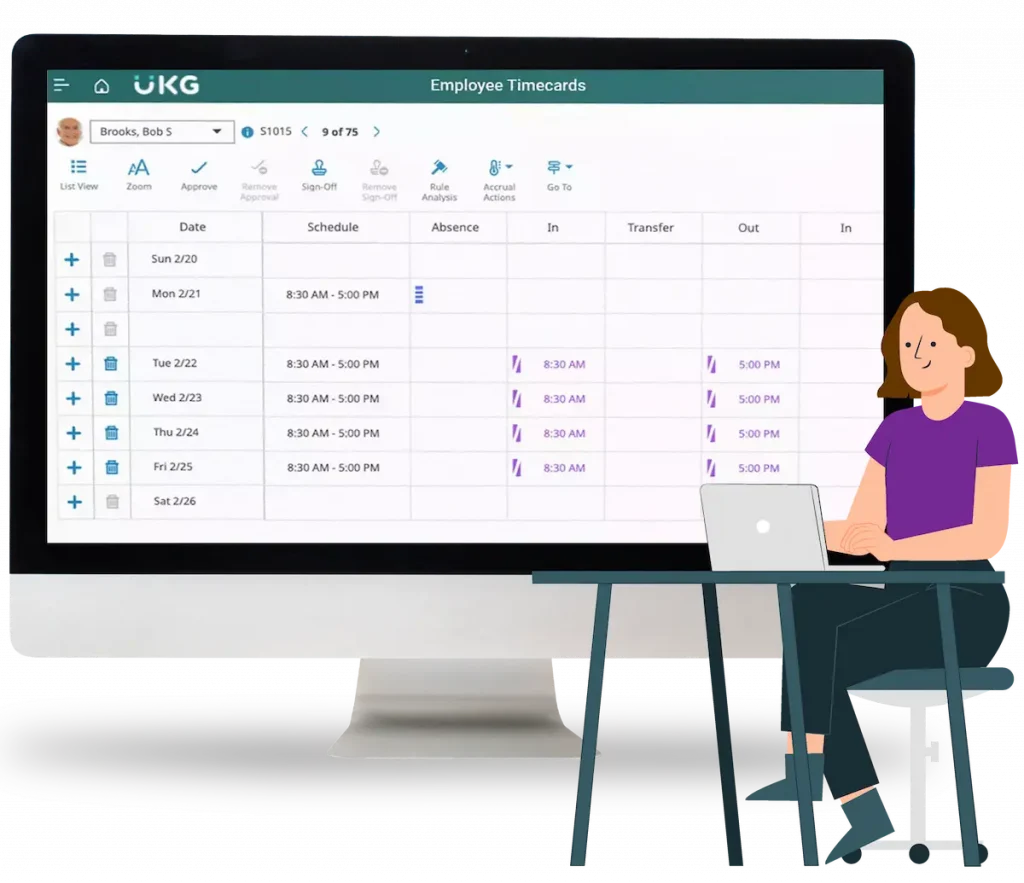

Índice del contenido
¿Cómo un curso de Python para datos mejora la eficiencia en análisis de información?
En la era del Big Data, los ingenieros, científicos de datos y analistas se enfrentan a volúmenes masivos de información, provenientes de sensores, bases de datos, simulaciones y procesos industriales. La eficiencia en el análisis de esta información es crucial para tomar decisiones precisas, optimizar recursos y garantizar la competitividad de la organización. Un curso de Python para datos no solo enseña a programar, sino que desarrolla competencias avanzadas que permiten automatizar procesos, integrar fuentes de datos diversas y realizar análisis complejos de manera rápida y confiable. A continuación, se detallan las principales formas en que un curso de Python mejora la eficiencia en el análisis de información. 1. Automatización de procesos de análisis Python permite automatizar tareas repetitivas que tradicionalmente consumen tiempo en hojas de cálculo o herramientas manuales: Limpieza y transformación de datos masivos mediante librerías como Pandas y NumPy. Procesamiento automático de información proveniente de múltiples archivos o bases de datos. Creación de scripts que ejecutan cálculos complejos y reportes periódicos de manera confiable. Esto reduce considerablemente el tiempo dedicado a tareas manuales y minimiza errores humanos, aumentando la eficiencia del equipo. 2. Integración de múltiples fuentes de datos Un curso avanzado enseña a: Conectar Python con bases de datos SQL, Excel, APIs y archivos CSV. Consolidar información de distintas fuentes en un solo flujo de trabajo. Actualizar datos automáticamente para mantener análisis dinámicos y confiables. La integración permite que los ingenieros trabajen con datos precisos, actualizados y coherentes, optimizando el análisis. 3. Procesamiento de grandes volúmenes de datos Python es altamente eficiente para manejar datasets grandes o complejos, gracias a: Librerías optimizadas como Pandas, NumPy y Dask. Manejo de estructuras de datos avanzadas (DataFrames, arrays multidimensionales). Capacidad de realizar operaciones masivas de manera rápida y eficiente. Esto permite analizar información que sería inviable con herramientas tradicionales, acelerando la toma de decisiones. 4. Visualización avanzada de información La eficiencia no solo depende de procesar datos, sino de interpretarlos: Creación de gráficos interactivos y dinámicos con Matplotlib, Seaborn y Plotly. Desarrollo de dashboards que consolidan KPIs, tendencias y alertas. Visualización clara de patrones, correlaciones y anomalías en los datos. Estas habilidades permiten que los resultados sean comprensibles y accionables para equipos técnicos y gerenciales. 5. Análisis predictivo y modelado de tendencias Python permite aplicar técnicas avanzadas de análisis: Modelos estadísticos y machine learning con scikit-learn. Predicción de resultados y proyección de tendencias a partir de datos históricos. Simulación de escenarios y análisis de sensibilidad para evaluar impactos de variables clave. Esto permite a los ingenieros anticipar problemas, optimizar recursos y planificar estrategias con base en datos reales. 6. Reducción de errores y mayor confiabilidad Python permite implementar scripts que validan datos automáticamente. La automatización y control de flujos de trabajo reduce errores de cálculo y procesamiento manual. La reproducibilidad de los análisis garantiza que los resultados sean consistentes y auditables. Esto fortalece la precisión y confiabilidad de los análisis de información. 7. Desarrollo de habilidades estratégicas Más allá de la técnica, un curso de Python para datos fomenta: Pensamiento estructurado y lógico para organizar análisis complejos. Capacidad de sintetizar grandes volúmenes de información en insights accionables. Competencias para comunicar resultados de manera clara y profesional. Estas habilidades permiten que los equipos tomen decisiones estratégicas basadas en datos confiables. 8. Aplicación en distintos sectores de ingeniería y ciencia Ingeniería civil: análisis de costos, cronogramas y eficiencia de procesos constructivos. Ingeniería mecánica: simulaciones de sistemas, dimensionamiento y optimización. Ingeniería eléctrica y electrónica: consumo energético, rendimiento de sistemas y confiabilidad. Ciencia de datos y procesos industriales: predicciones, monitoreo de KPIs y mantenimiento predictivo. Esto demuestra que Python es versátil y aplicable en múltiples contextos técnicos. 9. Beneficios estratégicos para la organización Incremento de productividad y eficiencia en análisis de datos. Reducción de errores y retrabajos en cálculos y reportes. Mayor rapidez en la generación de insights para toma de decisiones. Optimización de recursos y planificación basada en información confiable. Mejora de la competitividad y capacidad de innovación de la organización. 10. Conclusión Un curso de Python para datos transforma la manera en que los ingenieros y analistas procesan, interpretan y comunican información. Al combinar automatización, integración de datos, visualización avanzada y análisis predictivo, los equipos pueden trabajar de manera más eficiente, precisa y estratégica, asegurando que los proyectos sean gestionados con mayor confiabilidad y productividad, y que las decisiones se tomen con base en datos sólidos y verificables.
