
Índice del contenido
¿Cómo asegurar la integridad y trazabilidad de cada boleta generada o emitida?
Para un director gerencial, garantizar que cada boleta emitida —sea de venta, votación o notificación— mantenga su integridad (no alteración de datos) y trazabilidad (registro completo de su ciclo de vida) es un requisito de cumplimiento, confianza y control de riesgos. A continuación, se describe un marco robusto, basado en tecnología, procesos y gobernanza, dividido en diez componentes esenciales.
1. Diseño de una arquitectura WORM para almacenamiento de boletas
Write Once Read Many (WORM): Use medios o servicios (p. ej., AWS S3 Object Lock, Azure Immutable Storage) que permitan escribir la boleta una sola vez y luego solo lectura, impidiendo modificaciones o eliminaciones.
Replicación geográfica inmutable: Asegure que cada registro WORM se replique en dos o más regiones, protegiendo contra desastres y ataques locales.
Criptografía de nivel de objeto: Cada archivo de boleta se cifra en reposo (AES-256) y su clave se gestiona en un KMS corporativo, garantizando que solo servicios autorizados puedan leerlo.
2. Firma electrónica y sellado de tiempo de cada boleta
Certificados digitales PKI (PAdES): Al generar la boleta en PDF o XML, se firma digitalmente con un certificado de “emisión” emitido por la Autoridad de Certificación interna o un TSP cualificado; esto atestigua la autoría y la integridad del contenido.
Timestamping confiable (TSA): Junto con la firma, se incorpora un sello de tiempo emitido por un Proveedor de Sellado de Tiempo (TSA), creando una marca irrefutable de cuándo se emitió la boleta.
Almacenamiento de evidencias: Se guarda copia de la boleta firmada y del token de sellado en un repositorio forense (logs WORM) para auditorías futuras.
3. Registro de eventos y metadatos en blockchain privado
Cadena de bloques corporativa: Cada vez que se emite o modifica (por ejemplo, reemite o cancela una boleta), se almacena en un nodo blockchain el hash criptográfico del archivo y su metadato esencial (ID de boleta, timestamp, operación).
Inmutabilidad distribuida: La replicación en múltiples nodos impide alteraciones sin consenso; cualquier discrepancia alerta al equipo de seguridad.
Consulta liviana: Mediante APIs, los dashboards gerenciales pueden validar rápidamente que un hash coincide con el que figura en la cadena, asegurando autenticidad.
4. Trazabilidad de ciclo de vida en un sistema de logging WORM y SIEM
Eventos clave a loguear: generación, firma, envío, descarga, impresión, anulación. Cada evento incluye usuario o sistema, IP, User-Agent, geolocalización aproximada y timestamp de alta precisión.
Repositorio WORM de logs: Los logs se almacenan en un servicio inmutable (p. ej., Splunk Immutable Logs, AWS CloudWatch Logs con retención inmutable), garantizando que no puedan borrarse o manipularse.
Correlación en SIEM: Con Splunk, QRadar o Elastic SIEM, se analizan patrones inusuales (picos de reemisión, descargas masivas) y se disparan alertas automáticas.
5. Arquitectura de microservicios con trazabilidad integrada
Microservicio de emisión: Servicio dedicado a crear la boleta, encapsularla en PDF/XML, firmarla y almacenar hash + metadatos en blockchain.
Microservicio de consulta: Cada solicitud de visualización o descarga pasa por un API Gateway que valida token JWT y registra el acceso con datos del solicitante.
Microservicio de auditoría: Expone endpoints internos para extraer reportes de trazabilidad, conectándose tanto al repositorio WORM de boletas como al de logs.
6. Control de acceso basado en roles y políticas de cero confianza
RBAC y ABAC: Definir roles (emisor, auditor, receptor) y atributos (departamento, región, nivel de confidencialidad) que determinan permisos granulares: emisión, consulta, revocación.
Política de acceso mínimo: Cada usuario o sistema accede solo a las boletas pertinentes a su ámbito de trabajo, mitigando la exposición de datos sensibles.
Reautenticación MFA: Para acciones críticas (anulación o reemisión), exigir doble factor (OTP, certificado digital) antes de procesar la solicitud.
7. Dashboards gerenciales con indicadores de integridad y trazabilidad
KPIs a mostrar: número de boletas emitidas, descargadas, canceladas; tiempo medio de emisión; alertas activas de integridad (hash mismatches), infracciones de acceso.
Visualizaciones: líneas de tiempo de eventos, mapas de calor de accesos por región, tablas de boletas con estado de firma y sellado.
Drill-down: posibilitar ir de un KPI agregado a la lista de eventos detallados de una boleta específica, con hipervínculos directos a logs y documentos.
8. Políticas de retención y archivado conforme a normativas
Retención diferenciada: Clasificar boletas por tipo —por ejemplo, fiscales, de votación, de servicio— y asignar plazos de retención obligatorios (6 años, 10 años, indefinido).
Archivado en PDF/A-2: Para boletas que requieren conservación legal, generar automáticamente una versión PDF/A-2 con metadatos XMP incluidos.
Purgado con certificación: Al cumplir plazo de retención, ejecutar proceso automatizado que marca boleta como “caducada” y borra objeto WORM tras registro en blockchain de su destrucción.
9. Pruebas de integridad y simulacros de auditoría
Validación periódica de hashes: Un job automatizado recalcula el hash de cada boleta almacenada y lo compara con el registro en blockchain para detectar corrupciones inadvertidas.
Simulacros de auditoría interna: Cada trimestre, el equipo de Compliance selecciona aleatoriamente boletas y retraza todo el flujo —desde emisión hasta archivo—, documentando hallazgos y mejoras.
Informes de cumplimiento: Generar reportes ejecutivos y entregarlos al Comité de Riesgos, destacando métricas de integridad (0 discrepancias esperadas) y trazabilidad (100 % de eventos registrados).
10. Cultura organizacional y formación continua
Manual de buenas prácticas: Documento formativo en PDF interactivo que describa paso a paso la generación, firma y consulta de boletas, con ejemplos y FAQs.
Workshops y “champions” de integridad: Nombrar embajadores en cada área para monitorizar el cumplimiento de procesos y servir de primer nivel de soporte.
KPIs de adopción: Incluir en las evaluaciones de desempeño métricas de uso correcto de la plataforma (porcentaje de boletas emitidas sin errores, número de alertas justificadas), reforzando la responsabilidad individual.
Conclusión persuasiva
Al combinar tecnologías WORM y blockchain, firma electrónica y sellado de tiempo, logging inmutable en SIEM, microservicios trazables y políticas de acceso cero confianza, se construye un ecosistema donde cada boleta es un activo confiable, cada paso queda registrado y todo cambio queda documentado. Esta robustez no solo mitiga riesgos legales y de fraude, sino que refuerza la confianza de clientes, auditores y reguladores. Para un director gerencial, esta estrategia integral supone una palanca de diferenciación competitiva: garantiza la integridad de sus operaciones, facilita auditorías y posiciona a la organización como referente en gobernanza digital de boletas.
¿Qué mecanismos de autenticación (SSO, OAuth, identidad digital) son adecuados para validar usuarios?
