridad”, implantaron una plataforma de Big Data capaz de ingerir, procesar y analizar ese océano de información. En pocos meses, hallaron patrones antes invisibles: hospitales con mayores tiempos de espera, términos frecuentes en reclamaciones legales y oportunidades para estandarizar protocolos. Estos aprendizajes no solo mejoraron la atención al paciente, sino que optimizaron recursos, redujeron costes y fortalecieron la posición de la empresa ante entes reguladores. 1. Identificación de patrones de uso y comportamiento Clusterización de documentos: mediante algoritmos de clustering (K-means, DBSCAN), la plataforma agrupa PDFs por similitud de contenido (diagnósticos, tipos de contrato, manuales de equipo). Esto revela áreas de conocimiento redundantes o desactualizadas. Análisis de frecuencia de términos: calcular TF-IDF para detectar conceptos recurrentes en diferentes divisiones, lo que ayuda a estandarizar el lenguaje corporativo y mejorar la claridad de comunicaciones. Tiempos de acceso: correlacionar la hora, día de la semana y región en que los empleados o clientes acceden a ciertos documentos, optimizando la disponibilidad y plan de capacitación según demanda real. 2. Detección de riesgos y anomalías Modelos de outlier detection: herramientas de Big Data como Apache Spark MLlib o Amazon Athena detectan documentos con estructuras inusuales (contratos con cláusulas fuera de estándar) que pueden esconder riesgos legales o de cumplimiento. Análisis de fraude: cruzar datos extraídos de facturas en PDF con registros internos de pagos y proveedores para identificar facturas duplicadas o inconsistentes, disminuyendo fraudes en cuentas por pagar. Alertas predictivas: generadas por sistemas de streaming (Kafka, Kinesis), que advierten cuando la frecuencia de accesos o modificaciones a ciertos PDFs críticos excede umbrales, indicando posibles filtraciones o sabotajes internos. 3. Mejora de la eficiencia operativa Optimizaciones de flujos de trabajo: al analizar métricas de procesado de PDF (tiempos de OCR, validaciones manuales, reprocesos), el equipo de Operaciones ajusta recursos (bots RPA, nodos de cómputo) donde más se necesitan, minimizando cuellos de botella. Balanceo de carga: los reportes de Big Data indican qué repositorios regionales reciben mayor carga de descargas, permitiendo reequilibrar réplicas en el CDN para reducir costes de transferencia y mejorar tiempos de respuesta. Planificación de capacidad: se proyecta el crecimiento del volumen de PDFs y se dimensiona con exactitud la infraestructura de almacenamiento, procesado y backup, evitando sobrecostes e infrautilización. 4. Enriquecimiento de metadatos y taxonomías dinámicas Autoetiquetado mediante AI: modelos de clasificación automática sugieren etiquetas adicionales (temáticas, de riesgo, de cliente), alimentando un catálogo dinámico que evoluciona según nuevos documentos ingresan. Ontologías corporativas: Big Data ayuda a definir y refinar ontologías de negocio basadas en co-ocurrencias de términos, mejorando la búsqueda semántica y la interoperabilidad con otros sistemas de información. Mapeo de relaciones: grafos de conocimiento (Knowledge Graphs) que vinculan entidades extraídas de PDFs—clientes, proyectos, productos—facilitan encontrar conexiones ocultas y oportunidades de cross-sell. 5. Análisis predictivo y prescriptivo Modelos de predicción de demanda: estudiando contratos de servicios en PDF se proyectan renovaciones y nuevos volúmenes de negocio, permitiendo ajustar oferta de personal y recursos técnicos. Prescriptivo para compliance: algoritmos determinan cuándo conviene actualizar o revisar ciertos manuales en PDF antes de inspecciones regulatorias, basados en cambios normativos y patrones de auditoría histórica. Mantenimiento predictivo de plantillas: si detectan que una plantilla de PDF de manual de equipo técnico genera repetidamente errores de OCR, se programa su rediseño antes de que afecte procesos críticos. 