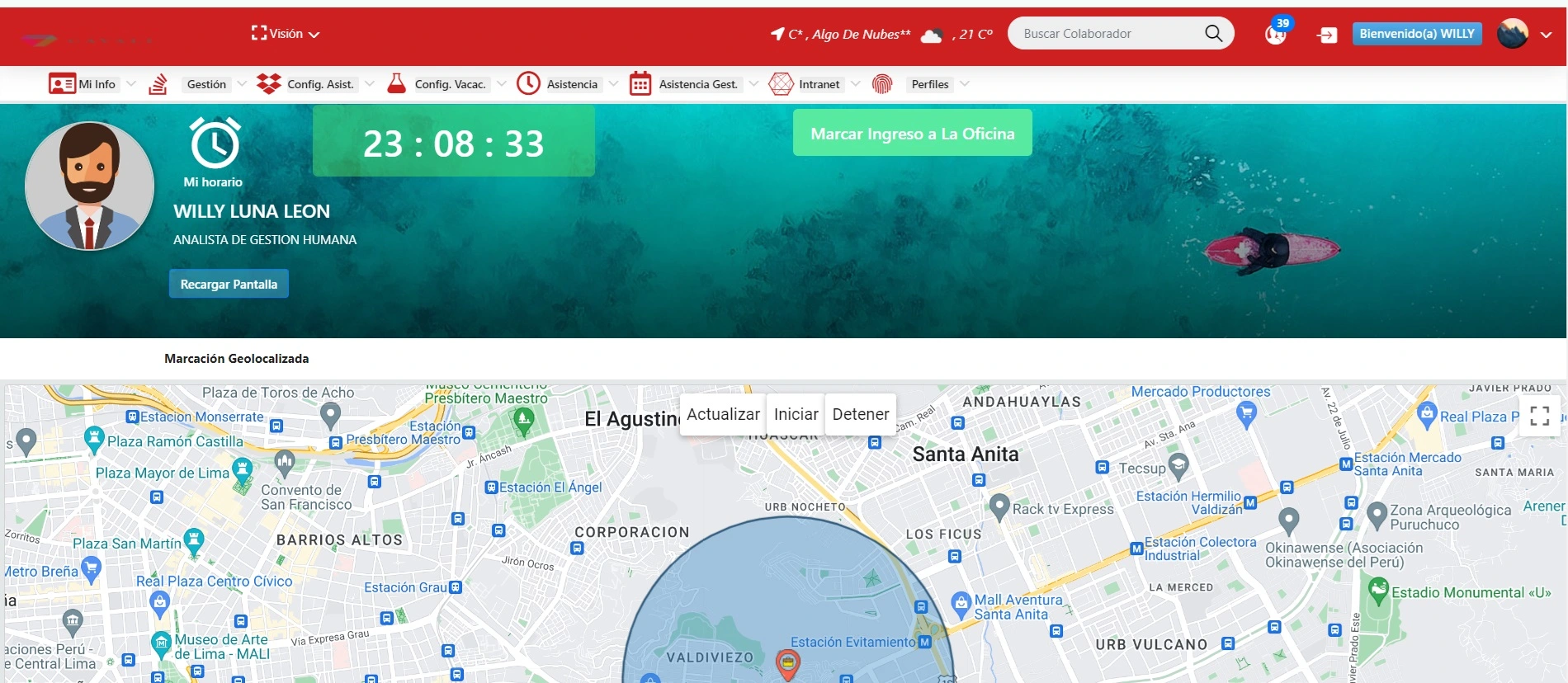
¿Qué competencias avanzadas se desarrollan en Python específicamente para manejo de datos?
Un curso de Python orientado al manejo de datos no solo enseña a programar, sino que desarrolla competencias técnicas, analíticas y estratégicas que permiten a los profesionales transformar grandes volúmenes de información en insights valiosos para la toma de decisiones. Estas habilidades son fundamentales en ingeniería, ciencia de datos, análisis industrial y cualquier entorno donde la eficiencia y precisión de la información sea crítica. A continuación, se detallan las competencias avanzadas que se desarrollan al dominar Python para manejo de datos. 1. Manipulación avanzada de datos con Pandas y NumPy Los participantes aprenden a: Crear, modificar y combinar estructuras de datos complejas (DataFrames y arrays multidimensionales). Realizar operaciones masivas de manera eficiente sobre grandes datasets. Filtrar, agrupar y resumir información para obtener insights claros y accionables. Estas habilidades permiten procesar y organizar datos complejos de manera rápida y confiable. 2. Limpieza y transformación de datos Identificar y corregir datos faltantes, inconsistentes o duplicados. Transformar variables, normalizar unidades y convertir formatos de datos. Automatizar procesos de limpieza usando scripts y funciones personalizadas. Esto garantiza que los análisis se basen en información confiable y de alta calidad. 3. Integración con bases de datos y otras herramientas Los participantes desarrollan habilidades para: Conectar Python con SQL, Excel, APIs y sistemas industriales. Extraer, transformar y cargar datos (ETL) de manera automatizada. Integrar información de distintas fuentes en un único flujo de análisis. Esto permite que los equipos trabajen con datos coherentes y actualizados, optimizando procesos. 4. Visualización avanzada de datos Creación de gráficos dinámicos e interactivos con Matplotlib, Seaborn y Plotly. Desarrollo de dashboards que muestran KPIs, tendencias y alertas. Aplicación de visualizaciones para comunicar resultados complejos de forma clara y profesional. Estas competencias permiten interpretar y comunicar información de manera efectiva a distintos stakeholders. 5. Análisis estadístico y modelado de datos Aplicación de técnicas estadísticas básicas y avanzadas. Cálculo de correlaciones, regresiones, distribuciones y probabilidades. Implementación de modelos predictivos y análisis de tendencias para proyectar resultados. Esto fortalece la capacidad de tomar decisiones informadas y estratégicas basadas en datos cuantitativos. 6. Automatización de flujos de trabajo Creación de scripts para procesar datos de forma repetitiva y automática. Generación de reportes periódicos y dashboards actualizados. Reducción de errores humanos y optimización de tiempo en análisis rutinarios. La automatización aumenta la eficiencia y confiabilidad de los procesos de análisis. 7. Aplicación de técnicas de machine learning y análisis predictivo Uso de librerías como scikit-learn para clasificación, regresión y clustering. Construcción de modelos de predicción basados en datos históricos. Evaluación y validación de modelos para asegurar precisión y confiabilidad. Esto permite anticipar tendencias, optimizar procesos y mejorar la planificación estratégica. 8. Manejo de grandes volúmenes de datos y Big Data Uso de librerías y herramientas optimizadas para datasets extensos. Procesamiento eficiente de información proveniente de sensores, IoT o sistemas industriales. Capacidad de realizar análisis complejos sin pérdida de rendimiento. Estas habilidades son críticas para proyectos de gran escala y entornos industriales modernos. 9. Buenas prácticas y documentación de análisis Organización de scripts y notebooks para mantener claridad y reproducibilidad. Documentación de procesos, fórmulas y pasos de análisis para auditoría y seguimiento. Estandarización de flujos de trabajo para equipos interdisciplinarios. Esto asegura consistencia, trazabilidad y profesionalismo en los proyectos de análisis de datos. 10. Aplicación en distintos sectores Ingeniería civil: análisis de costos, planificación de obra y seguimiento de KPIs. Ingeniería mecánica y eléctrica: simulaciones, optimización de sistemas y predicción de fallas. Procesos industriales y manufactura: monitoreo de productividad, mantenimiento predictivo y eficiencia operativa. Ciencia de datos y analítica empresarial: análisis de tendencias, segmentación y toma de decisiones estratégicas. Esto demuestra que Python es versátil y aplicable en múltiples entornos técnicos y estratégicos. Conclusión Un curso avanzado de Python para manejo de datos desarrolla competencias que permiten procesar, limpiar, analizar y comunicar información de manera eficiente y confiable. Los participantes adquieren habilidades técnicas, analíticas y estratégicas que transforman datos en insights valiosos, reduciendo errores, optimizando recursos y fortaleciendo la toma de decisiones en proyectos complejos.