Contextualización y storytelling gerencial En la empresa ElectroMarket, durante el lanzamiento de su nueva plataforma de emisión de boletas electrónicas para ventas minoristas, detectaron intentos de acceso no autorizados por parte de cuentas duplicadas y contraseñas débiles. El director de TI, Joel Ramírez, se enfrentó al desafío de reforzar la validación de usuarios sin complicar la experiencia de compra. Tras evaluar múltiples opciones, diseñó un esquema de autenticación híbrido que combina Single Sign-On (SSO), flujos OAuth 2.0 y elementos de identidad digital nacional, logrando equilibrar seguridad, usabilidad y cumplimiento regulatorio. A continuación, los componentes clave de esa arquitectura de autenticación moderna. 1. Single Sign-On corporativo (SSO) como base unificadora Ventaja gerencial: centraliza la gestión de identidades, reduce el número de credenciales que el usuario debe recordar y simplifica la administración de accesos. Protocolos comunes: SAML 2.0 (Security Assertion Markup Language): ideal para entornos B2B o B2E, donde un proveedor de identidad (IdP) emite aserciones que el servicio de boletas (SP) consume para otorgar acceso. OpenID Connect (OIDC): capa de identidad sobre OAuth 2.0, optimizada para aplicaciones web y móviles, que emite tokens JWT con claims (atributos) del usuario. Integración: Conectar la plataforma de boletas al IdP corporativo (Azure AD, Okta, OneLogin), aprovechando metadatos SAML/OIDC. Configurar políticas de sesión, caducidad y renovación automática, garantizando accesos largos en entornos de confianza y caducidades cortas en zonas no confiables. 2. OAuth 2.0 para concesión de permisos de terceros Uso típico: en casos donde la plataforma de boletas necesite interactuar con servicios externos (por ejemplo, pago online, sistemas de facturación o notificaciones SMS) actuando en nombre del usuario. Flujos recomendados: Authorization Code Grant: flujo seguro para aplicaciones backend que garantiza que el token de acceso nunca se filtre al navegador. Client Credentials Grant: adecuado para microservicios internos que hacen llamadas entre sí sin intervención de usuario. Gestión de scopes y consentimientos: Definir scopes (alcances) finos: boletas.emitir, boletas.consultar, pagos.iniciar. Así, al autorizar, el usuario o sistema sabe exactamente qué permisos concede. Implementar pantalla de consentimiento clara, orientada al cliente final, resaltando sólo los scopes necesarios para su flujo de emisión de boletas. 3. Identidad digital y eID/Su‐SIS (según jurisdicción) Contexto regulatorio: muchos gobiernos ofrecen infraestructuras de identidad digital basadas en certificados electrónicos cualificados (p. ej., eIDAS en Europa, Cl@ve PIN en España, DNIe en Argentina). Beneficios: Alta garantía: la identidad está validada por una autoridad certificadora oficial, reduciendo riesgos de suplantación. Valor legal: las boletas firmadas o emitidas bajo identidad digital cualificada poseen plena validez jurídica frente a auditorías y entes regulatorios. Integración práctica: Adoptar un eID Adapter o gateway especializado que traduzca el flujo de autenticación del gobierno (PKI, OTP móvil) a un token compatible con SAML/OIDC de la plataforma. Ofrecer al usuario final opciones: iniciar sesión con cuenta local, SSO corporativo o identidad digital nacional, mostrando la equivalencia y niveles de seguridad. 4. Autenticación multifactor (MFA) para refuerzo de seguridad ¿Por qué MFA? Mitiga ataques de phishing y credenciales comprometidas al requerir un segundo factor. Tipos de factores: Algo que sabes: contraseña, PIN. Algo que tienes: token de hardware (YubiKey), app TOTP (Google Authenticator), SMS OTP (aunque con menor nivel de seguridad). Algo que eres: biometría (huella, reconocimiento facial) ofrecida por plataformas móviles o Windows Hello. Implementación escalonada: Requerir MFA para usuarios con rol de emisión masiva o acceso a datos sensibles. Ofrecer “recordarme en este dispositivo” con caducidad programada para equilibrar usabilidad. 5. Gestión de identidad y ciclo de vida (IAM) Automatización de onboarding/offboarding: Integrar la plataforma con el IAM corporativo para crear, actualizar y revocar cuentas automáticamente al cambiar el estado laboral o contractual. Evitar cuentas huérfanas, garantizando que un ex‐empleado no pueda emitir ni consultar boletas. Certificados y rotación de secretos: Aplicar políticas de rotación de claves y certificados de acceso (cada 90 días), apoyándose en herramientas como HashiCorp Vault o Azure Key Vault. Registro de auditoría: Cada alta, cambio de rol o revocación se registra con metadato de autor, timestamp y motivo, enlazado a la trazabilidad de boletas. 6. Patrón Zero Trust y autenticación continua Principio “never trust, always verify”: no confiar implícitamente en ninguna solicitud, incluso si proviene de una red interna. Mecanismos de autenticación continua: Token introspection: validar periódicamente el token de acceso contra el servidor de autorización para detectar revocaciones. Behavioral analytics: monitorizar actividades del usuario (patrón de IP, horario) y requerir reautenticación si detecta anomalías. Beneficio gerencial: reduce superficie de ataque y previene accesos no autorizados tras compromisos de sesión. 7. Single Logout (SLO) y revocación de sesiones SLO en SAML/OIDC: garantizar que, al cerrar la sesión en una aplicación corporativa (por ejemplo, portal de empleados), se invalidan también sesiones abiertas en la plataforma de boletas. Blacklisting de tokens: implementar revocación inmediata de tokens de acceso/refresco mediante un store de tokens revocados consultado en cada petición. Visibilidad gerencial: dashboards que muestren número de sesiones activas, tokens expirados y revocados en tiempo real. 8. Experiencia de usuario y accesibilidad Single Click Login: con SSO y OIDC, el usuario final accede con un clic, evitando flujos de registro duplicados. Diseño responsivo: formularios de inicio de sesión adaptados a dispositivos móviles, con indicaciones claras de los pasos (contraseña → OTP → confirmación). Soporte a estándares de accesibilidad (WCAG): garantizar que los flujos de autenticación sean accesibles para usuarios con discapacidad, mediante etiquetas ARIA, contraste de colores y compatibilidad con lectores de pantalla. 9. Pruebas, monitoreo y mejora continua Pruebas de penetración y escaneo de vulnerabilidades: regular para los endpoints de autenticación y autorización (SSO, OAuth, PKI gateways). Monitoreo de KPI de autenticación: Tasa de éxito/fallo de logins. Tiempos medios de autenticación. Incidentes de cuentas bloqueadas por MFA fallido. Feedback de usuarios: encuestas NPS tras flujo de autenticación para detectar fricciones y mejorar el onboarding. 10. Conclusión persuasiva Implementar un esquema de autenticación que combine SSO, OAuth 2.0, identidad digital y MFA dentro de un marco Zero Trust y con gestión de ciclo de vida IAM robusta, no solo fortalece la seguridad de la plataforma de boletas, sino que optimiza la experiencia de usuario y facilita el cumplimiento normativo. Para un director gerencial, esta arquitectura supone una reducción de riesgos de fraude y suplantación, una mejora en la adopción de la plataforma por parte de usuarios internos y externos, y una base sólida para escalar futuras integraciones (pagos, notificaciones, auditorías). Con estos mecanismos, la validación de cada usuario se convierte en un activo estratégico de la organización.
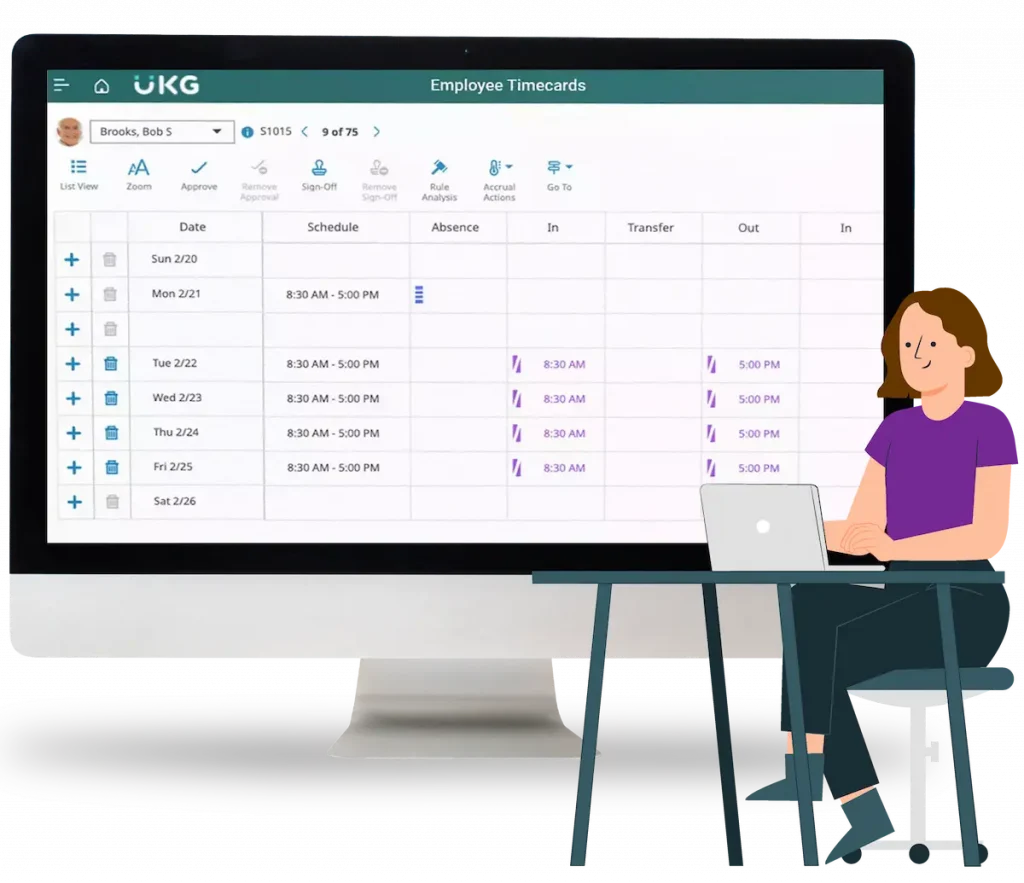
¿Cómo automatizar la generación masiva de boletas en campañas de marketing o elecciones internas?