6. Integración con BI y visualización avanzada Big Data to BI: mediante ELT (Extract, Load, Transform) se envían los insights generados a plataformas de BI (Power BI, Tableau), donde se construyen dashboards que combinan datos estructurados con KPIs derivados de PDF (porcentaje de documentos obsoletos, tiempo medio de lectura, patrones de anotaciones). Visualización de grafos: herramientas como Neo4j Bloom muestran relaciones complejas entre contratos, clientes y cláusulas, facilitando la detección de dependencias y riesgos concentrados. Narrativas automáticas: motores de NLG (Narrative Science, Arria) generan descripciones en lenguaje natural que resumen hallazgos críticos a partir de los datos de Big Data, sin necesidad de que los gerentes accedan a raw data. 7. Gobernanza de datos y calidad Perfilar calidad de datos: indicadores de completitud, consistencia y precisión de la información extraída de PDFs, que permiten identificar fuentes de error (OCR malo, metadatos faltantes) y orquestar correcciones. Linaje de datos: seguimiento de cada dato extraído desde el PDF original hasta los informes generados, requisito fundamental para auditorías y cumplimiento de normas como GDPR o FDA. Políticas de acceso: control granular de quién puede ver y manipular los insights derivados, alineado con roles y responsabilidades, evitando fugas de información sensible. 8. Casos de uso gerenciales clave Benchmarking interno: comparar rendimiento de diferentes unidades de negocio o regiones en base a indicadores extraídos de manuales de procesos y reportes de mejora continua en PDF. Optimización de riesgos legales: identificar cláusulas problemáticas recurrentes en contratos estandarizados y proponer modificaciones de plantilla que reduzcan la exposición. Mejora en la satisfacción del cliente: analizar patrones de reclamaciones y RDAs (Request for Document Amendments) en PDF para anticipar necesidades de soporte o formación. 9. Transformación cultural y organizacional Data-driven mindset: difundir casos de éxito donde los insights de Big Data sobre PDFs han cambiado decisiones estratégicas, motivando a equipos a colaborar en calidad de datos y etiquetado. Formación en competencias analíticas: talleres para gerentes sobre cómo interpretar dashboards, diseñar hipótesis y validar hallazgos mediante muestras de PDFs originales. Comunidades de práctica: grupos internos que comparten plantillas, ontologías y hallazgos, acelerando la adopción de mejores prácticas en toda la organización. 10. Roadmap de evolución tecnológica Streaming de documentos: pasar de procesamiento batch a ingestión en tiempo real con Kafka Connect y Spark Streaming, de modo que cada PDF nuevo genere insights inmediatos. Integración de LLMs: utilizar grandes modelos de lenguaje para interpretar contexto y generar resúmenes ejecutivos automáticos de cada PDF, enriqueciendo aún más los metadatos. Blockchain para audit trail: explorar redes privadas para sellado de tiempo de los metadatos críticos extraídos, garantizando inmutabilidad y transparencia ante auditores externos. Conclusión persuasiva El Big Data aplicado al análisis de PDFs empresariales convierte información silente en conocimiento accionable. Desde la detección de riesgos ocultos y la mejora de procesos operativos, hasta la creación de ontologías dinámicas y modelos predictivos, estos aprendizajes impulsan la toma de decisiones estratégicas basadas en evidencia. Al integrar esta capacidad con los sistemas de BI, compliance y seguridad, la dirección obtiene visibilidad total, reduce costes, fortalece el cumplimiento y promueve una cultura data-driven. Invertir en esta transformación permite que cada PDF deje de ser un simple archivo para convertirse en un activo de inteligencia corporativa.
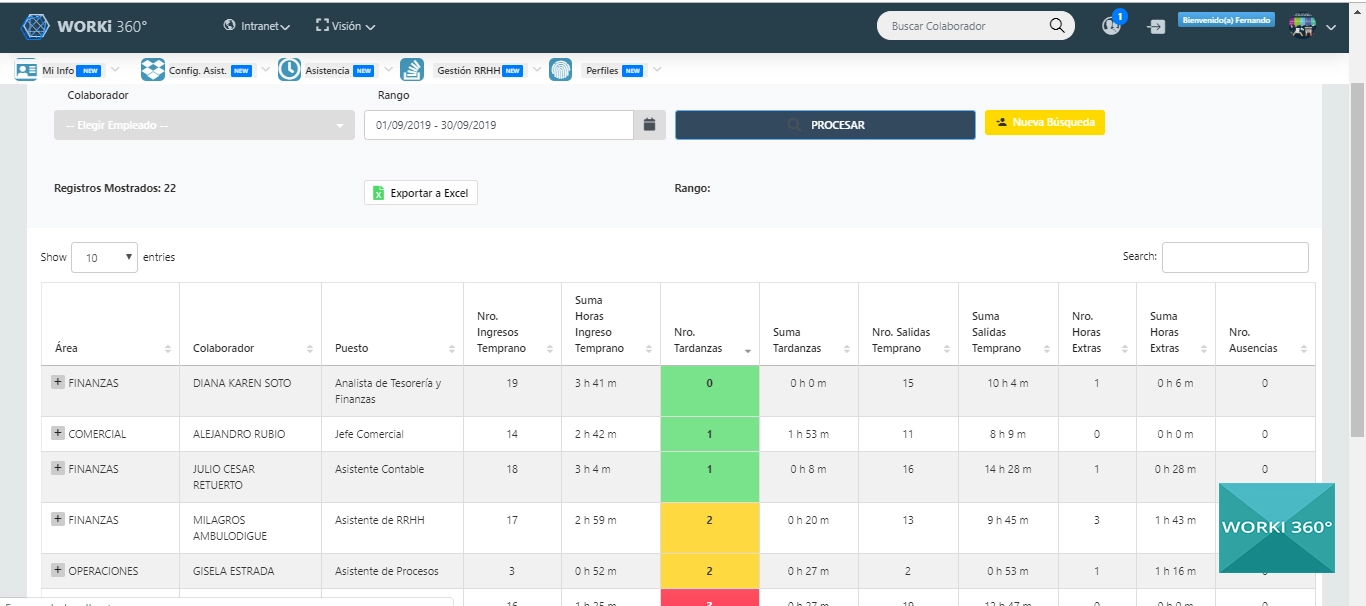
¿Cómo se diseña un dashboard gerencial basado en indicadores extraídos de PDFs?