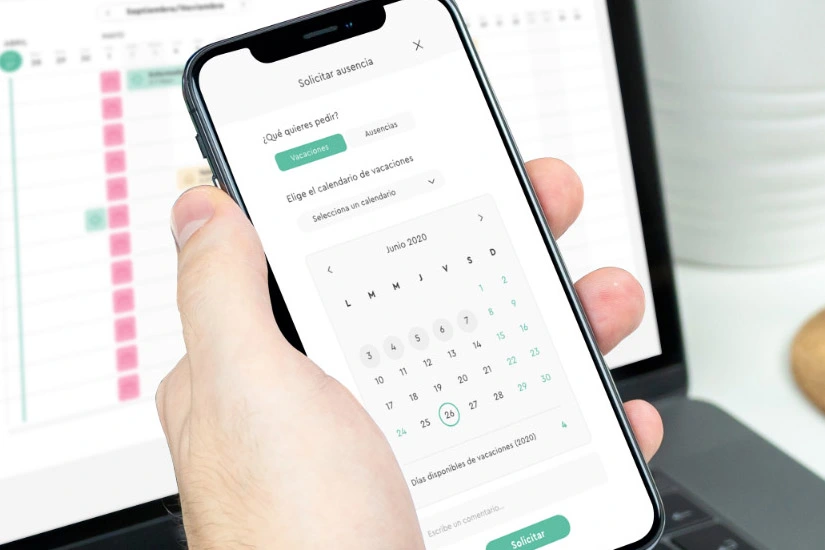
¿Cómo usar Python para procesar y limpiar grandes volúmenes de datos?
En ingeniería, ciencia de datos y análisis industrial, los proyectos generan grandes cantidades de información, que suelen estar incompletos, inconsistentes o desestructurados. El procesamiento y limpieza de estos datos es esencial para asegurar que los análisis sean precisos, confiables y útiles para la toma de decisiones. Python, con librerías especializadas como Pandas y NumPy, permite manejar y preparar datos de manera eficiente, automatizando tareas que de otra forma serían tediosas y propensas a errores. Un curso avanzado de Python para datos enseña estrategias, herramientas y buenas prácticas para procesar y limpiar grandes volúmenes de información de manera profesional. 1. Importación y consolidación de datos Python permite trabajar con datos provenientes de múltiples fuentes: Archivos CSV, Excel, JSON y bases de datos SQL. Datos provenientes de APIs, sensores o IoT. Integración de información dispersa en un único DataFrame para análisis unificado. Esto facilita que los ingenieros tengan todos los datos disponibles de manera estructurada y lista para procesar. 2. Identificación y manejo de datos faltantes Detectar valores nulos o vacíos utilizando funciones de Pandas (isnull(), notnull()). Imputación de valores mediante métodos estadísticos, promedios o técnicas avanzadas. Eliminación de registros incompletos que no aportan al análisis. Esto asegura que los cálculos y modelos se basen en información completa y confiable. 3. Detección y corrección de inconsistencias Identificación de datos duplicados o contradictorios. Normalización de formatos, unidades y nomenclaturas. Transformación de tipos de datos para que sean consistentes (int, float, datetime, etc.). Esto reduce errores y garantiza que los análisis sean coherentes y precisos. 4. Filtrado y segmentación de datos Aplicación de condiciones y filtros avanzados para seleccionar subconjuntos relevantes. Agrupación de datos por categorías, fechas o indicadores clave. Combinación de múltiples criterios para análisis detallado. Estas técnicas permiten extraer información significativa de grandes volúmenes de datos de manera rápida y eficiente. 5. Transformación y preparación de datos para análisis Creación de nuevas variables derivadas de los datos originales. Aplicación de funciones matemáticas y estadísticas a columnas completas. Reestructuración de datasets para análisis específicos o visualización. Esto garantiza que los datos estén listos para modelado, visualización y análisis predictivo. 6. Automatización del procesamiento Desarrollo de scripts que ejecutan limpieza y transformación de datos de manera repetitiva. Aplicación de pipelines de datos para flujos continuos de información. Reducción de intervención manual y errores asociados. La automatización incrementa la eficiencia y reproducibilidad del análisis. 7. Manejo de grandes volúmenes de datos Uso de estructuras de datos optimizadas con NumPy y Pandas para datasets extensos. Aplicación de técnicas de procesamiento por lotes o paralelización. Capacidad de trabajar con millones de registros sin perder rendimiento. Esto permite a los ingenieros analizar Big Data con rapidez y confiabilidad. 8. Validación y control de calidad Verificación de rangos y consistencia de valores. Comparación con estándares, benchmarks o datos históricos. Documentación de transformaciones y pasos de limpieza para auditoría. Esto garantiza que los datos procesados sean precisos, confiables y auditables. 9. Aplicaciones prácticas en ingeniería y ciencia Ingeniería civil: consolidación de mediciones de obra, control de costos y cronogramas. Ingeniería mecánica y eléctrica: análisis de resultados de simulaciones y pruebas experimentales. Procesos industriales: monitoreo de producción, eficiencia y mantenimiento predictivo. Ciencia de datos: preparación de datasets para machine learning y análisis exploratorio. Esto demuestra que la limpieza y procesamiento de datos es aplicable en diversos contextos técnicos y estratégicos. 10. Conclusión Usar Python para procesar y limpiar grandes volúmenes de datos permite a los ingenieros y analistas trabajar con información precisa, coherente y estructurada, lo que fortalece la calidad de los análisis y la confiabilidad de los resultados. Un curso avanzado enseña a consolidar, depurar, transformar y automatizar datos de manera profesional, incrementando la eficiencia, reduciendo errores y facilitando la toma de decisiones estratégicas basadas en datos sólidos.