Contextualización y storytelling gerencial Imagina que la oficina de Marketing de RetailMax prepara su gran promoción anual: quiere enviar 100 000 boletas de descuento personalizadas a sus clientes más fieles, con códigos únicos y fechas de caducidad específicas. Hacerlo manualmente implicaría días de trabajo de validación de datos, generación en Word o Excel, conversión a PDF y envío uno a uno: un cuello de botella y un riesgo de error intolerable. Para resolverlo, el CMO, Laura Pérez, impulsó un proyecto de automatización que redujo esa tarea de una semana a menos de una hora, integrando flujos de datos, plantillas dinámicas y procesos orquestados “sin tocar código” gracias a un diseño de “pipeline” automatizado. A continuación, se describe paso a paso este enfoque, orientado a un público gerencial. 1. Definición de requerimientos y preparación de datos Catálogo de atributos variables: Identificar qué datos diferencian cada boleta: nombre del cliente, segmento, porcentaje de descuento, código alfanumérico, fecha de vencimiento, condiciones especiales. Orígenes de datos unificados: Consolidar en un Data Warehouse o Data Mart la base de clientes objetivo, con vistas filtradas por criterios de campaña (antigüedad, frecuencia de compra, localización). Normalización y limpieza: Aplicar procesos de ETL (Talend, Matillion o AWS Glue) para: Unificar formatos de fecha (YYYY-MM-DD). Validar unicidad de identificadores (email, ID de cliente). Eliminar registros duplicados o incompletos. 2. Diseño de plantillas dinámicas Plantillas parametrizables en HTML/CSS: Crear un documento base en HTML que incluya placeholders (por ejemplo, {{nombre}}, {{codigo_descuento}}, {{vencimiento}}). Estilos corporativos y responsivos: Incluir el logo, paleta de colores y tipografía de la marca, asegurando que la boleta sea legible tanto en pantalla como impresa. Elementos condicionales: Apoyarse en un motor de plantillas (Handlebars, Liquid, Freemarker) para incluir secciones opcionales (por ejemplo, ofertas especiales para VIPs) en función de atributos del cliente. 3. Orquestación del pipeline de generación Servidor de automatización / Orquestador (e.g., Apache Airflow, Azure Data Factory): Tarea de extracción de datos: “Consulta SQL” que extrae el lote de clientes para la campaña. Tarea de transformación: Invoca un script (Python, Node.js) que lee la plantilla HTML y la rellena con valores de cada registro. Tarea de renderizado a PDF: Utiliza librerías como wkhtmltopdf, Puppeteer o PDFKit para convertir cada HTML personalizado en un PDF de alta calidad. Tarea de firma y sellado (opcional): Si se requiere validez legal, envía cada PDF a un microservicio que aplica firma PAdES y TSA. Tarea de almacenamiento: Persiste los PDFs en un bucket (S3, Blob Storage) con nombres estructurados (campañaX_clienteID.pdf) y metadatos de bucket (campaña, fecha_generación). 4. Escalabilidad y paralelismo Trabajo en paralelo: Configurar el orquestador para procesar el lote en chunks (por ejemplo, grupos de 1 000 registros por worker), de modo que múltiples instancias conviertan simultáneamente. Autoscaling de infraestructura: En la nube, aprovechar funciones serverless (AWS Lambda, Azure Functions) o contenedores orquestados en Kubernetes, escalando instancias según la cola de tareas. Monitorización de cola de trabajo: Utilizar métricas de RabbitMQ, AWS SQS o Azure Queue para ver la latencia y el backlog, ajustando el número de workers automáticamente. 5. Integración con sistemas de notificación y entrega Subida de boletas a DMS o plataforma de envío: Una vez generadas, indexar los PDFs en el gestor documental (Box, SharePoint o un DMS propio) para centralizar acceso. Envío masivo de notificaciones: Emails transaccionales: Con SendGrid, SES o Mailchimp Transactional (Mandrill), enviar correos personalizados que incluyan enlaces seguros de descarga (pre-firmados con expiry). SMS/WhatsApp: Para mayor apertura, usar Twilio o MessageBird con mensajes cortos y enlaces a la boleta. Tracking de entregas: Registrar en una base NoSQL (DynamoDB, Cosmos DB) el estado de cada envío (éxito, rebote, clic en enlace) para alimentar dashboards. 6. Dashboard gerencial de control de campaña Principales métricas: Volumen generado: boletas totales vs. objetivo. Tiempo total de generación: desde inicio de pipeline hasta última boleta. Tasa de errores: PDFs fallidos (errores de renderizado, datos faltantes). Entregas y aperturas: porcentaje de emails/sms abiertos y boletas descargadas. Visualizaciones: Gráficos de barras para éxito/error por lote, líneas de tiempo de procesamiento, mapas de calor de aperturas por región. Alertas proactivas: Notificaciones automáticas si la tasa de error supera un umbral (por ejemplo, > 2 %) o si el proceso excede el SLA de campaña. 7. Seguridad y compliance del proceso Cifrado de datos en tránsito y reposo: TLS para APIs y buckets cifrados con AES-256. Acceso restringido: Solo el orquestador y los microservicios de firma pueden leer los datos sensibles de clientes y escribir boletas. Auditoría de eventos: Cada tarea de generación registra evento en SIEM con detalles de inicio/fin y resultados, garantizando trazabilidad. 8. Manejo de excepciones y reintentos Captura de errores específicos: Diferenciar errores de plantilla (falta campo), renderizado (timeout) y firmas (certificado expirado). Política de reintentos: Configurar el orquestador para reintentar automáticamente hasta 3 veces antes de marcar el registro como “pendiente de revisión manual”. Panel de excepciones: Mostrar lista de boletas con fallo, detalle de error y opción de “reprocesar” o “descartar”, con asignación a responsables. 9. Optimización de costos y eficiencia Procesamiento spot/preemptible: En cargas masivas no críticas en tiempo real, usar instancias spot (AWS) o preemptible (GCP) para ahorrar hasta un 70 % en cómputo. Compresión de PDFs: Ajustar parámetros de compresión sin pérdida perceptible, reduciendo espacio de almacenamiento y tiempo de descarga. Archivar resultados de campaña: Tras 3 meses de entrega, mover boletas no descargadas a almacenamiento frío (Glacier, Archive) y conservar solo metadatos en caliente. 10. Mejora continua y análisis post-campaña Lecciones aprendidas: Reunión de post-mortem para analizar métricas de tiempo, errores y entregas, identificando cuellos de botella. Ajuste de plantillas y procesos: Refinar placeholders, mejorar scripts de transformación y optimizar configuración de orquestador. Automatización incremental: Evaluar la incorporación de IA para generación de textos personalizados en boleta (“hola, Juan…”), detección de anomalías previas al envío y recomendaciones de segmento. Conclusión persuasiva Automatizar la generación masiva de boletas en campañas transforma una tarea operativa de alto riesgo y bajo valor en un proceso ágil, seguro y medible. Al integrar orquestadores, plantillas dinámicas, procesamiento paralelo, notificaciones automáticas y dashboards gerenciales, las organizaciones garantizan cumplimiento de plazos, reducción drástica de errores y visibilidad total. Para un director, esta automatización no solo ahorra tiempo y costes, sino que permite escalar campañas de forma repetible y ajustada a objetivos, elevando la capacidad de marketing y la satisfacción de clientes internos y externos.

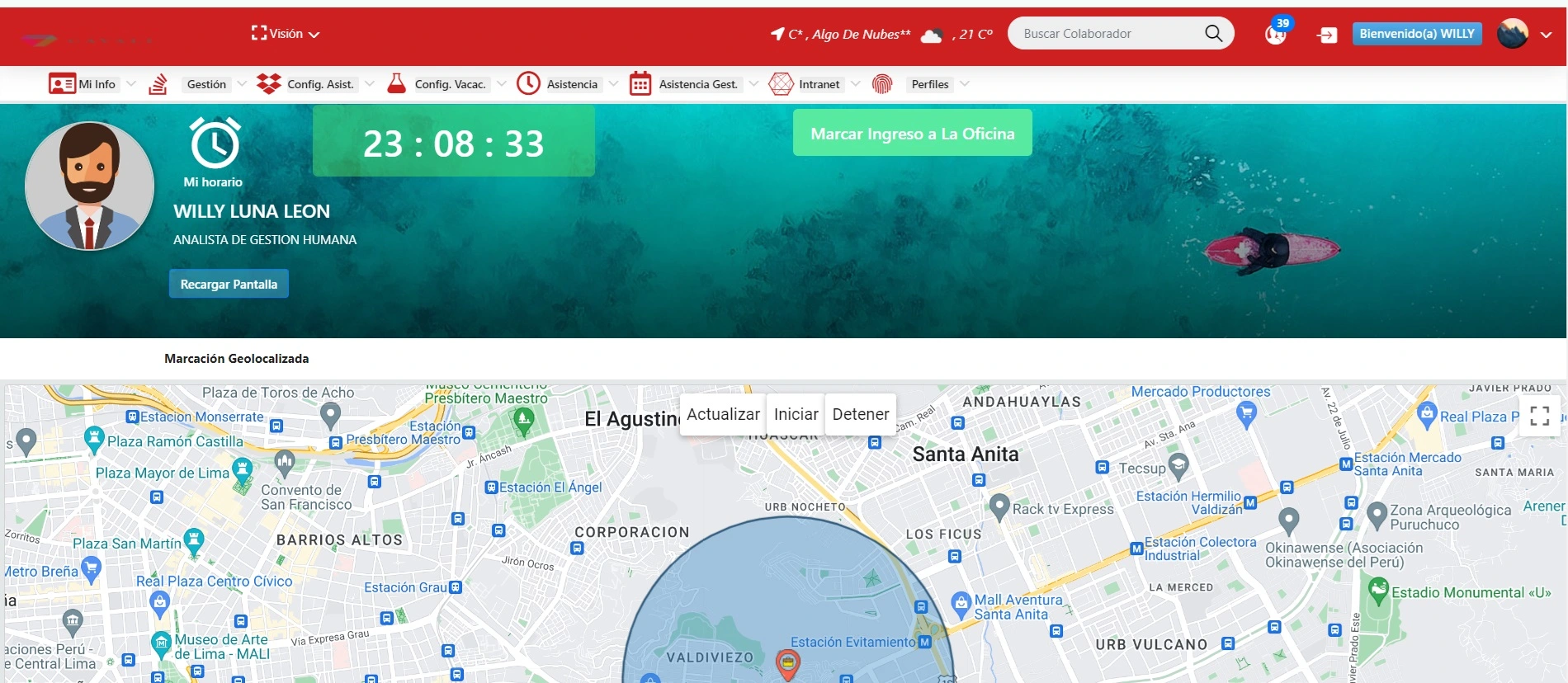
¿Qué soluciones de alta disponibilidad y failover implementar para evitar caídas durante picos de emisión?