Contextualización y storytelling gerencial En DataCorp Internacional, la Mesa Directiva estaba abrumada por el volumen de informes en PDF que llegaban cada semana: reportes de ventas, análisis de producto, encuestas de satisfacción y estudios de mercado. Aunque cada documento contenía indicadores valiosos, no existía un punto único de consulta para ver la evolución de esas métricas a lo largo del tiempo o comparar regiones, líneas de negocio y responsables. Para resolverlo, el equipo de Inteligencia de Negocio lideró un proyecto para extraer automáticamente KPIs de esos PDFs y volcarlos en un dashboard gerencial interactivo. En pocas semanas, los directores podían monitorear tendencias, detectar desviaciones y tomar decisiones proactivas, en lugar de reaccionar a informes estáticos y aislados. 1. Definición de objetivos y KPIs clave Alineación estratégica: antes de construir el dashboard, convocar workshops con la alta dirección y áreas clave (Finanzas, Ventas, Operaciones) para identificar qué indicadores de los documentos PDF son prioritarios para la toma de decisiones. Selección de KPIs: por ejemplo, tasa de crecimiento de ingresos, margen por línea de producto, tiempo medio de aprobación de contratos, porcentaje de documentos con firma electrónica dentro del SLA, nivel de cumplimiento regulatorio extraído de auditorías en PDF. Nivel de agregación: decidir si los KPIs se muestran a nivel global, regional o por unidad de negocio, y establecer filtros temporales (día, semana, mes, trimestre, año). 2. Pipeline de extracción y transformación de datos Conectores a repositorios: configurar conexiones automáticas a SharePoint, AWS S3, DMS o carpetas de red donde se alojan los PDFs. OCR y extracción estructurada: utilizar motores de OCR avanzado y extracción zonal o semántica (por ejemplo, con Google Document AI o ABBYY FlexiCapture) para capturar cifras y textos clave (fechas, porcentajes, montos, comentarios de análisis). Normalización y limpieza: estandarizar formatos de fecha, moneda y unidades; eliminar caracteres especiales o marcadores de escaneo; ajustar nombres de indicadores para homogeneizar orígenes diversos. Enriquecimiento de metadatos: asociar cada dato extraído con atributos como “Documento”, “Autor”, “Fecha de Publicación”, “Región” y “Categoría” para facilitar el análisis multidimensional. 3. Modelado de datos y almacén intermedio Diseño de un Data Mart: crear un esquema estrella o copo de nieve en un data warehouse (Snowflake, Redshift, Azure Synapse) donde los hechos contengan los valores numéricos y las dimensiones definan contexto (tiempo, región, unidad de negocio, tipo de documento). Carga incremental y CDC: implementar procesos ETL/ELT con herramientas como Talend, Matillion o Azure Data Factory para actualizar solo los datos nuevos o cambiados, garantizando frescura sin sobrecarga. Control de calidad: validar que los totales extraídos coincidan con los valores reportados originalmente en los PDFs fuente, estableciendo alertas cuando existan desvíos superiores al umbral aceptable (por ejemplo, 0,5 %). 4. Selección de la plataforma de visualización Factores a evaluar: usabilidad, capacidad de integración con el DW, soporte para filtros dinámicos y drill-down, rendimiento en grandes volúmenes de datos, opciones de embebido en intranet o aplicaciones móviles. Opciones comunes: Power BI, Tableau, Qlik Sense o herramientas nativas de la nube (Amazon QuickSight, Looker). Seguridad y gobernanza: asegurar SSO y control de acceso por rol, definiendo quién puede ver cada hoja, quién puede crear nuevas vistas y cómo se gestionan las versiones del dashboard. 5. Diseño del dashboard: principios UX/UI para directivos Simplicidad y enfoque: mostrar solo los indicadores críticos en la vista principal, con alertas de semáforo o heatmaps que destaquen desviaciones. Estructura jerárquica: Resumen ejecutivo con métricas top-line (ingresos totales, margen global). Sección analítica con gráficos de tendencia, comparaciones regionales y drill-down por unidad. Detalle de documentos que permita ver la fuente PDF original o extractos, con enlaces directos para validación. Elementos visuales: líneas de tiempo, barras comparativas, gauges para objetivos, matrices de calor, mapas geográficos y tablas con sparklines. Interactividad: filtros por periodo, región, tipo de documento y responsable; habilitar “what-if” o escenarios hipotéticos para valorar el impacto de cambios en los indicadores. 