¿Qué librerías de Python son esenciales para análisis de datos en ingeniería y ciencia?
Python se ha consolidado como una herramienta líder en análisis de datos debido a su versatilidad, eficiencia y amplia comunidad de desarrollo. Para ingenieros, científicos y analistas, conocer las librerías clave permite procesar, analizar y visualizar información de manera rápida y confiable, además de facilitar la integración con otros sistemas y herramientas de ingeniería. Un curso avanzado de Python para datos enseña el uso estratégico de estas librerías, optimizando el flujo de trabajo y la toma de decisiones. A continuación, se detallan las librerías esenciales y sus aplicaciones en proyectos de ingeniería y ciencia. 1. Pandas Permite manipulación y análisis de datos estructurados mediante DataFrames y Series. Funciones para limpieza, filtrado, agregación y transformación de datos. Ideal para consolidar información de múltiples fuentes y preparar datasets para análisis y visualización. Aplicaciones: análisis de costos, seguimiento de KPIs, consolidación de datos de sensores o registros experimentales. 2. NumPy Librería fundamental para cálculos numéricos y operaciones con arrays multidimensionales. Optimiza operaciones matemáticas complejas y manejo de grandes volúmenes de datos. Soporta funciones estadísticas, algebra lineal y manipulación eficiente de matrices. Aplicaciones: simulaciones, cálculos estructurales, procesamiento de señales y análisis de series temporales. 3. Matplotlib Librería estándar para visualización de datos estáticos. Permite crear gráficos de líneas, barras, dispersión, histogramas y personalizados. Es altamente configurable, lo que facilita la presentación profesional de resultados técnicos. Aplicaciones: generación de reportes gráficos, monitoreo de procesos y presentación de análisis de ingeniería. 4. Seaborn Construida sobre Matplotlib, facilita visualizaciones estadísticas más atractivas e intuitivas. Permite gráficos de correlación, distribuciones, mapas de calor y diagramas avanzados. Ideal para análisis exploratorio de datos (EDA) y visualización de tendencias. Aplicaciones: análisis de patrones en producción, control de calidad y evaluación de resultados experimentales. 5. SciPy Librería especializada en cálculo científico y técnico. Incluye funciones de optimización, integración, interpolación, álgebra lineal y estadísticas avanzadas. Complementa NumPy y Pandas para resolver problemas complejos de ingeniería y ciencia. Aplicaciones: simulaciones físicas, optimización de diseños y análisis de confiabilidad. 6. scikit-learn Librería líder para machine learning y análisis predictivo. Permite clasificación, regresión, clustering, reducción de dimensionalidad y validación de modelos. Incluye herramientas para evaluar precisión y rendimiento de modelos. Aplicaciones: predicción de fallas, análisis de eficiencia, optimización de procesos y modelado de tendencias. 7. Plotly y Dash Plotly permite visualización interactiva y dinámica de datos. Dash facilita la creación de dashboards web interactivos integrando análisis y visualización. Ideal para comunicar resultados a stakeholders de manera intuitiva. Aplicaciones: dashboards de seguimiento de proyectos, KPIs y análisis de desempeño en tiempo real. 8. OpenPyXL y xlwings Librerías para integrar Python con Excel, leer y escribir datos en hojas de cálculo. Facilitan la automatización de reportes, extracción de información y actualización de documentos corporativos. Aplicaciones: consolidación de reportes técnicos, generación de dashboards y análisis de datos financieros. 9. TensorFlow y PyTorch (avanzado) Librerías para machine learning avanzado y deep learning. Permiten modelar redes neuronales para predicción y clasificación compleja. Recomendadas para proyectos que requieren análisis avanzado de datos o simulaciones inteligentes. Aplicaciones: mantenimiento predictivo, simulaciones de sistemas complejos, análisis de grandes volúmenes de datos no estructurados. 10. Beneficios estratégicos del dominio de librerías Procesamiento rápido y eficiente de grandes volúmenes de datos. Reducción de errores en cálculos y análisis complejos. Capacidad de integrar datos de múltiples fuentes y plataformas. Visualización clara y profesional para comunicación con equipos y stakeholders. Preparación para implementar machine learning y análisis predictivo en proyectos de ingeniería y ciencia. Conclusión Dominar las librerías esenciales de Python para análisis de datos permite a los profesionales procesar, limpiar, analizar y visualizar información de manera eficiente y confiable. Un curso avanzado enseña no solo la técnica, sino también cómo aplicar estas herramientas estratégicamente, optimizando procesos, fortaleciendo la toma de decisiones y mejorando la competitividad de proyectos en ingeniería, ciencia y análisis industrial.

¿Cómo integrar Python con Excel, SQL y otras bases de datos?