Contextualización y storytelling gerencial En la empresa EducaDigital, dedicada a emitir boletas de inscripción y certificaciones académicas en línea, cada inicio de semestre se produce un “tsunami” de solicitudes: decenas de miles de estudiantes acceden al sistema en minutos para descargar sus boletas. Un año, sin una solución de alta disponibilidad (HA), la plataforma colapsó, provocando retrasos de horas y un aluvión de quejas en redes sociales que dañó la reputación institucional. Tras esa experiencia, el CTO, Mariana Ríos, lideró la implementación de un clúster HA con failover automático que permitió atender sin interrupciones picos de hasta 50 000 peticiones por minuto. A continuación, los componentes y prácticas clave para diseñar esta resiliencia. 1. Arquitectura de microservicios redundantes en múltiples zonas de disponibilidad Despliegue multizona: En nubes públicas como AWS, Azure o GCP, aprovecha al menos tres zonas de disponibilidad (AZs). Cada microservicio (emisión, consulta, notificación) se replica en cada AZ, asegurando que la pérdida de una zona no detenga el servicio. Load Balancer global y regional: Global: Un Front Door (Azure) o Global Accelerator (AWS) distribuye tráfico al datacenter más cercano con latencia óptima. Regional: Un Application Load Balancer (ALB) dirige las peticiones entre instancias de microservicio, detectando salud y rotando el tráfico lejos de nodos caídos. Contenedores orquestados: Usar Kubernetes o ECS/Fargate para gestionar réplicas de pods/service tasks con liveness y readiness probes, garantizando que únicamente atiendan tráfico las instancias “sanas”. 2. Bases de datos replicadas y con conmutación por error Primary-Secondary (activo-pasivo): En sistemas SQL como Amazon RDS Multi-AZ o Azure SQL Failover Groups, la base de datos primaria replica cada transacción a una secundaria sincrónica en otra AZ. Ante fallo, la conmutación es automática en < 60 segundos. Primary-Primary (activo-activo): En bases NoSQL (Cassandra, Cosmos DB, DynamoDB global tables), distribuir réplicas de lectura/escritura en varias regiones, con mecanismos de resolución de conflictos y baja latencia. Backups continuos y snapshots: Programar respaldos incrementales frecuentes y snapshots full diarios; almacenarlos en S3/Blob Cold Storage para restauraciones ante pérdida masiva. 3. Caching distribuido con failover Caches en memoria replicadas: Utilizar Redis (ElastiCache Redis Cluster) o Azure Cache for Redis en modo replicado con sharding y failover automático. Esto alivia la carga de lectura en bases de datos durante picos. CDN para contenido estático: Boletas en PDF o imágenes de marca se alojan en un Content Delivery Network (CloudFront, Azure CDN) con control de versiones en la URL para invalidar caches tras actualizaciones. TTL y caché inteligente: Configurar Time-To-Live adecuados (por ejemplo, 5 minutos) y busting programado tras generación de boletas nuevas, evitando servir versiones obsoletas. 4. Orquestación de cola de mensajes y retry policies Mensajería asíncrona: En lugar de procesar boletas sincrónicamente en el request, empujar solicitudes a colas (SQS, Azure Service Bus, Google Pub/Sub). Un pool de workers en cada AZ consume los mensajes a la velocidad que permitan los downstream. Dead Letter Queue (DLQ): Configurar colas de mensajes fallidos tras N reintentos, para su revisión manual sin bloquear el flujo principal. Retry exponencial y backoff jitter: Implementar políticas de reintentos automáticos con delays crecientes y aleatorios, reduciendo ráfagas de retry simultáneas que puedan sobrecargar servicios dependientes. 5. Health checks y failover personalizado Endpoints de salud: Cada microservicio expone /healthz y /readyz con chequeos profundos —comprueba conexión a BD, estado de colas y cache— para que el Load Balancer rote tráfico sólo a instancias totalmente operativas. Circuit Breaker: Middleware (Resilience4j, Polly) que detecta errores recurrentes en un microservicio o dependencia y corta llamadas durante un período para evitar cascadas de fallos. Chaos Engineering: Introducir fallos controlados (chaos monkey) para validar la resiliencia de la arquitectura y ajustar umbrales de auto-scale y probes según resultados. 6. Auto-scaling y gestión de capacidad Horizontal Pod Autoscaler (HPA): En Kubernetes, escalar réplicas de pods según métricas de CPU, memoria o métricas customizadas (longitud de colas, latencia de petición). Cluster Autoscaler: Ajusta el número de nodos en el clúster automáticamente cuando faltan recursos para pods pending, y reduce nodos cuando están infrautilizados. Serverless para picos puntuales: Considerar funciones serverless (Lambda, Azure Functions) para tareas event-driven o generación de boleta en picos muy breves, donde aprovisionar pods sería lento o costoso. 7. Monitoreo proactivo y alertas tempranas Métricas de disponibilidad: Request Success Rate (> 99,9 %). Error Rate por código HTTP (5xx, 4xx). Latency Percentiles (P95, P99). Logs centralizados: Ship logs de aplicaciones y sistema a ELK/EFK o to Splunk, con alertas sobre patrones anómalos (aumento de “connection refused”, “timeout”). Synthetic Transactions: Jobs que simulan la emisión de una boleta cada X minutos, validando todo el flujo y alertando ante fallos antes de que los usuarios reales los detecten. 8. Plan de recuperación ante desastres (DR) Regiones geográficamente distintas: Para objetivos críticos, replicar no sólo en AZs, sino en distintas regiones (p. ej., us-east-1 y us-west-2). Runbooks documentados: Crear procedimientos detallados de failover de región, cambio de DNS en Route 53 / Traffic Manager y validación de servicios tras quórum. Simulacros de DR: Realizar pruebas semestrales de corte de región para medir RTO (Recovery Time Objective) y RPO (Recovery Point Objective), ajustando procesos. 9. Testing y aprobación en entornos staging Entornos idénticos a producción: Duplicar la arquitectura HA en staging para pruebas de carga y simulación de failover sin afectar clientes. Pruebas de carga antes de picos esperados: Ejecutar stress tests (JMeter, k6, Gatling) con cargas similares o superiores a las previstas en campañas o inicios de semestre. Promoción controlada: Canary deployments o blue/green deployments para introducir nuevas versiones del servicio sin sacrificar disponibilidad, rotando tráfico gradualmente. 10. Cultura de resiliencia y responsabilidad compartida Ownership de servicios: Definir equipos responsables (“DevOps” o “SRE”) para cada microservicio, con objetivos SLA/SLO claros y alertas en su radar 24/7. On-call rotativo: Implementar un esquema de turnos de guardia, con playbooks de respuesta rápida ante incidentes. Revisión post-mortem y aprendizaje continuo: Documentar cada incidente mayor, identificar causas raíz y actualizar runbooks y configuraciones (probes, thresholds, autoscale rules) para evitar recurrencias. Conclusión persuasiva La combinación de arquitecturas multizona, balances globales y regionales, bases de datos replicadas, cachés distribuidos, colas asíncronas, health checks inteligentes, auto-scaling dinámico, monitoreo proactivo y un plan de DR bien practicado establece un ecosistema capaz de absorber picos de emisión masiva sin interrupciones. Para un director gerencial, implementar estas soluciones de alta disponibilidad y failover no solo previene pérdidas de ingresos y daño reputacional, sino que posibilita escalar el negocio de boletas con confianza, asegurando una experiencia ininterrumpida para miles o millones de usuarios en los momentos de mayor demanda.

¿Cómo integrar la plataforma con sistemas de pago y pasarelas de cobro?
Contextualización y storytelling gerencial
En TicketExpress, una startup de eventos online, el director financiero detectó que la tasa de abandono durante la compra de boletas era del 25 %. Tras analizar el embudo, concluyó que los usuarios abandonaban al no encontrar su método de pago preferido o al enfrentar errores de cobro. Para resolverlo, diseñó un esquema de integración con múltiples pasarelas y sistemas de pago que redujo el abandono al 5 % y permitió atender mercados internacionales sin incurrir en riesgos legales ni operativos innecesarios. A continuación, los diez componentes clave de esa integración, pensados para un público gerencial.
1. Selección de pasarelas según perfil de mercado
Análisis de métodos preferidos: consultar estudios de mercado y datos propios (tarjeta de crédito, débito, wallets, transferencias bancarias locales, sistemas P2P) para priorizar integraciones.
Diversificación geográfica: en Latinoamérica incluir MercadoPago y Oxxo; en Europa, Stripe y Adyen; en Asia, Alipay y WeChat Pay; en EE. UU., PayPal y Apple Pay.
Evaluación de condiciones comerciales: comparar comisiones por transacción, plazos de liquidación, tarifas de chargeback y soporte de divisas.
2. Arquitectura desacoplada mediante microservicios de pagos
Servicio de orquestación de pago: microservicio independiente que expone una API REST (/initiate-payment, /verify-payment, /refund) y abstrae detalles de cada pasarela.
Adaptadores especializados (“payment adapters”): implementan la lógica de comunicación con cada proveedor (Stripe SDK, MercadoPago API, PayPal REST) y traducen respuestas a un formato común.
Patrón Circuit Breaker: encapsulado en cada adapter para aislar fallos de una pasarela y no afectar al resto; en caso de error persistente, marca el servicio como “unavailable”.
3. Flujo de autorización y captura de pagos
Autorization & Capture: en un primer paso se autoriza el monto (authorize), bloqueando fondos pero sin cobrarlos hasta confirmar la emisión de la boleta.
Captura diferida: luego, tras validación de integridad de boleta y emisión exitosa, se captura el pago (capture), minimizando riesgos de cobros fallidos.
Cancelación y reembolso automático: si la boleta se anula antes de la captura, se envía void para liberar el bloqueo; si ocurre post-captura, se emite refund parcial o total.
4. Seguridad y cumplimiento PCI-DSS
Nivel de certificación adecuado: si se almacenan tarjetas (para suscripciones), la plataforma debe ser PCI-DSS Level 1; si no, implementar solución “tokenization” del proveedor para no manipular datos sensibles.
Tokenización de tarjetas: al iniciar pago, el frontend invoca directamente a la pasarela para obtener un token de pago que sustituye al número real en las comunicaciones internas.
Entorno segregado: microservicios de pago corren en subred privada con acceso restringido, sin exponer puertos innecesarios ni credenciales en el código.
5. UX optimizado y flujos adaptativos
Checkout unificado: mostrar opciones de pago dinámicamente según país, dispositivo y perfil de usuario, evitando pantallas de “otros métodos” irrelevantes.
One-click payment: para usuarios recurrentes que hayan guardado su método preferido de forma tokenizada, ofrecer “pago rápido” evitando múltiple entrada de datos.
Formularios adaptativos WCAG: inputs accesibles, labels claros y soporte para lectores de pantalla, minimizando errores de validación de datos.
6. Reconciliación contable y gestión de transacciones
Webhooks y callbacks: cada pasarela notifica el estado de una transacción (payment_succeeded, payment_failed, chargeback) vía webhooks seguros, que el servicio de pago consume y guarda en la base de datos.