6. Integración de alertas y notificaciones Reglas de alerta: configurar condiciones (por ejemplo, caída del 10 % en ventas mensuales) que disparen correos automáticos o mensajes en Teams/Slack a los gerentes responsables. Subscripciones personalizadas: permitir que cada usuario se suscriba a reportes periódicos (semanales, mensuales) con un PDF generado del dashboard, firmado digitalmente y archivado en el sistema. Módulo de comentarios: habilitar anotaciones colaborativas para que los directores dejen observaciones junto a cada gráfico, quedando documentada la discusión en la propia plataforma. 7. Trazabilidad y drill-through al documento fuente Vinculación directa al PDF: cada métrica incorpora un hipervínculo o pop-up que muestra el extracto del PDF fuente (página y párrafo) de donde se extrajo el dato, garantizando transparencia y auditoría. Historial de cambios: versionado del dashboard con registro de fechas, autores de cambios y comentarios, de forma similar al control de versiones de un DMS. Registro de accesos: logging de quién consulta qué indicador, desde qué ubicación y en qué momento, integrándose con el SIEM corporativo en caso de información sensible. 8. Pruebas piloto y feedback iterativo Grupo reducido de usuarios: iniciar con el Comité de Dirección y un pequeño grupo de gerentes para validar usabilidad, relevancia de KPIs y claridad de visualizaciones. Sesiones de feedback: workshops quincenales donde se recogen sugerencias de mejoras (nuevos filtros, cambio de gráficos, inclusión de KPIs adicionales). Iteraciones ágiles: aplicar cambios en sprints de 1–2 semanas, comunicando versiones y novedades a usuarios para fomentar la adopción continua. 9. Gobernanza y mantenimiento continuo Equipo de BI dedicado: definir un “centro de excelencia” que gestione el data mart, las conexiones, los modelos y los dashboards, con SLAs de actualización y resolución de incidencias. Documentación viva: manual de uso, glosario de KPIs, mapeo de campos de PDFs a métricas y diagramas de flujo de datos, accesibles en línea y actualizados con cada cambio. Auditorías periódicas: revisar trimestralmente la calidad de los datos extraídos, la relevancia de los indicadores y el rendimiento del dashboard, ajustando el roadmap de mejoras. 10. Impacto y beneficios estratégicos Visibilidad en tiempo real: los directores dejan de depender de informes estáticos y tardíos; tienen datos actualizados al minuto para reaccionar ante cambios de mercado. Reducción de ciclos de decisión: se acortan los comités de revisión de 2 semanas a 2 días, gracias a la facilidad para comparar escenarios y profundizar en las causas raíz. Alineación transversal: todos los mandos intermedios trabajan con un mismo origen de datos, evitando discrepancias y alineando métricas con los objetivos corporativos. 🧾 Resumen Ejecutivo WORKI 360 potencia la inteligencia gerencial al convertir documentos PDF dispersos en un único centro de mando estratégico. Gracias a su capacidad para extraer, normalizar y visualizar KPIs desde cualquier PDF—ya sean reportes financieros, contratos o manuales—la plataforma ofrece un dashboard interactivo, seguro y auditado que: Unifica la visión de indicadores clave en tiempo real, eliminando silos de información y acelerando la toma de decisiones. Garantiza trazabilidad total: cada métrica enlaza al fragmento exacto del PDF origen, con historial y control de versiones, reforzando compliance y transparencia. Automatiza alertas y suscripciones personalizadas, manteniendo a los responsables informados 24/7 y reduciendo ciclos de revisión de semanas a días. Escala de forma ágil gracias a pipelines de extracción, data marts y plataformas BI integradas, alineándose con el crecimiento global de la organización. Con WORKI 360, los gerentes disponen de un tablero de control corporativo basado en datos reales extraídos de sus PDFs, lo que se traduce en mayor eficiencia, mejor gobernanza documental y un ROI tangible en productividad y compliance.