En el análisis de datos, los profesionales de ingeniería, ciencia y negocios necesitan consolidar información proveniente de fuentes heterogéneas, incluyendo hojas de cálculo, bases de datos relacionales y sistemas industriales. Python permite integrar y automatizar el flujo de datos entre estas plataformas, lo que incrementa la eficiencia, reduce errores y fortalece la toma de decisiones. Un curso avanzado de Python para datos enseña cómo conectar y manipular datos provenientes de múltiples fuentes, asegurando que los análisis sean coherentes, precisos y dinámicos. 1. Integración con Excel Python facilita la interacción con hojas de cálculo mediante librerías especializadas: Pandas: lectura y escritura de archivos Excel (read_excel() y to_excel()), permitiendo procesar grandes volúmenes de datos. OpenPyXL: manipulación de celdas, formatos, fórmulas y estilos en archivos Excel. xlwings: conexión directa entre Python y Excel para automatizar reportes y actualizar hojas en tiempo real. Aplicaciones: consolidación de reportes técnicos, generación de dashboards automáticos y actualización de datos experimentales o financieros. 2. Integración con bases de datos SQL Python permite conectar y manipular bases de datos relacionales: Uso de librerías como SQLAlchemy y PyODBC para conectarse a bases de datos SQL Server, MySQL, PostgreSQL, Oracle, entre otras. Ejecución de consultas (SELECT, JOIN, WHERE) directamente desde Python. Extracción de datos para análisis, limpieza, transformación y visualización. Aplicaciones: análisis de registros históricos, monitoreo de sistemas industriales y consolidación de datos de proyectos multidisciplinares. 3. Extracción y procesamiento de datos desde APIs y servicios web Python permite integrarse con APIs para obtener información dinámica: Uso de requests para acceder a datos en formato JSON o XML desde servicios externos. Transformación de datos provenientes de sensores IoT o sistemas de monitoreo. Automatización de flujos de datos en tiempo real. Aplicaciones: seguimiento de KPIs en tiempo real, análisis de datos de sensores industriales y recopilación de información para dashboards interactivos. 4. Automatización de flujos de trabajo Consolidación de datos de Excel, SQL y APIs en un único script de Python. Limpieza, transformación y validación automática de datos. Generación de reportes y dashboards dinámicos sin intervención manual. Esto reduce errores humanos y acelera el análisis de datos de manera significativa. 5. Preparación de datos para análisis avanzado Transformación de datos crudos en formatos adecuados para visualización o modelado. Creación de DataFrames consolidados listos para análisis estadístico o machine learning. Validación de consistencia y control de calidad de información proveniente de distintas fuentes. Esto asegura que los análisis sean precisos, reproducibles y confiables. 6. Visualización y comunicación de resultados Integración de datos consolidados en gráficos interactivos con Plotly o Seaborn. Generación de dashboards que combinan información de Excel, SQL y sistemas externos. Presentación clara de resultados técnicos y estratégicos a stakeholders. Esto fortalece la toma de decisiones basada en datos confiables y consolidados. 7. Aplicaciones prácticas en ingeniería y ciencia Ingeniería civil: consolidación de presupuestos y avances de obra desde múltiples fuentes. Ingeniería mecánica: análisis de resultados de simulaciones y pruebas experimentales. Procesos industriales: integración de datos de sensores, producción y mantenimiento predictivo. Ciencia de datos: preparación de datasets para análisis exploratorio y machine learning. La integración de Python con Excel y SQL permite procesar información compleja de manera eficiente. 8. Beneficios estratégicos Reducción de errores al evitar transcripciones manuales. Mayor eficiencia en la consolidación y análisis de datos. Flujo de trabajo unificado y automatizado. Capacidad de generar insights rápidos y precisos para la toma de decisiones. Optimización de recursos y aumento de productividad de los equipos. 9. Habilidades clave desarrolladas Los participantes aprenden a: Conectar Python con Excel, bases de datos SQL y APIs externas. Automatizar la extracción, limpieza y consolidación de datos. Integrar información para análisis avanzado y visualización profesional. Mantener consistencia y calidad de los datos en proyectos multidisciplinares. Estas habilidades fortalecen la capacidad analítica y estratégica de los profesionales. 10. Conclusión Integrar Python con Excel, SQL y otras bases de datos permite a los ingenieros y analistas gestionar información de manera más eficiente, precisa y confiable. Un curso avanzado enseña a consolidar datos, automatizar flujos de trabajo y generar análisis y visualizaciones profesionales, incrementando la productividad, reduciendo errores y fortaleciendo la toma de decisiones basada en datos sólidos.

¿Qué ventajas ofrece enseñar automatización de procesos de análisis con Python?
En el manejo de datos en ingeniería, ciencia y análisis industrial, gran parte del tiempo de los profesionales se invierte en procesos repetitivos, como limpieza de información, generación de reportes o consolidación de datos. La enseñanza de automatización con Python permite que estas tareas se ejecuten de manera rápida, precisa y consistente, liberando tiempo para análisis estratégicos y toma de decisiones. Un curso avanzado de Python no solo enseña programación, sino que desarrolla habilidades de eficiencia, control de calidad y optimización de recursos. A continuación, se detallan las ventajas estratégicas de la automatización de procesos con Python. 1. Ahorro de tiempo en tareas repetitivas Automatización de limpieza y transformación de datos de múltiples fuentes. Consolidación automática de archivos CSV, Excel o bases de datos. Generación de reportes periódicos y dashboards sin intervención manual. Esto permite que los equipos dedique más tiempo a análisis estratégicos y menos a tareas operativas. 2. Reducción de errores humanos Los scripts automatizados aplican procesos consistentes cada vez que se ejecutan. Eliminación de errores comunes por manipulación manual de datos. Validación automática de datos y resultados en cada ejecución. Esto mejora la precisión y confiabilidad de los análisis y reportes. 3. Estandarización de procesos Creación de flujos de trabajo uniformes para todos los proyectos. Aplicación de reglas y transformaciones de manera consistente en distintos datasets. Documentación clara de procesos y scripts reproducibles. La estandarización permite que los análisis sean coherentes y auditables, facilitando la colaboración en equipos multidisciplinarios. 4. Manejo eficiente de grandes volúmenes de datos Procesamiento de datasets extensos que serían inviables manualmente. Uso de librerías como Pandas, NumPy y Dask para optimizar operaciones masivas. Automatización de cálculos complejos y consolidación de información en minutos. Esto incrementa la capacidad de análisis y eficiencia en proyectos de gran escala. 5. Integración con otras plataformas Automatización de flujos entre Python, Excel, SQL y APIs externas. Consolidación de datos de distintas fuentes para análisis integral. Actualización automática de dashboards y reportes basados en datos nuevos. Esto permite que los equipos trabajen con información precisa, confiable y en tiempo real. 6. Facilita análisis avanzados y predictivos Scripts automatizados preparan datasets listos para análisis estadístico o machine learning. Generación de simulaciones y escenarios sin intervención manual. Integración con librerías como scikit-learn para predicciones automáticas. La automatización acelera la exploración de alternativas y la toma de decisiones estratégicas. 7. Mejora en la visualización y presentación de resultados Actualización automática de gráficos y dashboards interactivos. Resaltado de alertas y anomalías en tiempo real. Creación de reportes profesionales para stakeholders sin esfuerzo adicional. Esto fortalece la comunicación efectiva y la toma de decisiones basada en datos. 8. Beneficios estratégicos Incremento de productividad y eficiencia del equipo. Reducción de errores y retrabajos en procesos de análisis. Capacidad de manejar proyectos complejos y grandes volúmenes de datos. Toma de decisiones más rápida y fundamentada en datos confiables. Optimización de recursos humanos al reducir tareas repetitivas. 9. Desarrollo de habilidades clave Los participantes aprenden a: Crear scripts para automatizar limpieza, transformación y análisis de datos. Integrar Python con Excel, bases de datos y APIs externas. Generar dashboards, reportes y análisis de manera automatizada. Mantener procesos reproducibles, consistentes y auditables. Estas habilidades fortalecen la eficiencia, precisión y capacidad estratégica del equipo. 10. Conclusión Enseñar automatización de procesos con Python permite a los profesionales trabajar de manera más eficiente, precisa y estratégica, eliminando tareas repetitivas y propensas a errores. La automatización no solo optimiza el análisis de datos, sino que fortalece la toma de decisiones, mejora la productividad del equipo y garantiza resultados confiables y consistentes, convirtiéndose en una ventaja competitiva para cualquier organización.
¿Cómo usar Python para análisis predictivo y modelado de tendencias?