Cola de eventos: usar Kafka o SQS para procesar eventos de forma asíncrona, evitando bloqueos en transacciones concurrentes.
Cuadro de mando financiero: dashboard que cruza transacciones con boletas emitidas, conciliando confirmaciones y saldos pendientes, facilitando cierre diario.
7. Manejo de fraudes y riesgos
Rules engine y scoring: evaluar riesgo en tiempo real usando parámetros como monto, país, IP, dispositivo y comportamiento (velocity checks) para rechazar pagos sospechosos o solicitar MFA adicional.
Integración con servicios antifraude: conectarse a plataformas como Riskified, Sift o FraudLabs con APIs que devuelven “accept”, “review” o “decline”.
Alertas de chargeback: monitorizar notificaciones de disputa para iniciar procesos de recolección de evidencia (logs de emisión, firma, entrega de boleta) y defender la transacción.
8. Soporte a modelos de suscripción y pagos recurrentes
Planificación de ciclos: definir en el adapter billingInterval y billingCycleCount para crear suscripciones en Stripe/Adyen que emitan boletas periódicas automáticamente.
Webhooks de renovación: al recibirse evento invoice.paid o subscription.renewed, el motor de boletas consulta datos de suscripción y emite la nueva boleta, notificando al cliente.
Gestión de fallos de cobro: implementar “retry schedule” configurable y notificar al cliente tras X intentos fallidos, marcando la suscripción para revisión manual.
9. Pruebas, certificación y garantía de servicio
Entorno sandbox y pruebas end-to-end: validar cada adapter con escenarios de éxito, error, cancelación y reembolso en modo sandbox antes de pasar a producción.
Certificación anual: planificar auditorías internas o de terceros para revisar cumplimiento PCI-DSS y pruebas de seguridad de las integraciones.
SLA de transacciones: negociar con cada pasarela tiempos de autorización/captura < 2 s y tasas de uptime > 99,9 % para garantizar la experiencia de usuario.
10. Monitorización y mejora continua
Métricas clave: tiempo medio de autorización, tasa de éxito vs. error, tiempo de liquidación, tasa de chargeback, abandono en checkout.
Alertas en real-time: umbrales de error > 1 %, picos inusuales de rechazos o latencias elevadas, enviando notificaciones a Slack/Teams y disparando auto-scale si es necesario.
Feedback loop con marketing: compartir datos de compras fallidas por método de pago para ajustar oferta de pasarelas y optimizar conversiones en campañas futuras.
Conclusión persuasiva
Integrar una plataforma de boletas con sistemas de pago y pasarelas de cobro exige una arquitectura desacoplada, cumplimiento PCI-DSS, UX adaptativa, gestión de riesgos y reconciliación contable, todo ello orquestado por microservicios escalables y monitorizado en tiempo real. Para un director gerencial, esta integración no solo asegura una experiencia de compra confiable y sencilla para el cliente, sino que reduce el abandono, mitiga fraudes, acelera la liquidación de ingresos y fortalece la gobernanza financiera, generando un impacto directo en el ROI y la reputación de la organización.

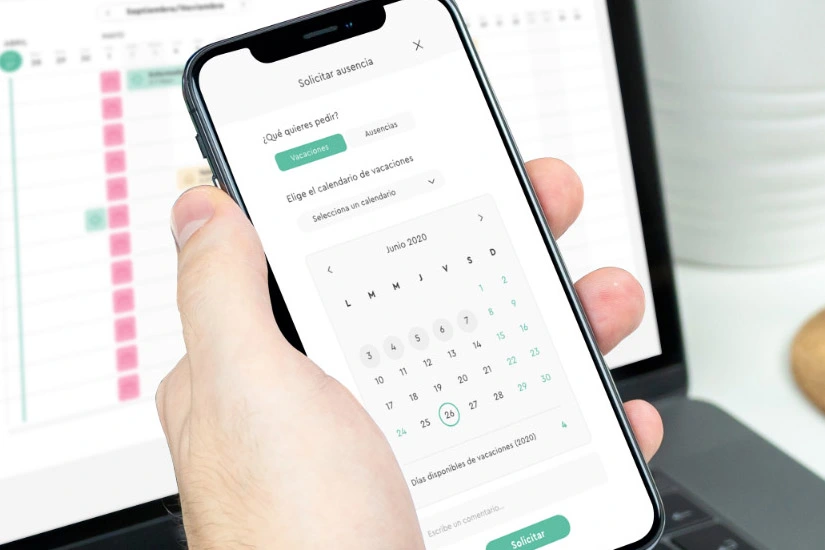
¿Qué políticas de retención y archivado aplicar a las boletas electrónicas?
En un entorno donde las boletas electrónicas (de venta, votación, inscripciones o servicios) adquieren valor contable, fiscal y legal, diseñar políticas claras de retención y archivado es imprescindible para garantizar cumplimiento normativo, eficiencia operativa y optimización de costos. A continuación, se presenta un marco de trabajo dividido en diez apartados, que cubre desde la definición de plazos hasta la selección de tecnologías de archivo, estructurado para directivos con responsabilidad estratégica.
1. Fundamentación legal y regulatoria
Marco fiscal: en muchos países, las boletas de venta constituyen comprobantes tributarios que deben conservarse por un mínimo de 5 a 10 años (por ejemplo, la normativa de IVA o similares).
Normativa sectorial: sectores como energía, salud o seguros suelen exigir plazos superiores o específicos para auditorías y reclamaciones; por ejemplo, boletas de servicios energéticos a usuarios pueden requerir retención de 10 años.
Regulaciones de protección de datos: GDPR y leyes locales (LGPD, CCPA) imponen que datos personales asociados a boletas no se retengan más allá de su propósito; se debe anonimizar o eliminar información de contacto una vez caduca la retención fiscal.
2. Clasificación de boletas según riesgos y valor
Categorías de retención:
Críticas—Fiscales y legales: retención obligatoria máxima (ej. 10 años).
Operativas—Control de acceso o votación interna: retención media (ej. 3 años), suficiente para resolver disputas internas.
Temporales—Promocionales o de acceso único: retención corta (6 meses–1 año), tras lo cual pueden eliminarse sin impacto.
Criterios de clasificación: basarse en atributos almacenados como metadatos (tipo de boleta, fecha de emisión, cliente, valor monetario) para aplicar políticas automáticas de ciclo de vida.
3. Definición de ciclos de vida y triggers de cambio de estado
Estados del documento:
Activo: boleta recientemente emitida, consultable en línea.
Inactivo: boleta expirada (fecha de vigencia superada) pero aún en retención obligatoria.
Archivado: fuera del sistema transaccional, movido a almacenamiento frío.
Eliminado: tras caducar plenitud de retención, destrucción irreversible.
Triggers de transición: eventos basados en fecha de emisión + metadato de categoría, que disparan automáticamente flujos de archivado o eliminación en el DMS o repositorio objeto.
4. Tecnologías de almacenamiento y estrategias de archivado
Almacenamiento caliente: para boletas activas, usar buckets o bases de datos con acceso rápido (S3 Standard, Azure Hot Blob), garantizando baja latencia y alta disponibilidad.
Almacenamiento frío: para boletas inactivas en retención—Glacier Deep Archive, Azure Archive—con costes de almacenamiento reducidos y tiempos de recuperación aceptables (horas).
Políticas de ciclo de vida: configurar reglas automáticas en S3 Lifecycle o Azure Blob Lifecycle para migrar objetos tras X días al tier apropiado, y luego borrar tras Y días.
5. Formatos y estándares de archivo
Formato maestro inmutable (PDF/A): para boletas con valor fiscal o legal, preservar en PDF/A-2 o PDF/A-3, asegurando inclusión de fuentes, metadatos XMP y ausencia de dependencias externas.
Envelope XML/JSON: incluir, junto al PDF, un manifiesto estructurado con metadatos detallados (ID de boleta, hash, firma digital, timestamps) para facilitar búsquedas y auditorías posteriores.
Checksum y hash: almacenar junto al objeto su checksum (SHA-256) en el manifest o en la base de datos de metadatos, permitiendo validaciones periódicas de integridad.
6. Gobernanza y roles de custodia
Responsables de retención: asignar “custodios” por grupo de boletas: finanzas (fiscales), operaciones (promocionales), IT (soporte de ciclo de vida).
Políticas aprobadas: documentar y aprobar la política de retención en el Comité de Compliance, con revisiones anuales o ante cambios regulatorios.
Escalamiento de excepciones: definir procesos para prórrogas puntuales (disputas de clientes, litigios) que suspendan la eliminación automática y notifiquen al área legal.
7. Automatización y orquestación de procesos
Workflows: usar un motor de workflows (Camunda, Azure Logic Apps) para implementar transiciones de estado:
Detectar boletas expiradas → mover a almacenamiento frío.
Tras periodo de retención → ejecutar job de purgado y registrar evento de destrucción.
Monitoreo de pendientes: dashboards de “pendientes de archivado” o “vencimiento de retención” que alerten a responsables con antelación (30–60 días antes).
8. Auditoría y compliance
Logs inmutables (WORM): cada cambio de estado (emitida, archivada, eliminada) se registra en un repositorio de logs Write Once Read Many, garantizando trazabilidad para auditorías fiscales o legales.
Informes periódicos: reportes automáticos que muestren volúmenes de boletas por categoría, estado actual y próximas eliminaciones, enviados a Compliance y Finanzas.
Requerimientos de auditor externo: asegurar que la infraestructura cumpla estándares ISO 27001 y auditorías PCI (si aplica), para respaldar evidencias.
9. Gestión de eliminación segura
Destrucción irreversible: para repositorios en la nube, invocar APIs de eliminación con “borrado seguro” o configurar reglas de retención cero, considerando tiempos de retención en cachés y backups.
Registro de destrucción: cada boleta eliminada deja un rastro en el blockchain privado o en la base de datos de metadatos, indicando ID, timestamp y responsable de la política.