En ingeniería, ciencia y negocios, anticipar resultados futuros y entender patrones en los datos es clave para la planificación estratégica, optimización de procesos y toma de decisiones informadas. Python, con sus librerías avanzadas de análisis y machine learning, permite realizar análisis predictivo y modelado de tendencias de manera eficiente, precisa y escalable. Un curso avanzado de Python para datos enseña cómo aplicar estas técnicas para convertir datos históricos en insights accionables y confiables. A continuación, se detallan los pasos y ventajas de utilizar Python para análisis predictivo y modelado de tendencias. 1. Preparación de los datos El análisis predictivo requiere datos limpios, consistentes y estructurados: Consolidación de datasets históricos y actuales con Pandas. Limpieza de valores nulos o inconsistentes y normalización de variables. Transformación de datos en formatos adecuados para modelado y predicción. Esto garantiza que los modelos se construyan sobre información confiable y representativa. 2. Análisis exploratorio de datos (EDA) Antes de modelar, es fundamental entender los datos: Uso de gráficos y estadísticas descriptivas para identificar patrones, tendencias y outliers. Correlación entre variables para determinar relaciones importantes. Segmentación de datos para identificar grupos y comportamientos específicos. El EDA permite seleccionar variables relevantes y diseñar modelos más precisos. 3. Selección de modelos predictivos Python ofrece librerías robustas para machine learning y modelado estadístico: scikit-learn para regresión lineal, regresión múltiple, clasificación y clustering. statsmodels para análisis estadístico avanzado y series temporales. Prophet o ARIMA para predicción de tendencias y pronósticos temporales. La selección del modelo depende del tipo de datos, objetivo del análisis y precisión requerida. 4. Entrenamiento y validación del modelo División de datos en conjuntos de entrenamiento y prueba para evaluar desempeño. Ajuste de hiperparámetros y selección de variables relevantes. Validación de resultados mediante métricas como RMSE, R², accuracy y precision. Esto garantiza que los modelos sean confiables y aplicables a escenarios reales. 5. Aplicación de análisis predictivo Predicción de resultados futuros basados en datos históricos. Identificación de tendencias, patrones estacionales y cambios en el comportamiento de variables. Simulación de escenarios “what-if” para anticipar impactos de decisiones estratégicas. Esto permite a los equipos planificar de manera proactiva y optimizar recursos. 6. Visualización de tendencias y resultados Gráficos de líneas, dispersión y series temporales con Matplotlib y Seaborn. Dashboards interactivos con Plotly y Dash para monitoreo en tiempo real. Representación clara de predicciones y rangos de incertidumbre para stakeholders. La visualización facilita la comprensión y comunicación de resultados predictivos. 7. Automatización de procesos predictivos Creación de scripts que actualizan modelos y predicciones con nuevos datos. Integración con bases de datos y Excel para consolidación y reporte automático. Generación de alertas y dashboards dinámicos basados en resultados de predicción. Esto optimiza la eficiencia y confiabilidad del análisis de tendencias. 8. Aplicaciones prácticas en ingeniería y ciencia Ingeniería civil: predicción de costos, avance de obra y recursos requeridos. Ingeniería mecánica y eléctrica: proyección de desempeño de sistemas y mantenimiento predictivo. Procesos industriales: pronóstico de producción, eficiencia y fallas en equipos. Ciencia de datos y análisis empresarial: predicción de demanda, tendencias de mercado y comportamiento de clientes. Estas aplicaciones muestran que Python es versátil y aplicable a múltiples contextos técnicos y estratégicos. 9. Beneficios estratégicos Mejora en la planificación y toma de decisiones estratégicas. Anticipación de riesgos y desviaciones en proyectos. Optimización de recursos y eficiencia operativa. Reducción de costos y retrabajos mediante predicciones confiables. Incremento de la competitividad y capacidad de innovación de la organización. 10. Conclusión Usar Python para análisis predictivo y modelado de tendencias permite a los profesionales transformar datos históricos en insights precisos y accionables. Un curso avanzado enseña cómo preparar, modelar, validar y visualizar predicciones de manera profesional, automatizando procesos y fortaleciendo la toma de decisiones basada en datos confiables. Esto mejora la eficiencia, reduce riesgos y optimiza recursos en proyectos de ingeniería, ciencia y análisis industrial.
¿Cómo crear dashboards interactivos con Python?
En ingeniería, ciencia y análisis de datos, la capacidad de visualizar información de manera clara, dinámica e interactiva es crucial para la toma de decisiones. Los dashboards interactivos permiten a los equipos monitorear KPIs, identificar tendencias y detectar desviaciones en tiempo real, transformando datos complejos en información accionable. Python, con librerías avanzadas como Plotly y Dash, ofrece herramientas potentes para crear dashboards profesionales que integran análisis y visualización de manera efectiva. Un curso avanzado de Python para datos enseña cómo diseñar dashboards interactivos que optimicen la comunicación de resultados y la gestión de proyectos. 1. Definición de objetivos y métricas Antes de construir un dashboard: Identificar KPIs y métricas clave que reflejen el desempeño del proyecto. Determinar la audiencia: gerentes, ingenieros o clientes, para adaptar la visualización. Establecer la frecuencia de actualización y las fuentes de datos. Esto asegura que el dashboard sea relevante, claro y funcional. 2. Preparación y consolidación de datos Uso de Pandas para limpiar, transformar y consolidar datos de distintas fuentes (Excel, SQL, APIs). Normalización de variables y creación de indicadores derivados. Validación de consistencia y calidad de la información antes de la visualización. Los datos preparados garantizan que el dashboard muestre resultados precisos y confiables. 3. Selección de librerías y herramientas Plotly: permite crear gráficos interactivos (líneas, barras, dispersión, mapas y más). Dash: framework para construir dashboards web interactivos que combinan gráficos, filtros y tablas dinámicas. Seaborn y Matplotlib: para gráficos complementarios o análisis exploratorio previo. Estas herramientas permiten diseñar dashboards dinámicos, atractivos y fáciles de usar. 4. Diseño de dashboards interactivos Distribución lógica de secciones: KPIs, gráficos de tendencias, alertas y tablas. Uso de filtros interactivos para explorar datos por períodos, categorías o variables específicas. Aplicación de colores, iconos y formatos condicionales para resaltar información crítica. Un diseño profesional facilita la interpretación rápida y precisa de la información. 5. Automatización y actualización dinámica Conexión con fuentes de datos en tiempo real o periódicamente. Scripts que actualizan dashboards automáticamente con nueva información. Integración de alertas visuales para detectar desviaciones o eventos críticos. Esto permite que los dashboards se mantengan siempre actualizados y útiles para la gestión estratégica. 6. Visualización de tendencias y patrones Gráficos de series temporales para identificar tendencias y estacionalidad. Diagramas de dispersión y correlación para evaluar relaciones entre variables. Mapas de calor y gráficos combinados para análisis avanzado de desempeño. La visualización interactiva facilita la comprensión de relaciones complejas y la identificación de oportunidades o riesgos. 7. Aplicaciones prácticas Ingeniería civil: seguimiento de avances de obra, consumo de materiales y presupuestos. Ingeniería mecánica y eléctrica: monitoreo de rendimiento de sistemas y eficiencia energética. Procesos industriales: control de producción, mantenimiento predictivo y KPIs operativos. Ciencia de datos y análisis empresarial: dashboards de ventas, demanda, comportamiento de clientes y predicciones. Esto demuestra la versatilidad y relevancia de dashboards interactivos en distintos contextos. 8. Beneficios estratégicos Mayor rapidez y precisión en la toma de decisiones. Visualización clara de tendencias, anomalías y oportunidades. Reducción de errores y retrabajos al consolidar información centralizada. Comunicación efectiva entre equipos técnicos, gerentes y stakeholders. Incremento de eficiencia, productividad y competitividad organizacional. 9. Desarrollo de habilidades clave Los participantes adquieren competencias para: Construir dashboards interactivos y dinámicos con Python. Integrar información de múltiples fuentes en visualizaciones coherentes. Aplicar filtros, alertas y elementos interactivos para análisis avanzado. Automatizar la actualización y presentación de resultados en tiempo real. Estas habilidades fortalecen la capacidad de análisis, visualización y comunicación de datos estratégicos. 10. Conclusión Crear dashboards interactivos con Python permite a los profesionales transformar grandes volúmenes de datos en información clara, dinámica y accionable. Un curso avanzado enseña a diseñar dashboards que integren análisis, visualización y automatización, mejorando la toma de decisiones, la eficiencia operativa y la comunicación estratégica en proyectos de ingeniería, ciencia y análisis industrial.

¿Cómo aplicar análisis de sensibilidad y escenarios en Python?
En proyectos de ingeniería, ciencia y negocios, los resultados dependen de múltiples variables que pueden variar a lo largo del tiempo. El análisis de sensibilidad y escenarios permite evaluar cómo los cambios en estas variables impactan los resultados finales, facilitando la planificación estratégica, la gestión de riesgos y la optimización de recursos. Python, con librerías avanzadas y herramientas de simulación, permite realizar estos análisis de manera eficiente, reproducible y escalable. Un curso avanzado de Python para datos enseña cómo aplicar estas técnicas para anticipar problemas, proyectar resultados y tomar decisiones basadas en datos sólidos. 1. Comprender el análisis de sensibilidad Identificar las variables clave que afectan los resultados del proyecto. Determinar cómo pequeñas variaciones en cada variable influyen en los indicadores de desempeño. Priorizar los factores críticos para la toma de decisiones estratégicas. Esto permite a los profesionales enfocar recursos y acciones en los aspectos que más impactan el proyecto. 2. Preparación de datos para análisis Consolidación de datos históricos y actuales mediante Pandas. Limpieza y normalización de variables para asegurar consistencia. Transformación de datos para ser compatibles con modelos de simulación o análisis predictivo. La preparación garantiza que los resultados del análisis sean precisos y confiables. 3. Creación de escenarios Definición de escenarios base, optimista y pesimista según variables críticas. Configuración de múltiples escenarios “what-if” para evaluar impactos. Simulación de escenarios complejos usando bucles y estructuras condicionales en Python. Esto permite comparar alternativas y anticipar posibles desviaciones. 4. Uso de librerías de Python NumPy: operaciones matemáticas y simulaciones. Pandas: manipulación de datasets y consolidación de resultados. SciPy: optimización y análisis estadístico avanzado. Plotly / Matplotlib / Seaborn: visualización de resultados y comparaciones entre escenarios. Estas herramientas permiten realizar análisis de sensibilidad de manera interactiva y profesional. 5. Automatización del análisis Scripts que ejecutan múltiples escenarios automáticamente. Generación de resultados consolidados en DataFrames y dashboards. Integración con reportes y visualizaciones para facilitar interpretación por equipos y stakeholders. La automatización asegura eficiencia, consistencia y rapidez en el análisis. 6. Visualización de resultados Gráficos de líneas, dispersión y barras para comparar escenarios. Dashboards interactivos que muestran impactos de cambios en variables clave. Resaltado de resultados críticos y alertas de desviación mediante visualizaciones dinámicas. Esto facilita la comprensión rápida y clara de los efectos de cada variable. 7. Aplicaciones prácticas Ingeniería civil: evaluación de impactos de variaciones en costos, materiales y plazos. Ingeniería mecánica y eléctrica: análisis de tolerancias, cargas y rendimiento de sistemas. Procesos industriales: simulación de producción, recursos y mantenimiento predictivo. Ciencia de datos: proyección de escenarios futuros y análisis de riesgos en modelos predictivos. Esto muestra que el análisis de sensibilidad y escenarios es aplicable en múltiples disciplinas y contextos estratégicos. 8. Beneficios estratégicos Anticipación de riesgos y desviaciones antes de que ocurran. Mejora en la toma de decisiones basada en escenarios realistas. Optimización de recursos y planificación proactiva. Reducción de errores y retrabajos mediante análisis cuantitativo confiable. Incremento de eficiencia y competitividad organizacional. 9. Desarrollo de habilidades clave Los participantes adquieren competencias para: Diseñar y ejecutar análisis de sensibilidad y escenarios complejos. Automatizar la generación y comparación de múltiples escenarios. Visualizar resultados de manera clara y profesional para comunicación estratégica. Integrar análisis de escenarios con modelos predictivos y dashboards interactivos. Estas habilidades fortalecen la capacidad de anticipación, planificación y gestión de riesgos en proyectos complejos. 10. Conclusión Aplicar análisis de sensibilidad y escenarios en Python permite a los profesionales evaluar el impacto de variables críticas, anticipar problemas y optimizar decisiones estratégicas. Un curso avanzado enseña a estructurar, automatizar y visualizar estos análisis, asegurando que los equipos puedan trabajar con información confiable y tomar decisiones basadas en datos cuantitativos, fortaleciendo la eficiencia y competitividad en proyectos de ingeniería, ciencia y análisis industrial.
¿Qué impacto tiene la formación en Python en la reducción de errores en análisis de datos?