Verificación post-destrucción: ejecutar jobs que comprueben que el objeto ya no existe y que hayan expirado las versiones previas (versioning) antes de liberar espacio.
10. Mejora continua y adaptación a cambios regulatorios
Revisión de políticas: cada año, analizar cambios en legislación tributaria o regulaciones de retención de datos para ajustar plazos y categorías.
Feedback de stakeholders: recoger comentarios de auditoría y áreas de negocio sobre flexibilidad de retención, facilidad para obtener boletas archivadas y tiempos de recuperación.
Evolución tecnológica: evaluar tecnologías emergentes como almacenamiento inmutable basado en blockchain para incrementar la confianza en el archivo y la trazabilidad descentralizada.
Conclusión persuasiva
Una política de retención y archivado de boletas electrónicas bien diseñada salvaguarda la conformidad legal, optimiza costos de almacenamiento y minimiza riesgos de auditoría. Al combinar clasificación inteligente, formatos estándar como PDF/A, automatización de ciclos de vida, almacenamiento tiered, logging WORM y roles claros de custodia, las organizaciones garantizan que cada boleta esté disponible mientras sea necesaria y se destruya de forma segura cuando expire. Para un director gerencial, estas prácticas se traducen en una gobernanza robusta, transparencia ante entes reguladores y una gestión eficiente de recursos, asegurando que la plataforma de boletas sea un activo ágil, confiable y alineado con la estrategia corporativa.
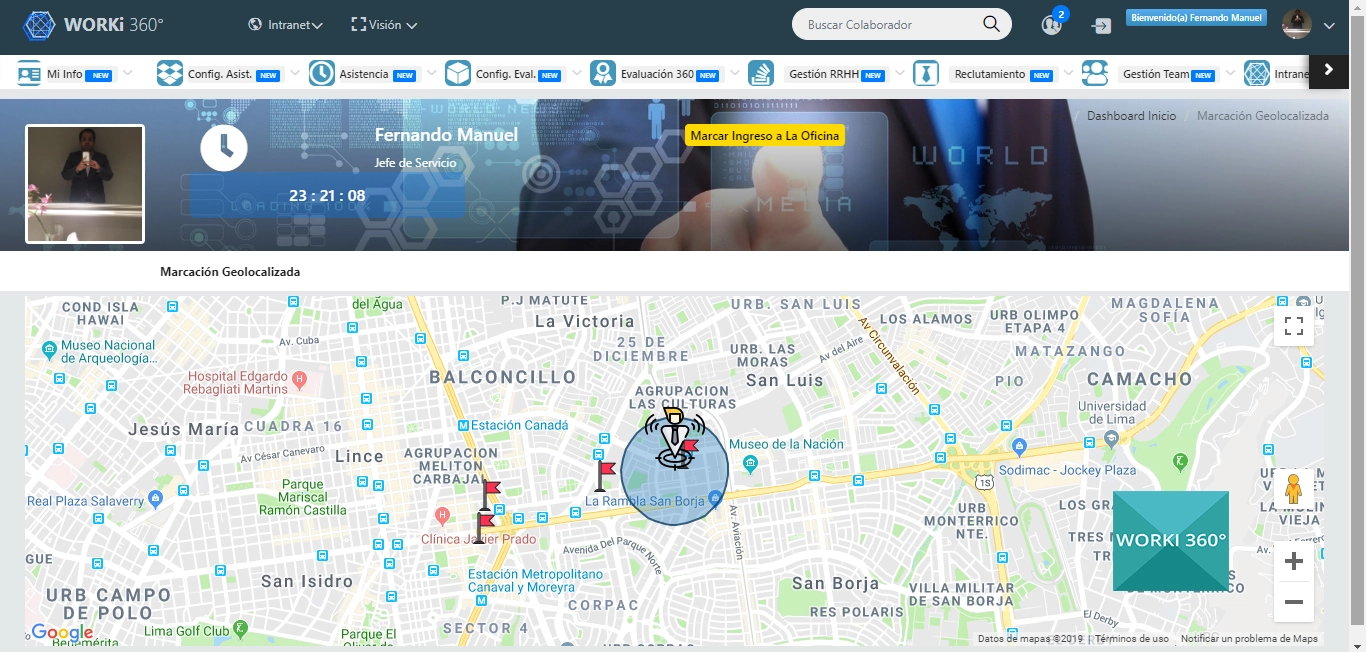
¿Cómo diseñar un dashboard gerencial con indicadores de emisión y recepción de boletas?
Contextualización y storytelling gerencial
En GlobalEvents Corp, antes de contar con un dashboard unificado, los gerentes de Operaciones, Marketing y Finanzas consultaban informes estáticos de emisión de boletas (ventas o inscripciones) y recibían datos de recepción (descargas, impresiones) por separado en Excel. Al carecer de una visión común, las decisiones eran reactivas: ajustes de precios tardíos, campañas de recordatorio mal sincronizadas y demoras en la conciliación contable. Fue el día que la Junta Ejecutiva solicitó “un panel único” que mostrara en tiempo real el estado de cada campaña, cuando los equipos se pusieron manos a la obra. Tras varias iteraciones, crearon un dashboard gerencial que transformó el seguimiento de boletas: detectaban cuellos de botella de emisión, medían el nivel de engagement de los usuarios y acortaban el cierre financiero de semanas a días.
1. Definición de objetivos y audiencia
Stakeholders identificados: Junta Directiva (visión global), Directores de área (detalle operacional), Analistas financieros (conciliación), Marketing (engagement) y Soporte (incidencias).
Preguntas clave a responder:
¿Cuántas boletas hemos emitido en el período X?
¿Cuál es la tasa de recepción efectiva (descargas/impresiones) por canal?
¿Existen picos o caídas de emisión que puedan indicar problemas de sistema?
¿Cómo evolucionan los indicadores comparados con campañas anteriores?
¿Cuál es el tiempo medio de emisión y de entrega al usuario final?
Objetivos SMART: específicos, medibles, alcanzables, relevantes y temporales; por ejemplo, “Reducir un 20 % el tiempo medio de emisión antes de fin de trimestre”.
2. Selección de indicadores (KPIs) esenciales
Volumen de emisión: total de boletas generadas por día, semana y mes, segmentadas por campaña y canal de emisión.
Tasa de recepción: porcentaje de boletas descargadas o impresas frente a las emitidas, indicando éxito en entrega.
Tiempo medio de emisión: latencia desde la solicitud hasta la disponibilidad de la boleta en el repositorio.
Errores de emisión: número y tasa de boletas que fallaron (plantillas faltantes, datos inválidos).
Engagement post-emisión: métricas de apertura de emails/SMS con enlace a la boleta y clic-through rate.
Coste por boleta: coste de procesamiento (cómputo, licencias, notificaciones) dividido por total de boletas.
Nivel de satisfacción: NPS o CSAT de usuarios finales tras recibir y consultar su boleta.
3. Arquitectura de datos y almacenamiento intermedio
Data Mart específico: diseñar un esquema estrella donde la tabla de hechos contenga registros de emisión y recepción con dimensiones de tiempo, campaña, canal, región y tipo de boleta.
ETL/ELT automatizado: pipelines diarios con herramientas como Azure Data Factory, Talend o Apache Airflow que integran logs de microservicios, eventos de SIEM y datos de comunicación (email/SMS).
Almacenamiento en DW: utilizar Snowflake, Redshift o Azure Synapse para cargar los datos preprocesados, manteniendo tablas particionadas por fecha para rendimiento.
4. Diseño UX/UI adaptado a directivos
Visión de alto nivel (Executive Summary): en la parte superior, indicadores clave (KPI cards) con valores actuales y variación porcentual respecto al período anterior.
Sección analítica: gráficos de serie de tiempo (line charts) para emisión y recepción, con filtros por campaña, canal y región.
Matriz de heatmap: mostrar volumen de emisión vs. recepción por hora del día y canal, identificando ventanas críticas.
Gráficos de embudo: representar el flujo desde emisión → notificación → descarga/impresión → confirmación de uso.
Tabla de detalle: lista paginada de boletas con estado (emitida, entregada, fallida), tiempo de procesamiento, canal y enlace al log de trazabilidad.
5. Interactividad y filtros avanzados
Filtros dinámicos: desplegables para seleccionar rangos de fecha, campañas, canales, regiones y segmentos de usuarios.
Drill-down y drill-through:
Drill-down: pasar de volúmenes agregados por mes a visión diaria o por hora.
Drill-through: desde un KPI de error, acceder directamente al detalle de las boletas fallidas y al mensaje de error registrado.
What‐if analysis: permitir simular escenarios (por ejemplo, aumento del 10 % en la tasa de descarga) para medir impacto en engagement y coste.
6. Visualización de alertas y umbrales
Semáforos y gauges: para KPIs críticos (tasa de error, tasa de recepción) con colores rojo/amarillo/verde según umbrales.
Alertas en el dashboard: notificaciones embebidas que destaquen desviaciones importantes (por ejemplo, tasa de error > 2 %).
Suscripciones: capacidad de que directivos se suscriban a reportes PDF generados automáticamente y firmados digitalmente, recibidos por email o Teams cada mañana.
7. Integración con herramientas de BI y colaboración
Power BI / Tableau / Qlik: desplegar el dashboard en la plataforma corporativa, aprovechando SSO y control de acceso basado en roles.
Comentarios y wikis integrados: habilitar espacio para notas colaborativas directamente sobre cada gráfico, dejando registro de discusiones.
APIs de consulta: exponer endpoints protegidos que permitan extraer datos brutos para integrarlos en portales o apps móviles de la organización.
8. Rendimiento y escalabilidad
Modelo de agregaciones precomputadas: usar tablas materializadas o vistas indexadas para KPIs pesados y consultas frecuentes.
Cache de visualizaciones: habilitar cache en el nivel de BI para reducir tiempos de carga (< 3 s).
Monitorización de queries: analizar y optimizar consultas SQL de mayor latencia, ajustando índices y particiones.
9. Gobernanza y seguridad de la información
Control de acceso granular: definir qué roles pueden ver qué datos (por campaña, región), evitando exposición de boletas de alto valor.
Enmascaramiento de datos sensibles: ocultar o tokenizar información personal en el dashboard (por ejemplo, ID de cliente), cumpliendo GDPR/CCPA.
Auditoría de acceso: registrar quién, cuándo y qué se consultó en el dashboard, alimentando el SIEM y generando alertas de accesos inusuales.
10. Ciclo de mejora continua y validación de valor
Feedback periódico: reuniones mensuales con usuarios clave para recoger sugerencias de nuevos KPIs, ajustes de visualización y necesidades emergentes.
Métricas de adopción: medir número de usuarios activos del dashboard, tiempo medio de sesión y consultas más frecuentes, identificando áreas de formación o mejora.
Evolución del roadmap: priorizar mejoras (nuevos filtros, integraciones, visualizaciones) en sprints ágiles, manteniendo un backlog vivo alineado a objetivos estratégicos.
Conclusión persuasiva
Un dashboard gerencial para emisión y recepción de boletas es más que un conjunto de gráficos: es una herramienta estratégica que centraliza información crítica, acelera la detección de incidencias, alinea a todos los actores y permite decisiones proactivas. Al definir objetivos claros, seleccionar KPIs relevantes, diseñar una arquitectura de datos robusta y aplicar principios UX, seguridad y gobernanza, la organización pasa de informes fragmentados a una visión única y fiable. Para un director gerencial, esta iniciativa no solo optimiza procesos operativos y financieros, sino que impulsa la transparencia internamente y refuerza la reputación de la empresa ante clientes y reguladores.
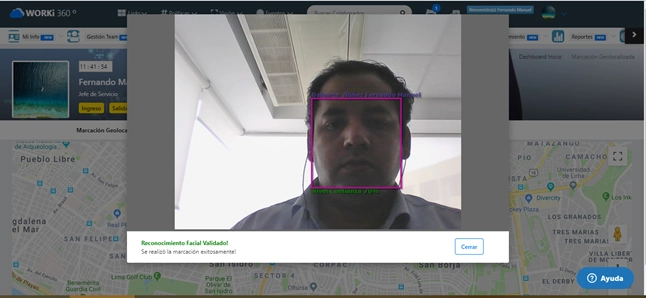
¿Qué retos presenta la accesibilidad (WCAG) en la emisión y consulta de boletas?
Contextualización y storytelling gerencial
En SaludPlus, la plataforma de emisión de boletas de atención al paciente creció rápidamente, pero pronto recibieron quejas de usuarios con discapacidad visual y motriz: no podían completar el proceso de obtención de su boleta de pago ni leerla correctamente. El director de Tecnología, Javier Morales, entendió que sin accesibilidad, se excluía a un segmento importante de clientes y se corrían riesgos legales bajo la normativa de WCAG y leyes de igualdad. Puso en marcha un proyecto para auditar y rediseñar cada paso —desde la generación automática de PDF hasta el portal web de consulta— asegurando cumplimiento de los estándares WCAG 2.1 y PDF/UA, y transformando un requisito de cumplimiento en un factor de inclusión y satisfacción.
1. Compatibilidad con lectores de pantalla y contenido semántico
Etiquetado ARIA y roles semánticos: Las boletas deben estructurarse en HTML o XML con elementos

¿Cómo aplicar IA para detectar anomalías o fraudes en las boletas generadas?
Contextualización y storytelling gerencial En EnerGo, multinacional de servicios energéticos, el equipo de Operaciones detectó un patrón inquietante: ciertos consumidores recibían boletas con montos inusualmente bajos o altos, y tras analizarlas manualmente, se descubrieron errores sistémicos y posibles manipulaciones maliciosas. Ante el volumen masivo de boletas (más de 500 000 mensuales), resultaba inviable revisar cada caso a mano. El Director de Riesgos, Sofía Gutiérrez, impulsó entonces un proyecto de Inteligencia Artificial (IA) que, en pocas semanas, comenzó a señalar automáticamente las boletas sospechosas, permitiendo concentrar las auditorías en el 0,5 % de los casos con mayor probabilidad de fraude o error y reduciendo pérdidas en un 15 %. A continuación, un marco detallado en diez pasos para diseñar e implementar una solución de IA para detección de anomalías y fraudes en boletas. 1. Definición de objetivos y casos de uso Detección de errores de cálculo: boletas con totales que no coinciden con la suma de ítems y descuentos. Identificación de patrones atípicos: montos muy superiores o inferiores al promedio histórico de un cliente, segmento o región. Anomalías en frecuencia de emisión: boletas múltiples para un mismo cliente en un corto intervalo de tiempo. Detección de boletas duplicadas o reconstruidas: hashes o metadatos que sugieran generación masiva automatizada fuera de horarios habituales. 2. Recolección y preparación de datos Fuentes de datos: registros de boletas (base de datos transaccional), logs de sistema de generación, información histórica de consumo o compra, datos de cliente (segmentación, ubicación), logs de uso de interfaz (IP, agente de usuario). Enriquecimiento de features: Features temporales: día de la semana, hora del día, período de facturación. Features geográficos: región, país, distancia al punto de emisión. Features de cliente: antigüedad, frecuencia de emisión previa, promedio de monto. Normalización y limpieza: eliminar valores nulos, unificar formatos de fecha y moneda, filtrar boletas de prueba o emitidas por sistemas de staging. 3. Selección de técnicas y algoritmos de detección Modelos no supervisados de detección de anomalías (sin datos etiquetados): Isolation Forest: construye árboles que separan puntos de datos mediante particiones aleatorias; las anomalías se aíslan más rápido. One-Class SVM: traza una frontera en el espacio de features que contiene la mayoría de los datos “normales”; fuera de esa frontera son anomalies. Autoencoders: redes neuronales que aprenden a reconstruir datos de entrenamiento normativos; los fallos de reconstrucción (alto error) indican puntos atípicos. Modelos supervisados (cuando existan etiquetas históricas de fraude): Random Forest / XGBoost: árboles de decisión que ponderan features para clasificar boletas como legítimas o fraudulentas. Redes profundas (MLP): permiten capturar relaciones no lineales entre múltiples variables de contexto. 4. Entrenamiento, validación y ajuste de hiperparámetros Conjunto de entrenamiento: seleccionar el 70 % de boletas con historial limpio y, en su caso, disponiblizar un pequeño conjunto de boletas marcadas como problemáticas (fraude detectado manualmente). Conjunto de validación y test: el 30 % restante, garantizando representación proporcional de la distribución de montos y clientes. Técnicas de validación cruzada: k-fold cross-validation para estimar la estabilidad del detector y evitar sobreajuste. Optimización de hiperparámetros: grid search o Bayesian optimization para parámetros de Isolation Forest (n_estimators, max_samples) o autoencoder (épocas, tamaño de capas, tasa de aprendizaje). 5. Evaluación y métricas de eficacia Tasa de detección (Recall): proporción de boletas fraudulentas correctamente identificadas. Precisión (Precision): proporción de boletas marcadas como anomalías que realmente lo son. F1-Score: métrica armónica que equilibra precision y recall, especialmente útil ante clases desbalanceadas. AUC-ROC: curva de caracterización de trade-off entre tasa de verdaderos positivos y tasa de falsos positivos. Tasa de falsos positivos (FPR): porcentaje de boletas normales marcadas erróneamente, que genera carga de trabajo adicional. 6. Implementación en producción con pipelines MLOps Contenerización de modelos: empaquetar el modelo entrenado, junto con su entorno Python y dependencias (scikit-learn, TensorFlow), en un contenedor Docker. Despliegue de servicio de predicción: exponer un endpoint REST o gRPC (/score-boleto) que reciba datos de boleta y devuelva un score de anomalía. Orquestación de inferencia: integrarlo en el pipeline de generación de boletas: tras emisión, llamar al servicio para evaluar el score y registrar el resultado en la base de datos de eventos. 7. Integración con flujos de alerta y gestión de excepciones Umbral dinámico vs. fijo: definir un threshold de score (p. ej., > 0.8 en normalized anomaly score) o ajustar dinámicamente según distribution drift. Clasificación de riesgo: convertir el score en categorías (bajo, medio, alto riesgo) para priorizar revisiones manuales. Workflow de aprobación: boletas de alto riesgo se marcan automáticamente como “pendientes de auditoría”, notificando al equipo de Compliance con toda la información contextual y el historial de eventos. 8. Monitoreo continuo y mantenimiento del modelo Drift detection: medir la deriva de datos en las variables clave (montos, frecuencia) usando técnicas como Population Stability Index (PSI) y activar reentrenamiento cuando supere umbrales. Reentrenamiento periódico: programar jobs semanales o mensuales que incorporen nuevos datos y feedback de la auditoría manual, manteniendo el modelo actualizado. A/B testing de modelos: probar versiones nuevas en paralelo con el modelo actual para comparar métricas de detección en producción antes de reemplazarlo. 9. Visualización y dashboards de fraude Heatmap de anomalías: región vs. tiempo con concentración de boletas de alto riesgo. Gráfico de barras: número de boletas analizadas vs. número marcadas por categoría de riesgo. Drill-down: desde una anomalía identificada, acceso al detalle de la boleta, variables más influyentes (SHAP values) y ruta de auditoría. Tendencias de performance del modelo: evolución de precision, recall y FPR en el tiempo, para visualizar impactos de derivación o cambios en el negocio. 10. Cultura organizacional y gobernanza de IA Roles y responsabilidades: definir claramente quiénes son responsables de validar alertas, ajustar umbrales y supervisar reentrenamientos (Data Scientists, Compliance, TI). Transparencia y explicabilidad: emplear herramientas de explainable AI (SHAP, LIME) para justificar ante auditores y directivos por qué una boleta se marcó como anomalía. Políticas de ética y sesgo: revisar que el modelo no discrimine ciertos segmentos de clientes (edad, ubicación), documentando procesos y audiencias. Conclusión persuasiva La aplicación de IA para detectar anomalías y fraudes en boletas permite pasar de la revisión reactiva y manual a un mecanismo proactivo y escalable. Con un pipeline que abarca desde la preparación de datos y entrenamiento de modelos de detección no supervisada o supervisada, hasta la implementación MLOps, la definición de flujos de alerta y la gobernanza de IA, las organizaciones garantizan reducción de pérdidas, mejora en la confianza de los clientes y cumplimiento regulatorio. Para un director gerencial, invertir en estas capacidades significa no solo proteger los márgenes y la reputación de la empresa, sino también transformarlas en un activo estratégico que potencia la eficiencia y la resiliencia del negocio.