En proyectos de ingeniería, ciencia y análisis industrial, los errores en el manejo y procesamiento de datos pueden generar decisiones equivocadas, costos adicionales y riesgos operativos significativos. La formación avanzada en Python permite a los profesionales desarrollar competencias técnicas, metodológicas y estratégicas que minimizan estos errores, garantizando que los análisis sean precisos, confiables y reproducibles. A continuación, se detalla cómo la capacitación en Python impacta en la reducción de errores de análisis de datos. 1. Estandarización y control de procesos Enseña buenas prácticas para estructurar scripts, notebooks y flujos de trabajo. Aplicación de funciones y procedimientos reproducibles para cada análisis. Consistencia en la manipulación y transformación de datos a lo largo de múltiples proyectos. Esto asegura que los análisis sean coherentes y menos propensos a errores humanos. 2. Automatización de tareas repetitivas Scripts que ejecutan limpieza, transformación y consolidación de datos automáticamente. Generación de reportes y dashboards dinámicos sin intervención manual. Reducción de errores por transcripción, duplicación o mal manejo de información. La automatización incrementa la eficiencia y confiabilidad de los procesos de análisis. 3. Validación y control de calidad de datos Uso de Python para identificar valores faltantes, inconsistentes o duplicados. Implementación de verificaciones automáticas en flujos de trabajo. Creación de alertas y reportes de inconsistencias antes de ejecutar análisis. Esto garantiza que los modelos y resultados se basen en información confiable y precisa. 4. Reproducibilidad y documentación Documentación clara de pasos, fórmulas y transformaciones aplicadas a los datos. Capacidad de reproducir análisis para auditorías o revisiones técnicas. Seguimiento de cambios y control de versiones en scripts y notebooks. La reproducibilidad reduce errores derivados de inconsistencias o modificaciones no controladas. 5. Análisis predictivo y modelado robusto Preparación de datasets limpios y consistentes para machine learning. Validación de modelos predictivos con datos de prueba y métricas precisas. Reducción de sesgos y errores en predicciones mediante técnicas de control estadístico. Esto fortalece la precisión y confiabilidad de las decisiones basadas en datos. 6. Manejo de grandes volúmenes de datos Librerías optimizadas como Pandas, NumPy y Dask permiten procesar datasets extensos sin pérdida de precisión. Reducción de errores por limitaciones de herramientas tradicionales o manipulación manual. Eficiencia en el procesamiento y consolidación de información compleja. Esto asegura que los análisis sean eficientes y precisos, incluso en proyectos de gran escala. 7. Visualización y comunicación confiable Creación de gráficos, dashboards y reportes claros y estandarizados. Identificación rápida de anomalías o desviaciones en los datos. Presentación profesional de resultados que minimiza interpretaciones incorrectas. La visualización confiable reduce errores de interpretación y mejora la toma de decisiones. 8. Beneficios estratégicos Disminución de errores críticos que afectan costos, tiempos y calidad. Mayor confiabilidad en reportes, modelos y simulaciones. Optimización de recursos al reducir retrabajos. Mejora en la toma de decisiones basada en datos precisos. Incremento de la eficiencia y competitividad de la organización. 9. Desarrollo de habilidades clave Los participantes adquieren competencias para: Automatizar y estandarizar procesos de análisis de datos. Validar, limpiar y consolidar datasets de manera profesional. Generar reportes, dashboards y análisis reproducibles. Aplicar técnicas predictivas y modelado de tendencias confiables. Estas habilidades fortalecen la eficiencia, precisión y capacidad estratégica del equipo. 10. Conclusión La formación avanzada en Python tiene un impacto directo y significativo en la reducción de errores en análisis de datos. Al enseñar automatización, validación, limpieza y estandarización de procesos, los profesionales adquieren herramientas para garantizar que los resultados sean precisos, reproducibles y confiables. Esto no solo mejora la eficiencia operativa, sino que también reduce riesgos, optimiza recursos y fortalece la toma de decisiones estratégicas, convirtiendo Python en una herramienta crítica para proyectos de ingeniería, ciencia y análisis industrial. 🧾 Resumen Ejecutivo En la actualidad, la capacidad de procesar, analizar y comunicar información compleja es esencial para la eficiencia, precisión y competitividad en proyectos de ingeniería, ciencia y análisis industrial. Un curso avanzado de Python para datos proporciona a los profesionales herramientas, técnicas y competencias estratégicas que permiten transformar grandes volúmenes de información en insights confiables para la toma de decisiones. El análisis de las 10 preguntas seleccionadas revela cómo estas habilidades impactan directamente en la eficiencia, calidad y valor de los proyectos. 1. Mejora de la eficiencia en el análisis de datos Automatización de procesos repetitivos de limpieza y transformación de datos. Integración de información proveniente de Excel, SQL, APIs y otras fuentes. Procesamiento rápido y eficiente de grandes volúmenes de datos. Esto permite a los equipos ahorrar tiempo, reducir errores y centrarse en análisis estratégicos. 2. Desarrollo de competencias avanzadas Los participantes adquieren habilidades integrales: Manipulación avanzada de datos con Pandas y NumPy. Visualización y dashboards interactivos con Plotly, Dash y Seaborn. Aplicación de técnicas de análisis predictivo y machine learning con scikit-learn. Estas competencias permiten trabajar de manera más profesional, estratégica y confiable. 3. Procesamiento y limpieza de grandes volúmenes de datos Identificación y corrección de valores faltantes o inconsistentes. Normalización y transformación de variables para análisis coherentes. Automatización de flujos de trabajo para consolidación y preparación de datasets. Esto asegura que los análisis sean precisos, reproducibles y listos para modelado. 4. Integración con otras herramientas Conexión con Excel, bases de datos SQL y APIs externas. Consolidación y transformación de datos de múltiples fuentes en un único flujo de trabajo. Actualización automática de dashboards y reportes basados en datos nuevos. Esto fortalece la eficiencia, confiabilidad y consistencia de la información. 5. Automatización de procesos analíticos Reducción de intervención manual y errores humanos. Generación automática de reportes, dashboards y análisis periódicos. Estandarización de procesos para replicabilidad en múltiples proyectos. La automatización incrementa la productividad y la calidad de los resultados. 6. Análisis predictivo y modelado de tendencias Construcción de modelos para anticipar resultados futuros y proyecciones. Identificación de patrones, tendencias y variables críticas en los datos. Simulación de escenarios “what-if” para planificación y toma de decisiones estratégicas. Esto permite a los equipos anticipar problemas y optimizar recursos. 7. Creación de dashboards interactivos Visualización dinámica de KPIs, tendencias y alertas críticas. Integración de datos consolidados para monitoreo en tiempo real. Comunicación clara y efectiva de resultados a stakeholders. Los dashboards mejoran la interpretación de información compleja y la toma de decisiones. 8. Aplicación de análisis de sensibilidad y escenarios Evaluación de cómo cambios en variables críticas afectan resultados. Comparación de escenarios optimistas, pesimistas y base. Identificación de riesgos y priorización de acciones estratégicas. Esto fortalece la planificación proactiva y la gestión de riesgos. 9. Reducción de errores y mejora en la calidad de datos Implementación de validación, control de calidad y limpieza de información. Reproducibilidad y documentación de flujos de análisis. Menor probabilidad de errores humanos y resultados más confiables. Esto incrementa la confiabilidad de los análisis y la seguridad de las decisiones. 10. Beneficios estratégicos para la organización Optimización de recursos y eficiencia operativa. Incremento de productividad y reducción de retrabajos. Mayor capacidad de anticipación, planificación y toma de decisiones basada en datos. Mejora en la comunicación, colaboración y profesionalismo del equipo. Incremento de competitividad e innovación a nivel organizacional. Conclusión Un curso online avanzado de Python para datos transforma la gestión de información y el análisis de datos complejos. Las competencias adquiridas permiten automatizar procesos, integrar múltiples fuentes de datos, realizar análisis predictivos, construir dashboards interactivos y garantizar la confiabilidad de los resultados. Esto fortalece la eficiencia, precisión y capacidad estratégica de los equipos, mejorando la competitividad, productividad y calidad de los proyectos en ingeniería, ciencia y análisis industrial.