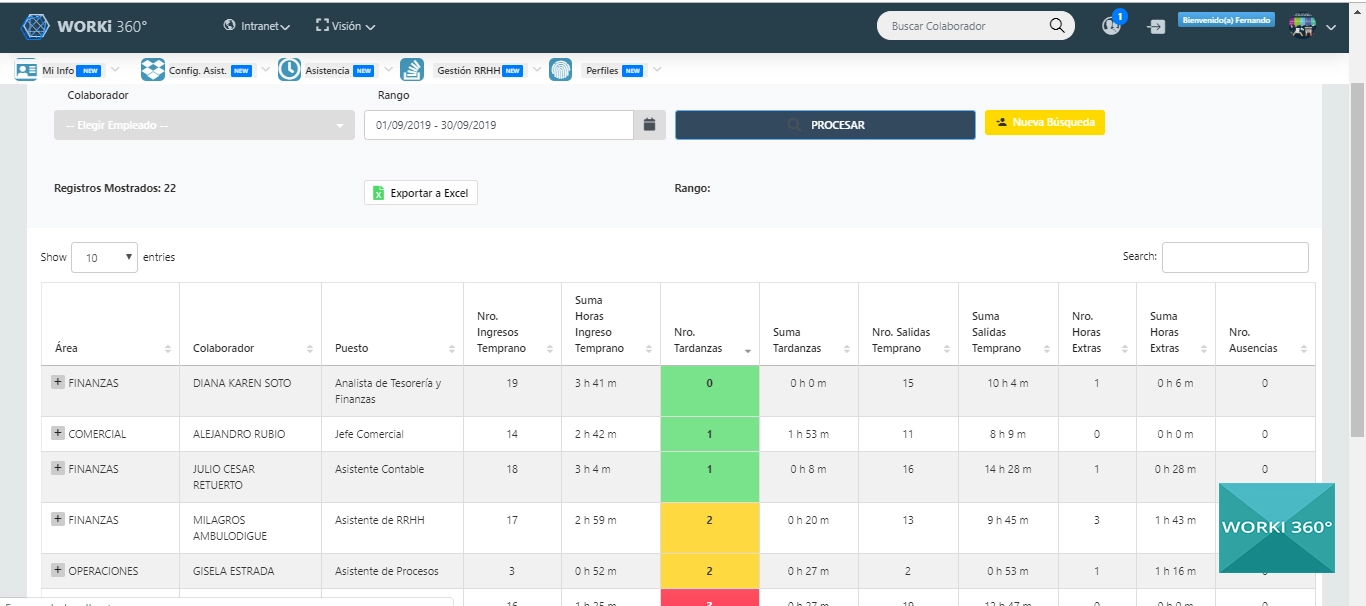
¿Qué métricas clave (TPV, tiempo de emisión, tasa de error) medir para evaluar su desempeño?
Para un director gerencial, disponer de un conjunto de métricas sólidas y accionables es esencial para monitorizar, optimizar y justificar la inversión en una plataforma de emisión de boletas. A continuación se describen las diez métricas más determinantes, cómo calcularlas y qué acciones derivar de cada una. 1. Volumen Total de Procesamiento (TPV) Definición: Número total de boletas generadas en un periodo (diario, semanal, mensual). Cálculo: Suma de todos los eventos de emisión registrados en el sistema de logging. Por qué importa: Muestra la carga de trabajo real y el crecimiento de la plataforma, sirviendo de referencia para dimensionar infraestructura y licenciamiento. Acciones: Ajustar escalado automático (autoscaling) si el TPV crece un 20 % mensual. Planificar capacidad adicional (instancias, licencias) antes de picos esperados. 2. Tiempo Medio de Emisión (TME) Definición: Duración promedio desde que se recibe la solicitud hasta que la boleta queda disponible (PDF firmado o código generado). Cálculo: Promedio de (timestamp_fin – timestamp_inicio) para cada boleta en el periodo. Por qué importa: Refleja la agilidad del sistema; retrasos aquí impactan la experiencia de usuario y el throughput operacional. Objetivo: Mantener el TME por debajo de 2 segundos en el 95 % de las solicitudes. Acciones: Optimizar código de generación y pipelines de firma. Escalar workers de renderizado en carretes de alta demanda. 3. Tasa de Éxito vs. Error de Emisión Definición: Porcentaje de boletas emitidas sin incidencias frente al total de solicitudes. Cálculo: 1 – (número de errores de emisión / TPV) × 100 %. Por qué importa: Una tasa de error alta implica fallos de plantilla, falta de datos o caídas de servicios críticos. Umbral: Error < 0,5 %. Acciones: Monitorear y clasificar errores (render, firma, almacenamiento). Implementar reintentos automáticos y dashboard de excepciones para corrección manual. 4. Tasa de Recepción y Descarga Definición: Proporción de boletas realmente descargadas o impresas por el usuario tras emisión. Cálculo: boletas descargadas / boletas emitidas × 100 %. Por qué importa: Mide la efectividad de la entrega y la adopción de la plataforma; una brecha puede indicar problemas de notificación o usabilidad. Benchmark: > 90 %. Acciones: Revisar flujos de notificación (email, SMS) y tiempos de envío. Mejorar UX/UI de la pantalla de acceso y descarga de boletas. 5. Tiempo al Primer Pueblo (Time to First Access) Definición: Tiempo medio entre emisión y primera visualización o descarga de cada boleta. Cálculo: Promedio de (timestamp_primer_acceso – timestamp_emisión). Por qué importa: Indica la efectividad de notificaciones y la urgencia percibida por el usuario. Objetivo: < 60 segundos. Acciones: Acelerar envíos de notificaciones y optimizar enlaces de descarga. Enviar recordatorios automáticos si no hay acceso en X minutos. 6. Latencia de Sistemas Dependientes Definición: Medición de la latencia en servicios críticos (firma digital, base de datos, colas de mensajería) durante la emisión. Cálculo: Promedio y percentiles (P95, P99) de llamadas a APIs externas y consultas a bases de datos implicadas en el flujo. Por qué importa: Identifica cuellos de botella externos que impactan el TME. Acciones: Implementar caches intermedios y circuit breakers. Negociar SLAs más estrictos con proveedores de firma y KMS. 7. Uptime y Disponibilidad de la Plataforma Definición: Porcentaje de tiempo en que el servicio de emisión está operativo y responde correctamente. Cálculo: (tiempo_total – tiempo_caídas) / tiempo_total × 100 %. Por qué importa: Alta disponibilidad (> 99,9 %) es crítica para evitar interrupciones durante picos. Acciones: Revisar arquitecturas de alta disponibilidad y failover automático. Realizar drills de recuperación ante desastres y probar con Chaos Engineering. 8. Uso de Recursos y Coste por Boleta Definición: Recursos consumidos (CPU, memoria, I/O) y coste asociado (infraestructura, licencias, mensajería) dividido por el número de boletas. Cálculo: (Coste_total_periodo) / TPV. Por qué importa: Permite optimizar la eficiencia económica y justificar la inversión. Acciones: Migrar a instancias spot/preemptibles en cargas no críticas. Ajustar parámetros de compresión y reducción de payloads. 9. Nivel de Satisfacción del Usuario Definición: Índices de satisfacción (CSAT) o Net Promoter Score (NPS) medidos tras emisión o descarga de boleta. Cálculo: Encuestas integradas en la plataforma que piden una valoración rápida (1–5) o una recomendación. Por qué importa: Mide la percepción de velocidad, usabilidad y confiabilidad. Acciones: Analizar comentarios negativos para priorizar mejoras UI/UX. Celebrar y difundir casos de éxito para reforzar la adopción interna. 10. Tiempo de Resolución de Incidencias Definición: Tiempo medio desde que se detecta una incidencia (falla de emisión, descarga, pago) hasta que queda resuelta. Cálculo: Promedio de (timestamp_resolución – timestamp_reporte) por ticket. Por qué importa: Un SLA interno de 2 horas en resolución mejora la confianza de usuarios y operaciones. Acciones: Refinar procesos de soporte y escalado automático a segundo nivel. Integrar monitoreo y tickets automáticos en el workflow de DevOps. 🧾 Resumen Ejecutivo Con WORKI 360, la plataforma de emisión de boletas se convierte en un sistema data-driven, donde cada métrica –desde el Volumen Total de Procesamiento hasta el Tiempo de Resolución de Incidencias– se integra en un panel centralizado que permite a la dirección: Tomar decisiones informadas: visibilidad en tiempo real de TPV, latencias críticas y tasas de error. Optimizar recursos: reducir costes por boleta y dimensionar infraestructura con base en usage patterns. Mejorar la experiencia: acortar el tiempo medio de emisión y maximizar la tasa de recepción, elevando la satisfacción del cliente. Garantizar el cumplimiento SLA: monitoreo proactivo de uptime y tiempo de resolución de incidencias, mitigando riesgos operativos. Implementar estas métricas con WORKI 360 no solo asegura la gobernanza y la eficiencia de la plataforma de boletas, sino que transforma los datos operativos en palancas de crecimiento, calidad de servicio y excelencia competitiva.